在開發過程中,我們經常需要回答這樣的問題:「這兩個字串到底哪裡不一樣?」、「這兩個版本的程式碼改了什麼?」。
如果只靠肉眼比對,不僅累,還容易看漏(尤其是像 0 和 O,或是簡繁體中文這種細微差異)。Python 內建的標準函式庫 difflib 就是為此而生的神器。它不需要安裝任何第三方套件,就能幫你精準揪出差異。
這篇文章將帶你從基礎比對,一路學到如何製作精美的差異報告。
1. 基礎起手式:這兩個字串有多像? (SequenceMatcher)
當你想知道兩個字串的「相似度」時,SequenceMatcher 是最簡單的工具。這在模糊搜尋、檢查抄襲或比對 LLM 幻覺時非常有用。
import difflib
text_a = "Python is powerful"
text_b = "Python is power"
# 建立比對物件
matcher = difflib.SequenceMatcher(None, text_a, text_b)
# 取得相似度 (0.0 ~ 1.0)
similarity = matcher.ratio()
print(f"相似度: {similarity:.2%}")
# 輸出: 相似度: 90.91%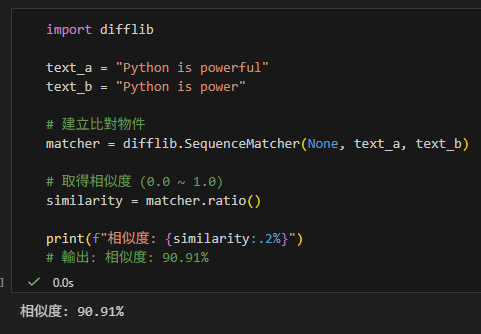
應用場景:
- 檢查使用者輸入的拼寫錯誤(例如輸入 “Pyton” 也能猜出是 “Python”)。
- 比對 AI 生成的文本與原始文本的重合度。
2. 進階診斷:找出具體差異 (ndiff)
知道「很像」還不夠,我們想知道「哪裡」不一樣。ndiff 會生成類似 Git diff 的輸出,告訴你哪些字是新增的、哪些是刪除的。
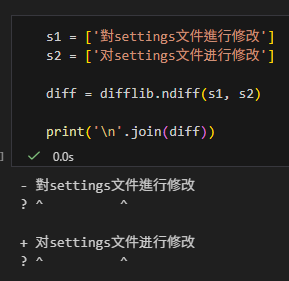
s1 = ['對settings文件進行修改']
s2 = ['对settings文件进行修改']
diff = difflib.ndiff(s1, s2)
print('\n'.join(diff))輸出解讀:
- 對settings文件進行修改
? ^ ^
+ 对settings文件进行修改
? ^ ^-代表原始字串有的(被刪除/被替換)。+代表新字串有的(新增/替換後)。?這一行最關鍵,它試圖用^符號標示出變更發生的位置。
⚠️ 常見坑點:
在處理中文字時,因為中文字元在終端機佔 2 格寬度,但 ndiff 把它當作 1 個字元計算,導致 ^ 指示符號經常對不準(會偏左)。這就是為什麼有時候看 ndiff 還是覺得很累的原因。
3. 終極視覺化:生成 HTML 報告 (HtmlDiff)
這是 difflib 最強大的功能。它能直接生成一個 HTML 檔案(或字串),用表格並排顯示差異,非常適合用來做 Code Review 工具或日誌報告。
import difflib
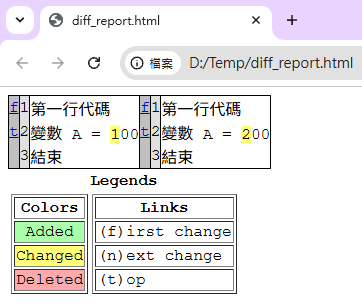
lines_a = ["第一行代碼", "變數 A = 100", "結束"]
lines_b = ["第一行代碼", "變數 A = 200", "結束"]
# 建立 HTML Diff 物件
html_diff = difflib.HtmlDiff()
# 生成 HTML 表格
# make_file 會生成完整的 <html>...</html> 結構
html_content = html_diff.make_file(lines_a, lines_b)
# 將結果寫入檔案,用瀏覽器打開看
with open("diff_report.html", "w", encoding="utf-8") as f:
f.write(html_content)優點:
- 瀏覽器打開,色彩分明(新增是綠色,刪除是紅色)。
- 適合給非技術人員(如 PM 或客戶)看差異。
4. 實戰技巧:解決「看不清楚」的問題
正如您在使用中發現的,預設的 HtmlDiff 有時在深色背景(Dark Mode)下顯示不佳,或者對於「行內」的細微字元差異標示不夠明顯。
我們可以利用 SequenceMatcher 的 get_opcodes() 方法,自己寫一個輕量級的高亮顯示器。這能讓我們完全掌控顏色和樣式。
自製高亮比對函數 (Highlight Diff):
import difflib
from IPython.display import HTML, display
def show_diff(text1, text2):
"""
自製的差異顯示器,專門解決中文對齊與顏色不明顯的問題
"""
matcher = difflib.SequenceMatcher(None, text1, text2)
result_1 = []
result_2 = []
for tag, i1, i2, j1, j2 in matcher.get_opcodes():
segment_1 = text1[i1:i2]
segment_2 = text2[j1:j2]
if tag == 'equal':
# 相同的文字,保持原樣
result_1.append(segment_1)
result_2.append(segment_2)
elif tag == 'replace':
# 替換的文字:舊的變紅,新的變綠
result_1.append(f'<span style="background:#ffcccc; color:red; text-decoration:line-through;">{segment_1}</span>')
result_2.append(f'<span style="background:#ccffcc; color:green; font-weight:bold;">{segment_2}</span>')
elif tag == 'delete':
# 刪除的文字
result_1.append(f'<span style="background:#ffcccc; color:red; text-decoration:line-through;">{segment_1}</span>')
elif tag == 'insert':
# 新增的文字
result_2.append(f'<span style="background:#ccffcc; color:green; font-weight:bold;">{segment_2}</span>')
# 組合 HTML
html = f"""
<div style="font-family: 'Microsoft JhengHei', sans-serif; line-height: 1.6;">
<div><strong>原始:</strong>{''.join(result_1)}</div>
<div><strong>修改:</strong>{''.join(result_2)}</div>
</div>
"""
return HTML(html)
# 測試繁簡轉換差異
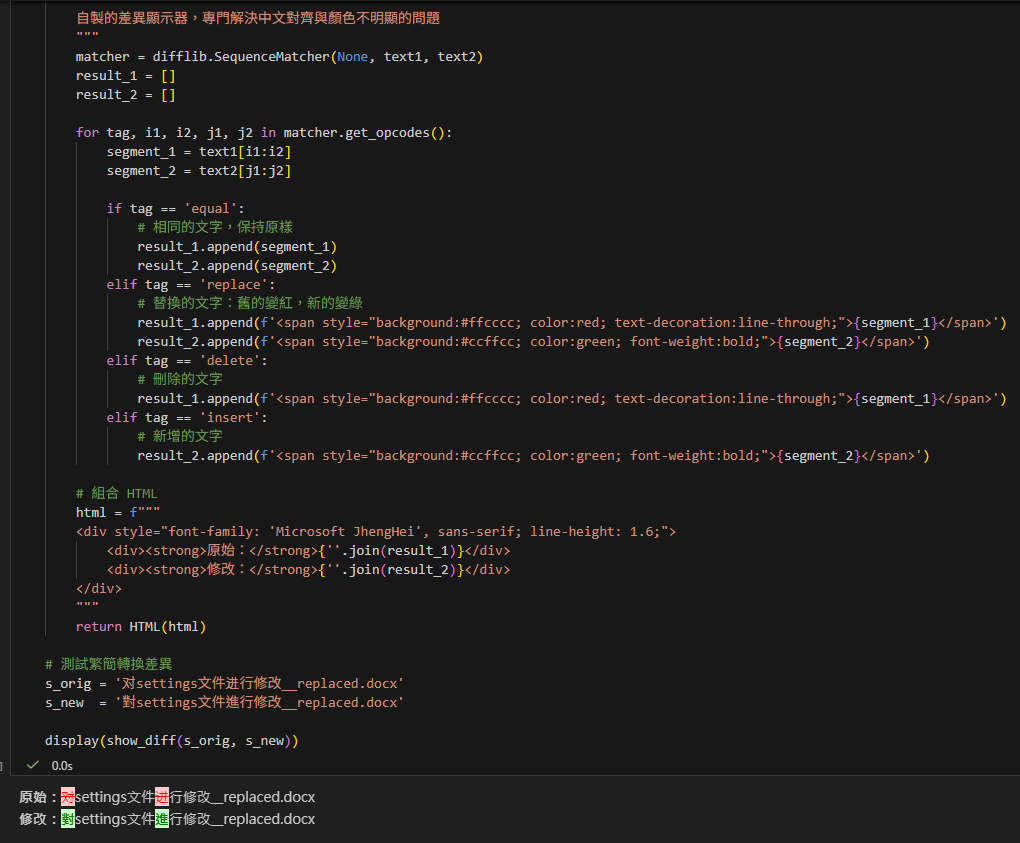
s_orig = '对settings文件进行修改__replaced.docx'
s_new = '對settings文件進行修改__replaced.docx'
display(show_diff(s_orig, s_new))這段程式碼的效果:
它不會只給你兩行字,而是會精準地把「对」畫上紅色刪除線,並在旁邊顯示綠色的「對」。這才是我們真正想要的「找不同」體驗!
總結
- 比相似度:用
SequenceMatcher.ratio()。 - 終端機快速除錯:用
ndiff(但要小心中文對齊問題)。 - 生成報表:用
HtmlDiff。 - 精準視覺化:使用
get_opcodes()自定義 HTML 輸出,這是處理中文差異的最優解。
掌握 difflib,下次再遇到「這段 Code 到底改了哪裡?」或「這個字串怎麼怪怪的?」時,你就不再需要瞇著眼睛猜了。
推薦hahow線上學習python: https://igrape.net/30afN



與副本(Copy) : 避免資料操作錯誤的指南; 如何處理SettingWithCopyWarning ?")

, dtype=float) ; print(data.shape); min0 = numpy.min(a,axis=0) ; min1 = numpy.min(a,axis=1) #2次沿軸1 ; numpy.average() ;array的軸向")
![Python socket連線出現[WinError 10049] 內容中所要求的位址不正確 cmd.exe: ipconfig/all ; TCP/IPv4 vs IPv6](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2022/10/20221028151556_42.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python socket連線出現[WinError 10049] 內容中所要求的位址不正確 cmd.exe: ipconfig/all ; TCP/IPv4 vs IPv6")
 or(|) xor(^) not ; assert 預期為真的條件式, “錯誤訊息” ; 條件式為真的話,繼續往下跑,否則AssertionError: “錯誤訊息”")
 合併兩個DataFrame? 具關聯性欄位合併")
![Python: matplotlib如何控制legend的位置? ax.legend(handles=[patch], loc='upper left', bbox_to_anchor=(6/10, 3/5) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/05/20230502163945_79-520x245.png)

近期留言