# 超越傳統 OCR:使用 Ollama + MiniCPM-V 打造精準 AI 視覺辨識引擎
傳統的 OCR (如 Tesseract) 雖然能辨識文字,但面對複雜排版、程式碼截圖或表格時往往力不從心。
**MiniCPM-V** 是一款強大的多模態語言模型 (LMM),不僅能「讀字」,更能「理解」圖片內容,並且可以在本地端透過 **Ollama** 輕鬆運行。
這篇教學將帶您從零開始,使用 Ollama 部署 MiniCPM-V,並透過 Python 實現高品質的 OCR 自動化。
—
## 為什麼選擇 MiniCPM-V?
1. **多模態理解**:它不是單純的「圖片轉文字」,而是用 LLM 的大腦去理解圖片。
2. **抗幻覺能力**:相比一般 LLM,MiniCPM-V 在 OCR 任務上針對「文字精準度」有特別優化。
3. **本地運行**:資料不出門,資安有保障(特別適合處理機密文件或程式碼截圖)。
4. **低資源需求**:透過 Ollama 量化技術,消費級顯卡甚至 CPU 即可運行。
—
## 步驟 1:環境準備
首先,請確保您已安裝 [Ollama](https://ollama.com/)。
### 下載模型
打開終端機 (PowerShell / CMD / Terminal),執行:
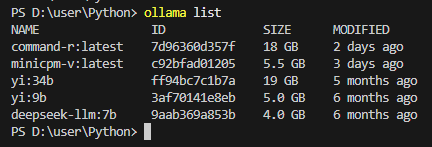
ollama pull minicpm-v> **注意**:模型大小約 5.5 GB,第一次下載需稍候。
若需指定下載路徑,請先設定環境變數 `OLLAMA_MODELS`。
—
## 步驟 2:快速測試 (CLI)
在開始寫程式之前,先用指令確認模型運作正常。
> 補充:目前版本的 Ollama CLI(例如 `ollama version is 0.13.x`)的 `ollama run` 已經沒有提供 `–image` 旗標,
> 因此「用 CLI 丟圖片」這條路在新版本不適用。要測試視覺/OCR,請改用下方的 HTTP API 測試(或直接跳到步驟 3 的 Python 範本)。
**先做文字模式測試(確認模型可跑):**
ollama run minicpm-v "請回覆:OK"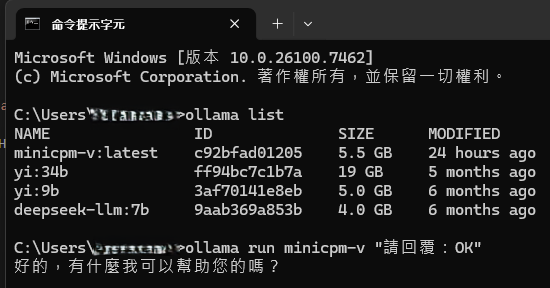
**再做視覺/OCR 測試(用 API,最短可用版):**
python -c "import base64,requests; p=r'C:\path\to\test_image.jpg'; b=base64.b64encode(open(p,'rb').read()).decode('utf-8'); data={'model':'minicpm-v','prompt':'請逐字轉寫圖片中的文字,只輸出辨識結果','images':[b],'stream':False,'options':{'temperature':0.0,'top_p':1.0}}; r=requests.post('http://localhost:11434/api/generate', json=data, timeout=300); r.raise_for_status(); print(r.json().get('response',''))"> 若尚未安裝 requests,先執行:`pip install requests`
(不想安裝套件也可以用標準庫 urllib 版本)
python -c "import base64,json,urllib.request; p=r'C:\path\to\test_image.jpg'; b=base64.b64encode(open(p,'rb').read()).decode('utf-8'); data={'model':'minicpm-v','prompt':'請逐字轉寫圖片中的文字,只輸出辨識結果','images':[b],'stream':False,'options':{'temperature':0.0,'top_p':1.0}}; req=urllib.request.Request('http://localhost:11434/api/generate', data=json.dumps(data).encode('utf-8'), headers={'Content-Type':'application/json'}); print(json.loads(urllib.request.urlopen(req).read().decode('utf-8')).get('response',''))"如果能回傳圖片內容,代表環境已就緒。
## 步驟 3:Python 自動化 OCR (透過 API)
雖然 CLI 很好用,但要整合進工作流 (如 Word 自動化處理),我們需要使用 API。Ollama 提供了非常方便的 HTTP API。
以下是 **標準 Python 實作範本**(需安裝 `requests`:`pip install requests`;不需要安裝 Ollama 額外 SDK/Python client,但需確保 Ollama 服務已在背景運行,例如先執行 `ollama serve` 或啟動 Ollama App):
import base64
import json
import requests
import time
def ocr_with_minicpm(image_path):
# 1. 讀取圖片並轉為 Base64
with open(image_path, "rb") as img_file:
image_bytes = img_file.read()
# [變數1: image_bytes] 型別是 bytes。這是圖片的「原始二進位數據」(Raw Binary),
# 內容包含像 \x89PNG... 這種亂碼符號,這完全無法被 JSON 接受。
# [變數2: base64.b64encode(image_bytes)] 回傳的型別「依然是 bytes」。
# 但它的內容已經變成了「ASCII 可見字符的 bytes representation」(如 b'aGVsbG8=')。
# 重點:雖然它是 bytes 型別,但內容只剩下安全的英數字、+、/、=。
# [最終步驟: .decode('utf-8')]
# 因為 JSON 格式只接受「字串 (String)」不接受「Bytes」。
# 所以我們把那個「只含 ASCII 的 bytes」透過 decode 轉成真正的 Python String。
base64_str = base64.b64encode(image_bytes).decode('utf-8')
# 2. 設定「高精度 OCR」提示詞 (Prompt Engineering)
# 關鍵:使用 "Strict Mode" 提示詞來抑制 AI 幻覺
prompt = """
你是一個「程式碼 OCR 引擎」。
請逐字轉寫圖片中的程式碼內容。
【禁止事項】
- 禁止修改任何 key 名稱(即使你認為是拼錯)
- 禁止改變 value 型別(string / number / array / object)
- 禁止把花括號/方括號互換:禁止將 {} 改成 [],也禁止將 [] 改成 {}
- 禁止替換任何括號符號:()、{}、[]、<> 必須逐字逐符號原樣保留
- 禁止補齊缺失欄位
- 禁止重新排列 key 順序
- 禁止輸出合法 JSON(即使結果不合法也要如實輸出)
- 禁止翻譯,如:英文翻譯為中文
【不確定處理】
- 單一字元不確定 → ?
- 整個欄位不確定 → [UNCLEAR]
- 被截斷 → …
【輸出】
- 僅輸出 OCR 文字
- 保留所有標點與符號(包含 {}, [], (), <>, : , ' " 以及空白/縮排)
- 不要使用 Markdown
- 不要加任何說明
"""
# 3. 構造請求 Payload
data = {
"model": "minicpm-v",
"prompt": prompt,
"images": [base64_str],
"stream": False, # 一次性回傳,方便處理
# 生成參數(可選):OCR 建議把 temperature 調低,降低「腦補」機率
# 常用範圍:0.0 ~ 0.2(越低越保守、越不發散)
# top_p(nucleus sampling / 核取樣):只從「累積機率前 top_p」的 token 集合中抽樣
# 直覺上也會影響發散程度:top_p 越小越保守;top_p=1.0 通常等於不裁切(保留完整分佈)
# OCR/逐字轉寫建議:temperature 低、top_p 取 0.9~1.0(常用 1.0)
"options": {
"temperature": 0.0,
"top_p": 1.0,
},
}
# 4. 發送請求給 Ollama
print("正在傳送圖片給 AI 進行辨識...")
start = time.time()
try:
# requests 版本(推薦):更精簡,且提供 json=payload 的便利寫法
# 安裝:pip install requests
#
# json=data 的等效寫法如下(手動序列化 JSON):
# resp = requests.post(
# "http://localhost:11434/api/generate",
# data=json.dumps(data).encode("utf-8"),
# headers={"Content-Type": "application/json"},
# timeout=300,
# )
resp = requests.post(
"http://localhost:11434/api/generate",
json=data,
timeout=300,
)
# 如果 HTTP 狀態碼不是 2xx(例如 400/401/404/500),就立刻丟出 HTTPError 例外。
# 好處:不要在「請求其實失敗」的情況下繼續呼叫 resp.json(),避免得到更難讀的解析錯誤。
# 你也可以用 resp.status_code 查看狀態碼;
# raise_for_status() 等同於幫你做了這個檢查並統一報錯。
resp.raise_for_status()
result = resp.json()
text = result.get("response", "").strip()
print(f"辨識完成!耗時: {time.time() - start:.2f} 秒")
return text
except Exception as e:
return f"[Error] {e}"
# (可選)urllib 版本:不依賴 requests(標準庫)
# import urllib.request
#
# req = urllib.request.Request(
# "http://localhost:11434/api/generate",
# # data= 是 HTTP request body,urllib 要求它是 bytes
# # 這裡的流程是:Python dict -> JSON 字串 -> UTF-8 bytes,才能送到網路上
# data=json.dumps(data).encode("utf-8"),
# # Content-Type 用來告訴伺服器:「我送的是 JSON」
# # 沒有這個 header 有時伺服器會用錯誤方式解析 body(導致 400/解析失敗)
# headers={"Content-Type": "application/json"},
# )
# with urllib.request.urlopen(req) as response:
# result = json.loads(response.read().decode("utf-8"))
# text = result.get("response", "").strip()
# return text
# 使用範例
if __name__ == "__main__":
result = ocr_with_minicpm("my_screenshot.png")
print("-" * 30)
print(result)
print("-" * 30)## 步驟 4:進階技巧 – 避免 AI 幻覺
使用 LLM 做 OCR 最大的風險是「腦補」(Hallucination)。例如它可能會幫您「修正」程式碼中的 Bug,或幫您「翻譯」英文註解。但在 OCR 任務中,我們要的是**忠實還原**。
### 推薦 Prompt (提示詞) 策略:
1. **角色設定**:`ACT AS A STRICT OCR ENGINE` (你是一個嚴格的 OCR 引擎)。
2. **逐字轉寫**:關鍵字 `Verbatim` (逐字)、`Transcribe` (轉寫)。
3. **禁止行為**:`DO NOT fix syntax`, `DO NOT summarize`。
4. **特殊符號保留**:針對 JSON 或 Python 截圖,強調 `Preserve whitespace & punctuation`。
### 常見問題:把 `{}` 認成 `[]`
這是視覺模型在「符號辨識」上的常見錯誤,尤其在解析度低、字小、對比不足或括號很靠近時更容易發生。
**改善建議:**
1. **先調參數,再調提示詞**
– `temperature` 建議維持 `0.0 ~ 0.2`(越低越不會亂猜)
– `top_p` 建議 `0.9 ~ 1.0`(太低可能會把低頻符號擠掉,反而更容易選錯括號)
2. **提示詞明確禁止括號互換**
– 加上「禁止將 `{}` 改成 `[]`」的規則(上面的 Strict prompt 已包含)
– 要求「不確定就輸出 `?`」比「猜一個括號」更安全
3. **提高圖片品質**
– 優先用原始截圖,不要再壓縮/轉傳造成模糊
– 盡量裁切到只剩程式碼/JSON 區塊,放大字體與對比
### 結果標記 (Isolation)
為了讓後續程式 (或 RAG 系統) 能區分哪些是 AI 產生的 OCR,建議將結果包裹在標籤中:
return f"<ai_ocr_result model='minicpm-v'>{text}</ai_ocr_result>"這樣無論您將結果插入 Word 還是存入資料庫,都可以透過 Regex 輕鬆分離。
—
## 總結
透過 **Ollama + MiniCPM-V**,我們不再受限於傳統 OCR 對模糊圖片或特殊排版的無力。雖然速度上比輕量級 OCR (如 Tesseract) 慢,但其帶來的**語意理解能力**與**結構還原能力**,對於高品質的文檔數位化工程來說,是極具價值的投資。
推薦hahow線上學習python: https://igrape.net/30afN
![Python Pandas GroupBy 的 size 陷阱:為什麼你的計數結果總是不對?如何計算重複次數? duplicates = df.duplicated( subset = [‘name’] )](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2025/06/20250609143758_0_53821c.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python Pandas GroupBy 的 size 陷阱:為什麼你的計數結果總是不對?如何計算重複次數? duplicates = df.duplicated( subset = [‘name’] )")
 正向前瞻 (Positive Lookahead) ; (?!…) 負向前瞻 (Negative Lookahead) ; (?<=…) 正向回顧 (Positive Lookbehind) ; (?<!…) 負向回顧 (Negative Lookbehind) ; re.sub() ; re.split()")

將 JSON 逐筆自動轉成中文自然語言")

 和 add_paragraph() 都創建段落,有何差別?")
, **dict(取value), *dict(取key)解包的差別? *第一個(不定長度)參數:打包為tuple,**最後一個(不定長度)選擇性參數:打包為dict,解包時dict的key要與參數的名稱一樣,而且不可多,不可少,解包與打包運算子")
) ; ax.annotate(text,xy,…) #註釋 ; 通用屬性 ; linestyle ;圖例 legend ; set_title()、set_xlabel()、set_ylabel() ; 網格 ax.grid(visible=None, axis=’both’, …) ; ax.set_xticks() ; ax.set_yticks()")




近期留言