在處理 XML 或 HTML 字串時,
我們常需要從 這樣的結構中提取特定的值。
這篇文章將以「抓取 XML 中的 rId」為例,
帶你徹底搞懂 Python re 模組的關鍵用法。
- 任務目標
假設我們有一段 XML 字串,裡面混雜了各種屬性,
我們的目標是只抓出 rId 的編號(例如 rId5, rId6)。
xml_text = """
<w:document>
<w:p>
<w:hyperlink r:id="rId5">Google</w:hyperlink>
<a:blip r:embed="rId6" />
<a:blip r:link="rId7" />
<w:other attr="ignore_me" />
</w:p>
</w:document>
"""我們想抓到的結果是:['rId5', 'rId6', 'rId7']。
2. findall vs finditer:記憶體與效能的抉擇
這兩個函數都是用來「找出所有符合的結果」,但運作方式不同。
re.findall(pattern, string)
- 行為:一次掃描整串文字,把所有結果存成一個 List 回傳。
- 優點:簡單直觀,直接拿到清單。
- 缺點:如果 xml_text 非常巨大(例如 100MB),
它會一次佔用大量記憶體來存結果。
# %%
import re
# 簡單粗暴,直接拿 List
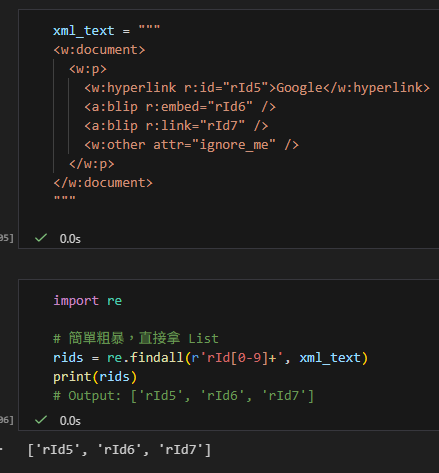
rids = re.findall(r'rId[0-9]+', xml_text)
print(rids)
# Output: ['rId5', 'rId6', 'rId7']輸出:
re.finditer(pattern, string) (推薦用於大檔案)
行為:回傳一個 Iterator (迭代器)。
它不會一次做完,而是你用 for 迴圈跑一次,
它才去找下一個(Lazy Evaluation)。
優點:極省記憶體。適合處理大型 XML。
缺點:回傳的是 Match Object,
需要多一步 .group() 才能拿到字串。
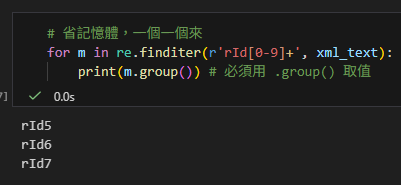
import re
# 簡單粗暴,直接拿 List
rids = re.findall(r'rId[0-9]+', xml_text)
print(rids)
# Output: ['rId5', 'rId6', 'rId7']輸出:
- Group 的奧義:精準定位
在複雜的 XML 中,單純搜 rId[0-9]+ 可能會誤抓
(例如內文剛好有 “rId5” 這個字)。
我們通常會加上前綴條件(例如必須是 r:embed=”…”)。
這時候就需要用到 Group (群組)。
什麼是 Group?
在 Regex 中,用小括號 () 包起來的部分就是一個 Group。
範例模式:r’r:embed=”(rId[0-9]+)”‘
Group 0 (完整匹配):代表 Regex 抓到的整個字串。
m.group(0) -> ‘r:embed=”rId6″‘ (包含屬性名和引號,髒資料)
Group 1 (捕獲群組):代表第一個括號 (…) 裡的內容。
m.group(1) -> ‘rId6’ (乾淨的 ID,這才是我們要的!)
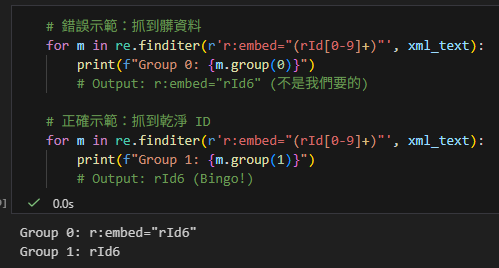
# 錯誤示範:抓到髒資料
for m in re.finditer(r'r:embed="(rId[0-9]+)"', xml_text):
print(f"Group 0: {m.group(0)}")
# Output: r:embed="rId6" (不是我們要的)
# 正確示範:抓到乾淨 ID
for m in re.finditer(r'r:embed="(rId[0-9]+)"', xml_text):
print(f"Group 1: {m.group(1)}")
# Output: rId6 (Bingo!)輸出:
- 非捕獲群組 (?:…):只比對,不佔位
有時候我們想比對多種屬性名(r:embed 或 r:link 或 r:id),
但我們不想把這些屬性名存進 Group 裡(因為我們只關心後面的 ID)。
這時候就用 (?:…)。
模式:r'(?:r:embed|r:link|r:id)=”(rId[0-9]+)”‘
解析:
(?:r:embed|r:link|r:id):這是 非捕獲群組。
它負責比對「屬性名必須是這三個之一」,但不會變成 Group 1。
=”(rId[0-9]+)”:這是 捕獲群組。
因為前面的括號被標記為「非捕獲」,
所以這個括號順理成章成為 Group 1。
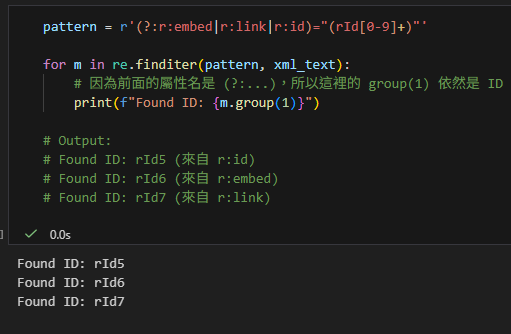
pattern = r'(?:r:embed|r:link|r:id)="(rId[0-9]+)"'
for m in re.finditer(pattern, xml_text):
# 因為前面的屬性名是 (?:...),所以這裡的 group(1) 依然是 ID
print(f"Found ID: {m.group(1)}")
# Output:
# Found ID: rId5 (來自 r:id)
# Found ID: rId6 (來自 r:embed)
# Found ID: rId7 (來自 r:link)輸出:
總結
大檔案處理:優先使用 re.finditer,避免記憶體爆炸。
精準抓取:使用 () 建立捕獲群組,並用 m.group(1) 提取乾淨資料。
多條件比對:使用 (?:A|B) 非捕獲群組來處理前綴,
確保 group(1) 永遠是你想要的那個值。
推薦hahow線上學習python: https://igrape.net/30afN
? from tkinter import Tk, Button, filedialog ; 物件導向避免使用全域變數 ; pandas.read_csv(fpath, skip_blank_lines = True) 可以濾掉空列,Tab , 不定數空白")
 打造不死文檔; from docx.oxml import OxmlElement")



?如何使用jieba做中文斷詞? lis_jieba = jieba.lcut(strr)")
![Python: 如何使用functools.reduce逐步縮減可迭代對象,合併為單個結果? import functools; product = functools.reduce( lambda x, y: x * y, numbers) ; reduce(function, sequence [, initial]) -> value ; map(function, iterable) ; filter(function, iterable) ; map ; filter](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2023/06/20230626093403_49.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: 如何使用functools.reduce逐步縮減可迭代對象,合併為單個結果? import functools; product = functools.reduce( lambda x, y: x * y, numbers) ; reduce(function, sequence [, initial]) -> value ; map(function, iterable) ; filter(function, iterable) ; map ; filter")
![Python:如何將folder_path & file_name合併為file_path? fpath = os.path.join (folder , fname) #不需要[ ]包覆folder,fname; fpath1 = “\\”.join( [folder , fname] ) #需要[ ] 包覆folder,fname ; 反過來講,file_path如何拆分為folder_path & file_name? os.path.dirname() ; os.path.basename() ; file_name如何拆分為主檔名與副檔名os.path.splitext() #split(分裂) ext](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2023/07/20230717184401_87.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python:如何將folder_path & file_name合併為file_path? fpath = os.path.join (folder , fname) #不需要[ ]包覆folder,fname; fpath1 = “\\”.join( [folder , fname] ) #需要[ ] 包覆folder,fname ; 反過來講,file_path如何拆分為folder_path & file_name? os.path.dirname() ; os.path.basename() ; file_name如何拆分為主檔名與副檔名os.path.splitext() #split(分裂) ext")

![Python: 字串 str.find(關鍵字[,start][,end]),找不到的話回傳-1,如何找出資料字串中,所有關鍵字的index?詞頻計算 - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/11/20221122100657_32-520x245.png)

近期留言