在數據分析和處理過程中,識別和處理重複值是一個常見但關鍵的任務。Python 的 pandas 庫提供了強大的 duplicated() 方法來處理這類問題,而其中的 keep 參數尤其值得深入理解。本文將帶您全面了解這個參數的用法和應用場景。
keep 參數的三種模式
pandas.Series.duplicated() 方法的 keep 參數有三個可選值,每個都有不同的行為:
import pandas as pd
import numpy as np
# 創建一個包含重複值的示例 Series
s = pd.Series(['A', 'B', 'C', 'A', 'B', 'D'])1. keep=’first’(默認值)
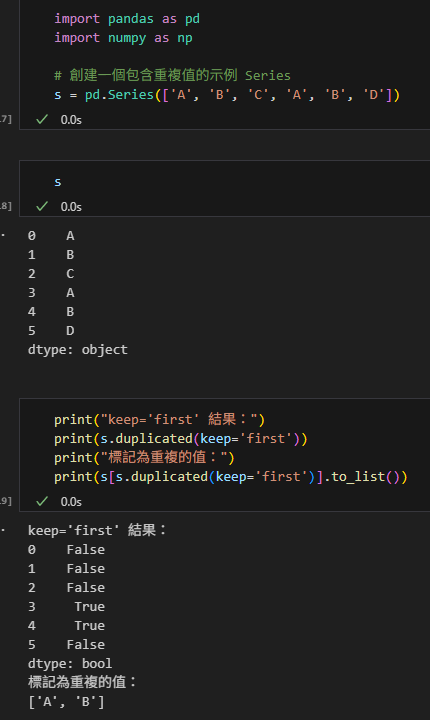
當 keep=’first’ 時,
第一次出現的值被標記為 False(未重複),
而後續重複的值被標記為 True:
print("keep='first' 結果:")
print(s.duplicated(keep='first'))
print("標記為重複的值:")
print(s[s.duplicated(keep='first')].to_list())輸出結果:
2. keep=’last’
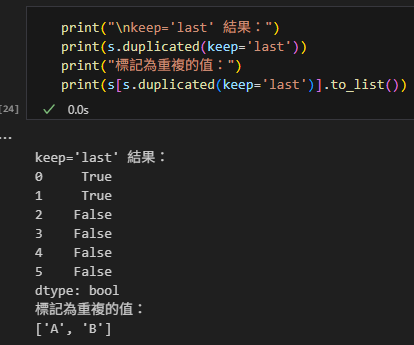
當 keep=’last’ 時,最後一次出現的值被標記為 False,而先前出現的重複值被標記為 True:
print("\nkeep='last' 結果:")
print(s.duplicated(keep='last'))
print("標記為重複的值:")
print(s[s.duplicated(keep='last')].to_list())輸出結果:
3. keep=False
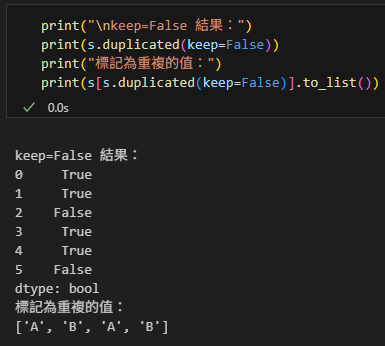
當 keep=False 時,所有重複值都被標記為 True,無論是首次還是後續出現:
print("\nkeep=False 結果:")
print(s.duplicated(keep=False))
print("標記為重複的值:")
print(s[s.duplicated(keep=False)].to_list())輸出結果:
結論
掌握 pandas 中 duplicated() 方法的 keep 參數是進行高效數據處理的關鍵。根據您的具體需求選擇合適的 keep 值,可以讓您更精確地控制如何識別和處理重複數據。
無論是進行數據清洗、自動化測試流程分析,還是識別業務邏輯中的異常模式,duplicated() 方法的靈活應用都能幫助您更好地完成任務。
通過本文的詳細說明和實例,相信您已經對 keep 參數有了全面的了解,並能在自己的項目中靈活運用這一強大工具。
推薦hahow線上學習python: https://igrape.net/30afN
 vs jieba.lcut() 使用指南")

![Python: pandas.Series如何只保留str,去除重複值?#isinstance(x:Any, str) -> bool #.drop_duplicates() #Series.apply( function )逐元素應用function運算 #DataFrame.apply( function )逐Series應用function運算 .drop_duplicates() 跟.unique()有何差別? df.drop_duplicates() 等效於 df[~df.duplicated()]](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2024/11/20241123194900_0_5218de.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: pandas.Series如何只保留str,去除重複值?#isinstance(x:Any, str) -> bool #.drop_duplicates() #Series.apply( function )逐元素應用function運算 #DataFrame.apply( function )逐Series應用function運算 .drop_duplicates() 跟.unique()有何差別? df.drop_duplicates() 等效於 df[~df.duplicated()]")

 ; axis參數如何用? numpy.max() ; numpy.min() ; numpy.argmax() #沿軸max的index; numpy.argmin() #沿軸min的index")
位置? ax.legend( bbox_to_anchor = (1, 1), borderaxespad=0)")
 切割資料(波士頓地區房價)為訓練資料跟測試資料; from sklearn.model_selection import train_test_split ; xtrain, xtest, ytrain, ytest = train_test_split(x, y, test_size=0.3, random_state=42, shuffle=True)")
的CRUD(Create創建, Read讀取, Update修改, Delete刪除)")
捕獲組, (?: … )非捕獲組, (?P … )命名捕獲組, (?= … )正向前瞻斷言, (?! … )負向前瞻斷言")


近期留言