目標讀者
想徹底弄懂 split / rsplit / partition / rpartition
處理複雜標題、章節編號(例如文件 Heading:1.2.3 目的說明)
需要在「效能」「可控性」「語意清晰」之間做技術取捨
想建立一套可擴充的 parsing 策略
- 為什麼不只有一個 split?
Python 給你多種切割方式,原因是情境不同:
從左取前綴 vs 從右取尾巴
是否需要保留分隔符資訊
是否只想切一次(避免多餘切割)
是否要處理“任意空白” vs “精確字元”
- 四大核心 API 心智圖
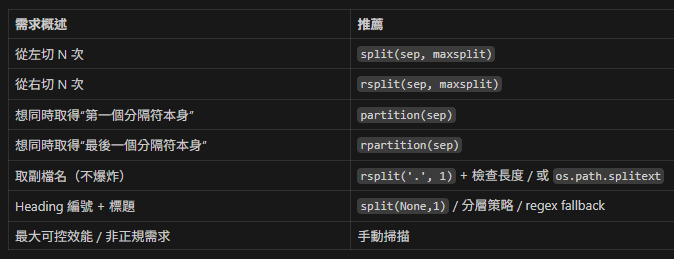
- split 與 rsplit 參數語義
語法:str.split(sep=None, maxsplit=-1) / str.rsplit(sep=None, maxsplit=-1)
sep=None:啟用「空白語意」
連續空白視為一個分隔
忽略字串開頭與結尾的空白
分隔符不包含在結果中
sep=’ ‘(顯式):
不會忽略開頭/結尾空格
連續空格會產生空字串 token
範例:
" A B C ".split() # ['A', 'B', 'C']
" A B C ".split(' ') # ['', '', 'A', '', '', 'B', '', 'C', '']4. split vs rsplit 直觀對比
s = "A B C D"
s.split(None, 1) # ['A', 'B C D']
s.rsplit(None, 1) # ['A B C', 'D']輸出:
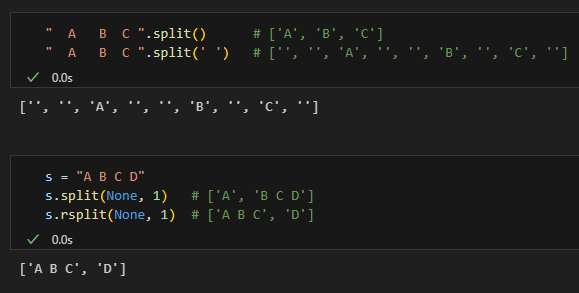
方向差異只在決定“保留哪一側的大塊”。你想像字串被切一刀:
split(…,1):第一刀鎖定第一個分隔出現
rsplit(…,1):第一刀鎖定最後一個分隔出現
- partition / rpartition 何時更好?
語法:str.partition(sep) → 永遠回 3 段 (left, sep, right)
好處:
無需檢查長度
保留分隔符
精確匹配,無「空白語意」模式
例:
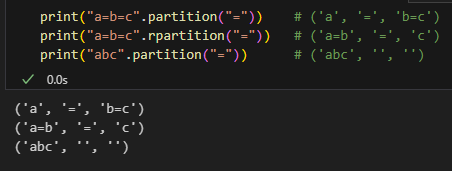
# %%
print("a=b=c".partition("=")) # ('a', '=', 'b=c')
print("a=b=c".rpartition("=")) # ('a=b', '=', 'c')
print("abc".partition("=")) # ('abc', '', '')輸出:
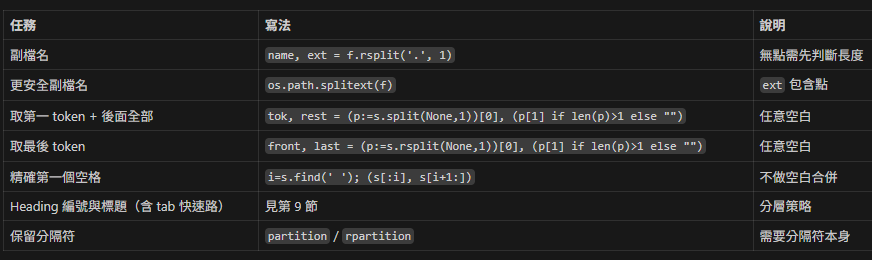
6. 常見任務與推薦寫法
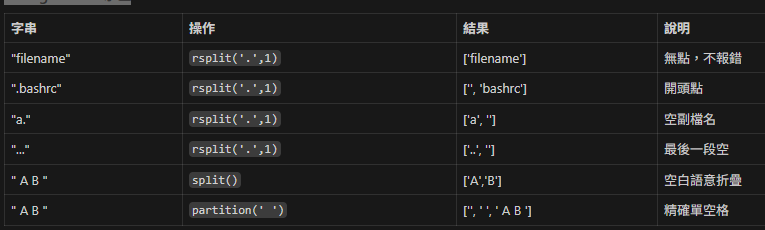
7. Edge Case 專區
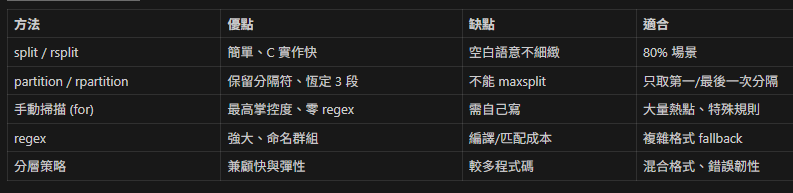
8. 效能 & 策略取捨
9. Heading 編號解析:建議分層策略
目標:”1.2.3 系統目的” → 編號 = 1.2.3,標題 = 系統目的
也可能遇到:
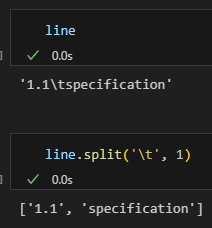
有 tab:”2.4\t測試範圍”
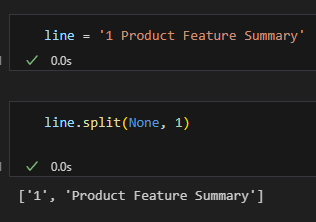
無編號:”前言”
混合符號:”A-1-3 子件說明”,”(A)(1)(b) 功能”
推薦流程:
Tab 快速路:
普通空白一次切:
常見陷阱
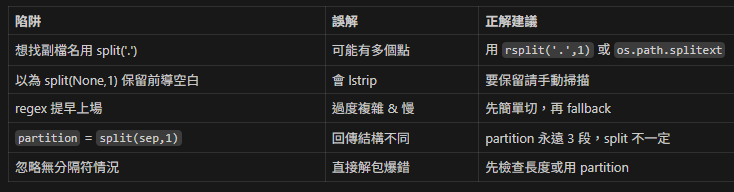
決策小抄(流程樹)
頻繁熱路徑 + 高性能 → 手動掃描 + 預編譯 regex fallback
只要第一段 / 後面全部?
從左:split(None,1)
從右:rsplit(None,1)
要保留分隔符?→ partition / rpartition
分隔字串必為單一 char 且只取一次?→ partition
混合格式或需回退?→ 分層:tab → 快速 split → 驗證 → regex
需要索引/保留空白 → 手動掃描
總結口訣
- “左切用 split,右切用 rsplit”
- “只切一次記得 maxsplit=1”
- “要分隔符用 partition/rpartition”
- “格式簡單不用 regex”
- “Heading 解析分層:Tab→快速→驗證→Regex”
- “性能敏感:手動掃描 + 預編譯 regex fallback”
推薦hahow線上學習python: https://igrape.net/30afN
: value for key, value in kwargs.items()}")
![Python: matplotlib繪製出的圖表如何插入背景圖? img = plt.imread(‘background_image.png’) ; ax.imshow(img, extent=[0, 10, -1.2, 1.2], aspect=’auto’, alpha=0.5)](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2023/02/20230216183536_29.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: matplotlib繪製出的圖表如何插入背景圖? img = plt.imread(‘background_image.png’) ; ax.imshow(img, extent=[0, 10, -1.2, 1.2], aspect=’auto’, alpha=0.5)")

, isdigit()")

,阿拉伯數字改為國字")

, 如何繪製3D散佈圖? spyder無法用滑鼠改變3D圖的視角該如何處理? %matplotlib qt")
")

近期留言