import pandas as pd
f3 = r”C:\Python\example\csvreader\skl_cashFlowIRR2.xlsx”
df3 = pd.read_excel(f3) ;
print( df3,”\n”,type(df3) ) #DataFrame
print( df3[“Cash Flow 1″],”\n”,type(df3[“Cash Flow 1”])) #Series
print( list(df3[“Cash Flow 1”]) )
#取得到這個list,
#就可以用numpy_financial.irr()計算內部報酬率
![Python如何讀取excel檔(.xlsx)?如何用欄標籤提取某一直行?df=pandas.read_excel() ; df["欄標籤"] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/11/20221109163631_39.png)
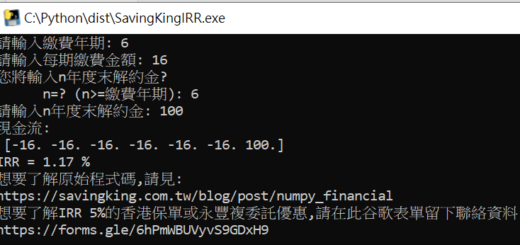
輸出:
![Python如何讀取excel檔(.xlsx)?如何用欄標籤提取某一直行?df=pandas.read_excel() ; df["欄標籤"] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/11/20221109163816_19.png)
 as plt; from pylab import *")
 的 maxsplit 速懂教學(含常見陷阱與實用對比);如何分割標題號 與 標題文字? “3.1.2 Test Strategy”.split(maxsplit=1) #注意中間無底線: 非max_split")
, x)` ; sorted(items, key=lambda x: (-len(x), x)) 與 json_repair strategy pipeline")
")
 駝峰切詞與特例保護教學; (?i: … ):不分大小寫的非捕獲群組")
 as f: json_str = f.read() ; jsn = json.loads(json_str)")
; hash_obj = hashlib.sha256(data); result = hash_obj.hexdigest() #digest:「取得雜湊摘要」或「取得摘要值」")
![Python TQC考題910 學生基本資料, print(line.decode(“utf-8”)), if line.decode(“utf-8″).split()[2] ==”0”: female += 1](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2022/05/20220514163621_72.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python TQC考題910 學生基本資料, print(line.decode(“utf-8”)), if line.decode(“utf-8″).split()[2] ==”0”: female += 1")
: value for key, value in kwargs.items()}")

近期留言