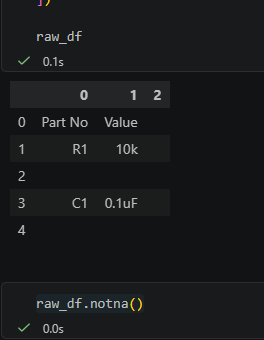
Python pandas 表格清理教學:空字串不是 pd.NA,notna() 會判斷為 True , dropna() 也刪不掉
## 1. 這篇在解決什麼問題? 這篇主要在解釋 `is_meani...
透視各家儲蓄險IRR,踢爆保險黑心貨與偽專家,看見儲蓄險的美麗與陷阱
## 1. 這篇在解決什麼問題? 這篇主要在解釋 `is_meani...
## 1. 先理解 PyMuPDF 抽出的 PDF 文字結構 在 `...
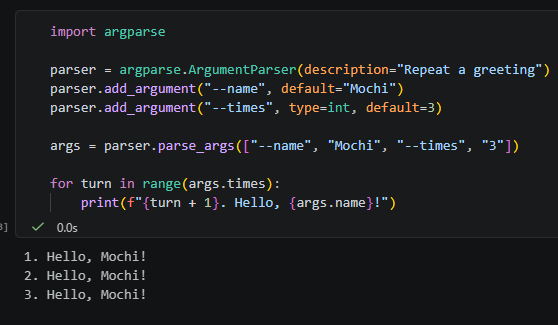
# argparse 超簡單教學:讓 Python 小工具聽懂你的指...
這篇教學要講的是一個很常混在一起的觀念: – `os.e...

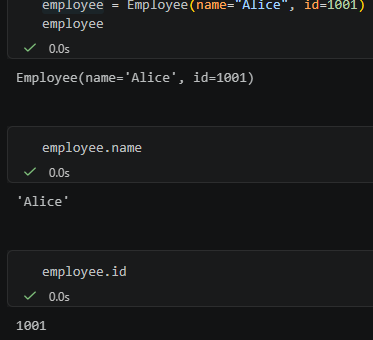
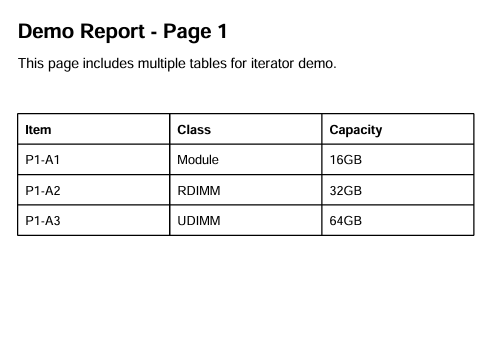
![Python PyMuPDF fitz 教學:從pdf中抓文字、抓 fonts、抓表格; pip install PyMuPDF ; import fitz ; text_dict = page.get_text("dict") #type(page) is pymupdf.Page ; blocks:list[dict] = text_dict['blocks'] ; page.find_tables().tables [0].extract() ;如何判斷粗體字? - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2026/05/20260527141829_0_5a8a75-535x340.png)
![別把中文洗掉:Python `isalnum()` vs `[^A-Za-z0-9]` 含/不含 CJK中日韓 - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2026/05/20260525082752_0_4776cd-400x340.png)
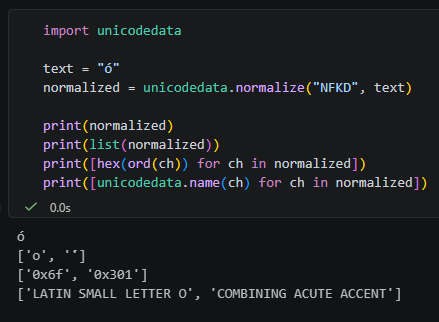
![Python `os.environ["PATH"]`(設定 *.exe 路徑)vs `sys.path`(設定 *.py 路徑)教學:用 Whisper 與 ffmpeg 看懂兩種很像的 path - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2026/05/20260513130826_0_8d5fb3-720x340.png)
近期留言