– 用 `fitz` 讀 PDF
– 逐 page 走訪 `blocks` 中的 `block` ->
`lines` 中的 `line`,並在每個 `line` 內走訪
`spans` 中的 `span`
– 把資料整理成 `rows` / DataFrame
– 在過程中考慮可讀性、記憶體、除錯效率
後續所有 `yield` 範例都沿著這條層級走訪。
先補一個常見易混點:
– 安裝套件名稱:`PyMuPDF`(`pip install PyMuPDF`)
– import 模組名稱:`fitz`(`import fitz`)
核心問題只有一句話:
– 什麼時候要用 `yield`,什麼時候用 `return`?
—
## 1. 先用一句話理解 yield
`yield` 會讓函式變成「可逐筆產生資料」的 generator。
也就是:
– `return`:一次回傳整包資料,函式結束
– `yield`:每次回傳一筆,函式暫停,下次再從原位置繼續
在 PDF 解析這種逐頁、逐行的場景,`yield` 非常自然。
—
## 2. 為什麼讀取pdf的場景適合 yield
資料流大致是:
1. 逐頁讀 PDF
2. 逐 block
3. 逐 line
4. 在每個 line 內逐 span
5. 計算欄位後 append 到 `rows`
這種「走訪邏輯」和「資料處理邏輯」可以拆開:
– 走訪層:用 `iter_text_lines()` + `yield`
– 資料處理層:for 迴圈內做統計與組資料
好處:
– 主流程更乾淨
– 走訪規則集中管理(例如只要 `type == 0`)
– 如果未來要加條件(跳過空白 line、只取特定頁),可在一處調整
### 2.1 很重要:先記住 `text_dict` 的實際資料結構
在 `page.get_text(“dict”)` 模式下,最核心的層級就是下面這個:
– 在這份 `text_dict` 結構中可先記:
複數型變數通常是 `list[dict]`,單數型變數通常是 `dict`
– 例如:`blocks: list[dict]` 對應 `block: dict`、
`lines: list[dict]` 對應 `line: dict`、
`spans: list[dict]` 對應 `span: dict`
text_dict = page.get_text("dict") #type(page) is pymupdf.Page
-> blocks :list[dict]
-> block :dict #dict_keys(['number', 'type', 'bbox', 'lines'])
-> lines :list[dict]
-> line :dict #dict_keys(['spans', 'wmode', 'dir', 'bbox'])
-> spans :list[dict]
-> span :dict #dict_keys(['size', 'flags', 'bidi', 'char_flags', 'font', 'color', 'alpha', 'ascender', 'descender', 'text', 'origin', 'bbox'])你現在的 `yield` 走訪,正是沿著這個階層往下走:
1. 先迭代 `blocks`
2. 再迭代 `lines`
3. 把 `line` 丟回主流程
4. 主流程再讀 `line[“spans”]` 做字型與文字統計
補充:`iter_text_lines()` 主要負責走到 `line`;
真正逐 `span` 的步驟在主流程(consumer)中完成。
所以 `yield page_no, block_no, line_no, line` 的本質是:
– 走訪函式負責「定位到 line」
– 主流程負責「消費 line 並處理 spans」
—
## 3. 最貼近你現況的寫法
import fitz
from typing import Any, Iterator
def iter_text_lines(doc: fitz.Document) -> Iterator[tuple[int, int, int, dict[str, Any]]]:
for page_no, page in enumerate(doc, start=1):
text_dict: dict[str, Any] = page.get_text("dict")
for block_no, block in enumerate(text_dict.get("blocks", [])):
if block.get("type") != 0: # 非文字 block(例如圖片/向量),跳過
continue
for line_no, line in enumerate(block.get("lines", [])):
yield page_no, block_no, line_no, line主流程:
from collections import Counter
rows = []
for page_no, block_no, line_no, line in iter_text_lines(doc):
spans = line.get("spans", [])
if not spans:
continue
line_text = "".join((span.get("text") or "") for span in spans)
if not line_text.strip():
continue
main_span = max(spans, key=lambda s: len(s.get("text") or ""))
# 統計每種 font 在這條 line 的字元總數
font_char_counts = Counter()
for span in spans:
font_name = span.get("font") or "<UNKNOWN_FONT>"
span_text = span.get("text") or ""
font_char_counts[font_name] += len(span_text)
rows.append({
"page": page_no,
"block_no": block_no,
"line_no": line_no,
"text": line_text,
"flags_main": main_span.get("flags", 0),
"span_count": len(spans),
"font_char_counts": dict(font_char_counts),
"has_mixed_fonts": len(font_char_counts) >= 2,
})這樣你在讀主流程時,不會被 3~4 層巢狀 for 淹沒。
`block.get(“type”)` 常見快速對照:`0 = text`, `1 = image`, `3 = vector`。
## 4. yield vs return
### A. `yield` 版本(逐筆)
def iter_text_lines(doc):
...
yield page_no, block_no, line_no, line結果:
– 可用 `for … in iter_text_lines(doc)`
– 每次拿一筆
– 很適合大檔、串流處理
### B. `return` 單筆(通常不是你要的)
def get_first_text_line(doc):
...
return page_no, block_no, line_no, line結果:
– 第一次命中就結束
– 只會拿到第一筆
### C. `return` 全部清單(可行,但一次吃完)
def get_all_text_lines(doc):
out = []
...
out.append((page_no, block_no, line_no, line))
return out結果:
– 先建整包資料再回傳
– 方便一次性操作
– 但資料量大時較耗記憶體
—
## 5. 進階一點:在 generator 內先做過濾
你可以把共通過濾提前,主流程更短
這個版本相較於 `iter_text_lines()`,額外做了 3 件事:
1. 只保留有 `spans` 的 line(`if not spans: continue`)
2. 把 spans 合併後,只保留非空白文字(`if not line_text.strip(): continue`)
3. 直接 `yield line_text, spans`,
讓主流程拿到可用資料,減少重複判斷
也就是說:
– `iter_text_lines()`:負責走到 line
– `iter_nonempty_text_lines()`:
負責走到「可用 line」(有 spans 且有文字)
def iter_nonempty_text_lines(doc: fitz.Document):
for page_no, page in enumerate(doc, start=1):
text_dict = page.get_text("dict")
for block_no, block in enumerate(text_dict.get("blocks", [])):
if block.get("type") != 0: # 非文字 block(例如圖片/向量),跳過
continue
for line_no, line in enumerate(block.get("lines", [])):
spans = line.get("spans", [])
if not spans:
continue
line_text = "".join((span.get("text") or "") for span in spans)
if not line_text.strip():
continue
yield page_no, block_no, line_no, line_text, spans主流程就變成:
for page_no, block_no, line_no, line_text, spans in iter_nonempty_text_lines(doc):
...## 6. 和你的 font 統計搭配
你要的「font 字元數量統計」可以這樣做:
from collections import Counter
font_char_counts = Counter()
for span in spans:
font_name = span.get("font") or "<UNKNOWN_FONT>"
span_text = span.get("text") or ""
if not span_text:
continue
font_char_counts[font_name] += len(span_text)重點:
– `yield` 解決的是資料流(逐筆產生)
– `Counter` 解決的是統計(依 key 累加)
– 兩者可以同時用,但解的問題不同
### 6.1 次要技巧:表格可拆兩步(主軸仍是 text/table 分流)
先講優先順序:
– 第一優先:`text lines/spans` 與 `tables` 分成兩條資料流
– 第二優先:`page.find_tables().tables` 要不要拆兩步(可讀性與 typing 問題)
你看到的 `tables = page.find_tables().tables` 可以展開成兩步,會更好理解:
from pymupdf.table import TableFinder, Table
tables_finder: TableFinder = page.find_tables() # 第一步:拿到 TableFinder
tables: list[Table] = tables_finder.tables # 第二步:拿到 list[Table]如果你的 PyMuPDF 版本較舊、無法 import `pymupdf.table`,再退回 `Any` 即可。
如果你想再把欄位拆清楚,可以這樣寫:
from pymupdf.table import TableFinder, Table
tables_finder: TableFinder = page.find_tables()
tables: list[Table] = tables_finder.tables
for table_idx, table in enumerate(tables, start=1):
table_rows: list[list[str | None]] = table.extract()
bbox: tuple[float, float, float, float] = tuple(table.bbox)
print({
"table_id": f"table{table_idx}",
"bbox": bbox,
"row_count": len(rows),
"col_count": len(rows[0]) if rows else 0,
})table.extract()
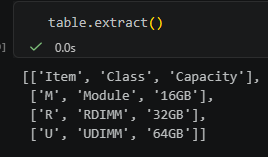
實務上建議把表格和一般文字分流保存:
– `raw_text_rows`:line/span 文字
– `tables_index`:每張表的位置與大小(`page`, `table_id`, `bbox`)
– `tables_rows`:每張表真正內容(`rows`)
—
## 7. 常見誤解
### 誤解 1:有了 yield 就不能 return
可以 `return`,但在 generator 裡 `return` 代表「結束產生」,
不會帶一般函式那種回傳資料語意。
### 誤解 2:yield 一定比較快
不一定。
`yield` 的主要優勢是「延遲產生」和「降低峰值記憶體」,
不是保證 CPU 一定更快。
### 誤解 3:yield 比較難除錯
剛開始會不習慣,但你可以:
– 在 generator 內加暫時 `print`(頁碼、block_no)
– 或先把小樣本 `list(islice(generator, n))` 看前幾筆
—
## 8. 什麼時候用哪一種
用 `yield`:
– 資料可逐筆處理
– 不需要一次拿完整清單
– 想把走訪邏輯封裝起來
用 `return list`:
– 後續需要多次重複遍歷同一批資料
– 資料量可接受
– 想要一次性快照
在你目前 PDF 文字抽取流程,預設建議:
– 走訪層用 `yield`
– 聚合輸出(DataFrame 前)才用 list 累積
—
## 9. 一個完整、可貼近現況的最小骨架
import fitz
import pandas as pd
from collections import Counter
from typing import Any, Iterator
def iter_text_lines(doc: fitz.Document) -> Iterator[tuple[int, int, int, dict[str, Any]]]:
for page_no, page in enumerate(doc, start=1):
text_dict: dict[str, Any] = page.get_text("dict")
for block_no, block in enumerate(text_dict.get("blocks", [])):
if block.get("type") != 0: # 非文字 block(例如圖片/向量),跳過
continue
for line_no, line in enumerate(block.get("lines", [])):
yield page_no, block_no, line_no, line
pdf_path = r"D:\Temp\fitz_demo_tutorial.pdf"
doc = fitz.open(pdf_path)
rows = []
for page_no, block_no, line_no, line in iter_text_lines(doc):
spans = line.get("spans", [])
if not spans:
continue
line_text = "".join((span.get("text") or "") for span in spans)
if not line_text.strip():
continue
main_span = max(spans, key=lambda s: len(s.get("text") or ""))
font_char_counts = Counter()
for span in spans:
font_name = span.get("font") or "<UNKNOWN_FONT>"
span_text = span.get("text") or ""
if not span_text:
continue
font_char_counts[font_name] += len(span_text)
rows.append({
"page": page_no,
"block_no": block_no,
"line_no": line_no,
"text": line_text,
"flags_main": main_span.get("flags", 0),
"span_count": len(spans),
"font_char_counts": dict(font_char_counts),
"has_mixed_fonts": len(font_char_counts) >= 2,
})
doc.close()
df = pd.DataFrame(rows)
print(df.head(6))df.head(6)
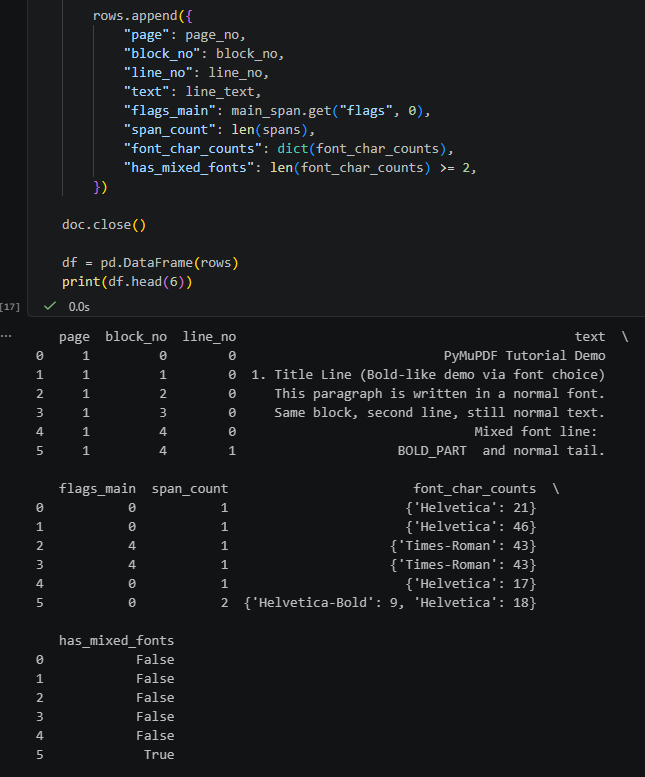
fitz_demo_tutorial.pdf
(注意其中一 line 有混合字型:
BOLD_PART and normal tail.)

## 10. 這份教學的結論
對你現在這個 PDF 解析場景:
– `yield` 最適合拿來封裝「逐頁逐行走訪」
– `return` 適合回傳最終聚合結果(例如 `rows` 或 DataFrame)
– `yield` 和 `Counter` 可以搭配,但分工不同
推薦hahow線上學習python: https://igrape.net/30afN
 vs 深拷貝(deep copy),什麼時候需要用深拷貝? import copy ; b = copy.deepcopy(a)")
![Python爬蟲:BeautifulSoup的 .find_all() 與 .find() 與 .select(‘標籤名[屬性名1=”屬性值1″][屬性名2=”屬性值2″]’) ; from bs4 import BeautifulSoup ; Live Server(可以預覽HTML的VS Code套件)](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2025/03/20250330190318_0_925655.jpg?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python爬蟲:BeautifulSoup的 .find_all() 與 .find() 與 .select(‘標籤名[屬性名1=”屬性值1″][屬性名2=”屬性值2″]’) ; from bs4 import BeautifulSoup ; Live Server(可以預覽HTML的VS Code套件)")
 與 os.path.exists() 有何差別?")
")
 ; y_new = np.polyval(coeffs, x_new) ; p = np.poly1d(coeffs) ; print(p(x_new)) #效果同 np.polyval(coeffs, x_new)")
 #全數字?、isalpha() #全字母?、isalnum() #全字母或數字?、islower() #全小寫? 和 isupper() #全大寫?")

")
, Null (null), Object(對應python的dict), Array(對應python的list); Python如何讀取json檔?")

近期留言