df.map(func)
import pandas as pd
# 創建示例DataFrame
data = {'Name': ['John', 'Emma', 'Michael'],
'Age': [25, 30, 35],
'Salary': [50000, 70000, 90000]}
df = pd.DataFrame(data)
# 對'Salary'列進行格式化字串
df['Salary'] = df['Salary'].map('${:,.2f}'.format)
print(df)code & 輸出結果:
![Python: pandas.DataFrame 如何對某些欄做格式化字串? apply(); applymap() ; map() 的差別? df['Salary'] = df['Salary'].map( '${:,.2f}' .format) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/05/20230527091636_49.png)
對於.map('${:,.2f}'.format)這段程式碼,它是將指定的列進行格式化字串,將數值類型的數據轉換為具有貨幣格式的字串。
具體來說,.map('${:,.2f}'.format)的含義如下:
'{:,.2f}'是一個格式化字串,表示將數值格式化為浮點數,並保留兩位小數。'$'是在格式化字串中加入美元符號作為前綴,表示這是一個貨幣值。.map()是一個Pandas的方法,它將格式化字串應用於指定的列。
因此,當你使用.map('${:,.2f}'.format)時,它會將該列中的數值轉換為具有貨幣格式的字串,並在數值前加上美元符號。
在 .map('${:,.2f}'.format) 中,.format 後面沒有加上括號 () 是因為在這個上下文中,我們正在傳遞 .format 函數本身作為參數給 .map 方法。
在這個用法中,.format 是一個函數對象(function object),它被傳遞給 .map 方法作為轉換函數。.map 方法會將這個函數應用於它操作的每個元素。
當我們寫 .map('${:,.2f}'.format) 時,我們實際上是將 .format 函數傳遞給 .map 方法,而不是直接調用它。.map 方法將會在適當的時候調用這個函數,並將每個元素作為參數傳遞給它。
這種用法的好處是可以將 .format 函數與 .map 方法組合使用,而不需要使用額外的 lambda 函數或定義額外的函數。這使得代碼更簡潔和易讀。
map(func, list-type data):
![Python: pandas.DataFrame 如何對某些欄做格式化字串? apply(); applymap() ; map() 的差別? df['Salary'] = df['Salary'].map( '${:,.2f}' .format) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/05/20230527101640_93.png)
result = list(map(lambda x: “{:.2f}%”.format(x * 100), lis))
![Python: pandas.DataFrame 如何對某些欄做格式化字串? apply(); applymap() ; map() 的差別? df['Salary'] = df['Salary'].map( '${:,.2f}' .format) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/05/20230528221859_85.png)
df.applymap()
import pandas as pd
# 創建示例DataFrame
data = {'Name': ['John', 'Emma', 'Michael'],
'Age': [25, 30, 35],
'Salary': [50000, 70000, 90000]}
df = pd.DataFrame(data)
# 對整個DataFrame進行格式化字串
df_formatted = df.applymap(lambda x: '${:,.2f}'.format(x) if isinstance(x, (int, float)) else x)
print(df_formatted)code & 輸出結果:
![Python: pandas.DataFrame 如何對某些欄做格式化字串? apply(); applymap() ; map() 的差別? df['Salary'] = df['Salary'].map( '${:,.2f}' .format) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/05/20230527092511_66-1200x418.png)
.map()方法用於對Series中的每個元素進行操作,可以針對單個列進行運算。你可以將.map()應用於單個列或Series對象。.applymap()方法用於對整個 DataFrame 中的每個元素進行操作,可以針對整個 DataFrame 進行運算。你可以將.applymap()應用於整個 DataFrame。
所以,你可以使用 .map() 方法對單個column進行格式化或其他操作,而使用 .applymap() 方法對整個 DataFrame 進行格式化或其他操作。
applymap()方法存在於 pandas 套件的 DataFrame 物件中,用於對整個 DataFrame 的每個元素進行操作。apply()方法也存在於 pandas 套件的 DataFrame 物件中,用於對 DataFrame 的每一行或每一列進行操作,而不是針對單個元素
map()方法是針對 Series 物件(單個列)進行操作。您可以將一個函式應用到 Series 的每個元素,並返回一個新的 Series。
apply():apply()函數用於在DataFrame的行或列上應用自定義函數。您可以將函數應用於整個行或列,並返回一個Series或DataFrame,具體取決於應用的函數返回的結果。通常用於對DataFrame的行或列進行複雜的操作。applymap():applymap()函數用於對DataFrame中的每個元素應用自定義函數。它對DataFrame的每個元素應用函數,並返回一個新的DataFrame。通常用於對DataFrame的每個單獨元素進行操作。map():map()函數用於對Series或DataFrame中的每個元素進行元素級別的轉換。它對Series中的每個元素應用函數,並返回一個新的Series。對於DataFrame,map()函數只能應用於Series(單列),並返回一個新的Series。
總結來說,apply() 和 applymap() 主要用於對DataFrame進行操作,而 map() 主要用於對Series進行操作。它們在操作的對象和返回的結果類型上有所不同。請根據具體的需求選擇使用適當的函數
推薦hahow線上學習python: https://igrape.net/30afN
.apply() 因為是逐列或逐行操作,
所以可以使用axis參數:
![Python: pandas.DataFrame 如何對某些欄做格式化字串? apply(); applymap() ; map() 的差別? df['Salary'] = df['Salary'].map( '${:,.2f}' .format) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/05/20230527131416_92.png)
將apply()運算出來的Series,
加在最後一row
new_row = df.apply(sum, axis=0)
#用.loc[] 才可以新增一列
#.iloc[] 不行
#func=sum ,index卻用”mean” 筆誤
![Python: pandas.DataFrame 如何對某些欄做格式化字串? apply(); applymap() ; map() 的差別? df['Salary'] = df['Salary'].map( '${:,.2f}' .format) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/05/20230527141113_100.png)
df=pd.concat([df,new_row_df])
![Python: pandas.DataFrame 如何對某些欄做格式化字串? apply(); applymap() ; map() 的差別? df['Salary'] = df['Salary'].map( '${:,.2f}' .format) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/05/20230527141239_60.png)
有無使用[]
將new_row (Series) 包起來的差別:
![Python: pandas.DataFrame 如何對某些欄做格式化字串? apply(); applymap() ; map() 的差別? df['Salary'] = df['Salary'].map( '${:,.2f}' .format) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/05/20230527142120_59.png)
pd.DataFrame(new_row)
#concat這個直式的DF
#會多出很多NaN,
#不是我們想要的資料
![Python: pandas.DataFrame 如何對某些欄做格式化字串? apply(); applymap() ; map() 的差別? df['Salary'] = df['Salary'].map( '${:,.2f}' .format) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/05/20230527144233_36.png)
![Python: pandas.DataFrame 如何對某些欄做格式化字串? apply(); applymap() ; map() 的差別? df['Salary'] = df['Salary'].map( '${:,.2f}' .format) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/05/20230527144537_61.png)
推薦hahow線上學習python: https://igrape.net/30afN
,版面配置>行號>連續")
 as file: for line in file: for w in line.split()")
 #獲取時間戳; localtime = time.localtime( timestamp ) #獲取localtime; fmt= ‘%Y-%m-%d %H:%M:%S’ ; strftime = time.strftime(fmt, localtime) 等效於 datetime.datetime.now().strftime(fmt) #獲取strftime #str format time ;")
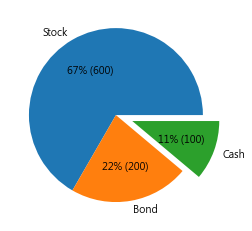
函式切片出兩個 pandas.Series 重複的元素? ser_bool = 長的Series.isin (短的Series); numpy.bool_ ; WR75 WR42 WR28頻段為何?")

")
 ,19歲奧運跆拳銅牌美少女羅嘉翎的國光獎金,應該一次領500萬?還是終身月領2.4萬?Excel財務函數PMT, RATE, NPER, PV, FV")
; ip addr ; hostname -I查詢ip address")
 套件繪製具有多個子圖的折線圖? sns.relplot(data=tips, x=’total_bill’, y=’tip’, hue=’sex’, col=’day’, row=’time’, facet_kws={‘margin_titles’: True}, height=3, aspect=1.2).set_axis_labels(‘Total Bill’, ‘Tip’)")


近期留言