traverse 這樣的遞迴 (Recursion) 結構,
正是用來處理「樹狀結構 (Tree Structure)」的最強大武器。
不管是 JSON 設定檔、資料夾裡的檔案架構,
還是程式語言的 AST (抽象語法樹, Abstract Syntax Tree),
在本質上都是一種樹狀結構:它們都有一個「根節點」,
然後往下分岔出無數個「子節點」,子節點又會繼續往下分岔。
這裡我們用一個簡單的例子,
帶你了解如何用遞迴來「走訪 (Traverse)」這些資料,
並且看看這跟 AST 有什麼關聯。
第一步:理解遞迴的核心精神 —— 「俄羅斯娃娃」
遞迴的核心精神就是「自己呼叫自己」。
想像你在玩一個巨大的俄羅斯娃娃,
你的目標是把裡面所有的玩偶都拿出來排好。
你可以把這件事寫成一個規則:
def 打開娃娃(當前的娃娃):
# 1. 終止條件 (Base Case):如果沒有更小的了,就停下來
if 當前的娃娃.是實心的():
紀錄("找到最核心的實心娃娃了!")
return
# 2. 遞迴條件 (Recursive Step):如果裡面還有娃娃
else:
# 先從當前的娃娃肚子裡,把小娃娃「拿出來」
裡面的小娃娃 = 當前的娃娃.取出內容物()
# 然後針對這個小娃娃,再次執行「打開娃娃」的任務(自己呼叫自己)
打開娃娃(裡面的小娃娃) 第二步:簡化的 JSON 遞迴範例
回到程式碼裡的 traverse 結構。
假設我們有一個非常簡單的 JSON
(其實在 Python 裡這就是巢狀字典和列表),
我們目標是「找出所有存在 class_name 的積木」。
data = {
"step1": {
"class_name": "LoginStep",
"description": "User logs in"
},
"step2": [
{
"class_name": "VerificationStep",
"type": "email"
},
"這是一個普通的字串,不用理他"
]
}這個結構裡有字典 (dict) 也有列表 (list)。
我們的遞迴可以這樣寫:
def simple_traverse(node):
# 只要是字典,我們就來檢查
if isinstance(node, dict):
# 1. 如果字典裡有 class_name,我們就抓到目標了!印出來
if "class_name" in node:
print(f"找到目標囉!class_name 叫做: {node['class_name']}")
# 2. 為了確保我們沒有漏掉字典「更深處」的東西,我們把字典裡所有的 value 都拿出來,再走訪一次
for key, value in node.items():
simple_traverse(value) # 遞迴:繼續往下層找
# 如果遇到的是一個列表,那就把列表裡的東西一個一個拿出來走訪
elif isinstance(node, list):
for item in node:
simple_traverse(item) # 遞迴:繼續往下層找
# 開始走訪
simple_traverse(data)輸出結果:
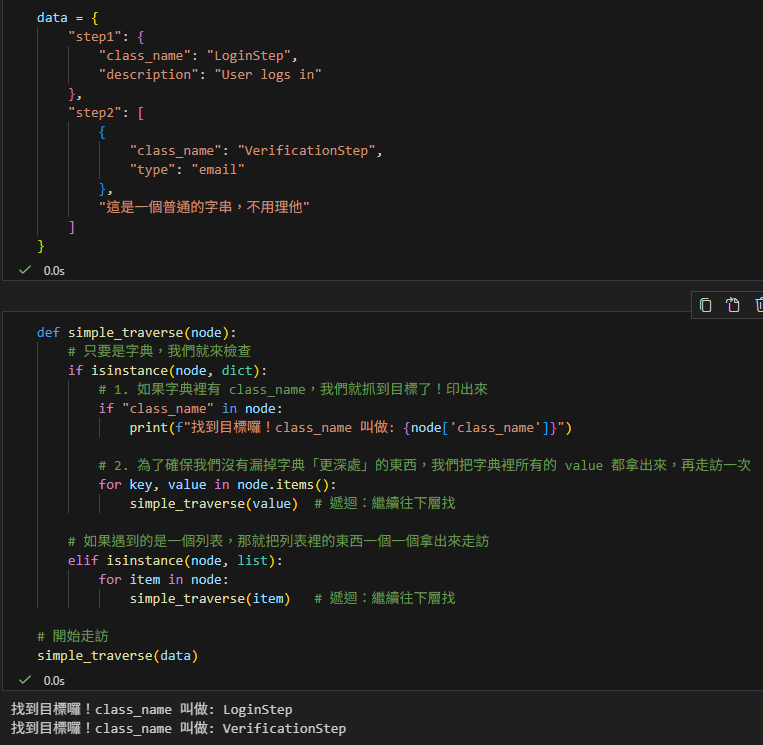
你看,我們完全不需要知道這個 JSON 到底有幾層,
只要透過 simple_traverse(value) 和 simple_traverse(item),
程式就會像藤蔓一樣自動延伸到底部,
這就是遞迴的魅力!
第三步:這跟 AST (抽象語法樹) 的關係?
是的,處理 AST 百分之百就是用這種遞迴結構!
當 Python (或其他編譯器) 讀取你的程式碼時,
它會把文字轉換成一棵抽象語法樹 (AST)。
例如你寫了一句 a = 1 + 2,
在 AST 裡面可能長這樣 (簡化版):
ast_tree = {
"type": "Assign", # 這是一個指派運算 (Assign)
"targets": ["a"], # 左邊是要被賦值的變數 "a"
"value": { # 右邊要賦的值是一個加法運算 (BinOp)
"type": "BinOp",
"operator": "Add", # 運算子是加號
"left": { "type": "Constant", "value": 1 }, # 左邊的常數 1
"right": { "type": "Constant", "value": 2 } # 右邊的常數 2
}
}這不就跟前面的 JSON 長得一模一樣嗎!
如果開發者想用 AST 工具來檢查
這份程式碼「有沒有用到加法」,
他們寫的程式碼邏輯,
跟寫在 get_path_for_class_v4.py 裡的
traverse 幾乎是同一個模子刻出來的:
def check_addition_ast(node):
# 如果這是一個字典型態的節點
if isinstance(node, dict):
# 如果這個節點是一個 加法運算 (Add)
if node.get("operator") == "Add":
print("警告:這段程式碼使用了加法!")
# 繼續遞迴走訪底下的所有節點 (把左邊、右邊都拆出來檢查)
for key, child_node in node.items():
check_addition_ast(child_node)
check_addition_ast(ast_tree)
# 輸出: 警告:這段程式碼使用了加法!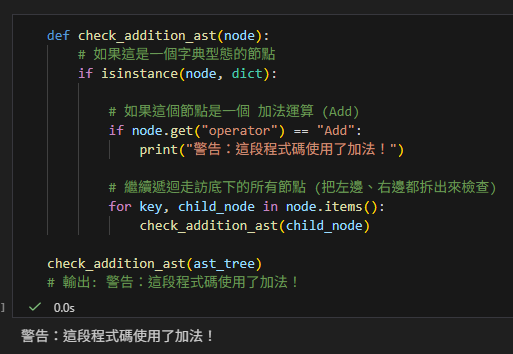
總結
遞迴 (Recursion) 最適合用來處理「深度未知的主體」,
例如 JSON、資料夾、XML、或是 AST。
get_path_for_class_v4.py 的寫法:
檢查是否為 dict/list -> 做該層該做的事 -> 取出子結點繼續 traverse,
這個骨架其實是所有語法解析器、
甚至爬蟲都在使用的標準設計模式 (Design Pattern)。
等你以後要處理像爬梳 HTML 標籤或是 AST 時,
這個老朋友一定會再跟你見面的!
推薦hahow線上學習python: https://igrape.net/30afN
進階挑戰:不只要找到娃娃,
還要記錄「娃娃在哪裡」(路徑追蹤)
在實務上,我們通常不只滿足於「找到東西」,
我們更想知道「這個東西藏在什麼路徑底下」。
這就像在迷宮中留下麵包屑,
我們可以在遞迴函式中多加上一個代表「目前位置」的參數。
讓我們擴充一下剛才的例子,
這次我們要記錄 class_name 發生的完整路徑。
data = {
"step1": {
"class_name": "LoginStep",
"description": "User logs in"
},
"step2": [
{
"class_name": "VerificationStep",
"type": "email"
},
{"nested_node": {"class_name": "DeepStep"}} # 藏得很深的一層
]
}這次,我們給 traverse 加上一個 current_path 參數,
隨著每次遞迴往下,這個路徑就會變長:
def traverse_with_path(node, current_path="root"):
# 只要是字典,我們就來檢查
if isinstance(node, dict):
# 1. 抓到目標!把目前的「路徑」跟「目標」印出來
if "class_name" in node:
print(f"📍 找到目標!路徑: [{current_path}] -> class_name: {node['class_name']}")
# 2. 繼續往下挖
for key, value in node.items():
# 準備下一層的路徑 (把目前的 key 加上去)
# 例如: root -> root | step1
new_path = f"{current_path} | {key}"
traverse_with_path(value, new_path)
# 如果遇到的是一個列表
elif isinstance(node, list):
for index, item in enumerate(node):
# 列表的路徑我們用 index 來表示
# 例如: root | step2 -> root | step2 | 0
new_path = f"{current_path} | {index}"
traverse_with_path(item, new_path)
# 開始走訪,起點路徑就叫做 "root"
traverse_with_path(data)輸出結果:
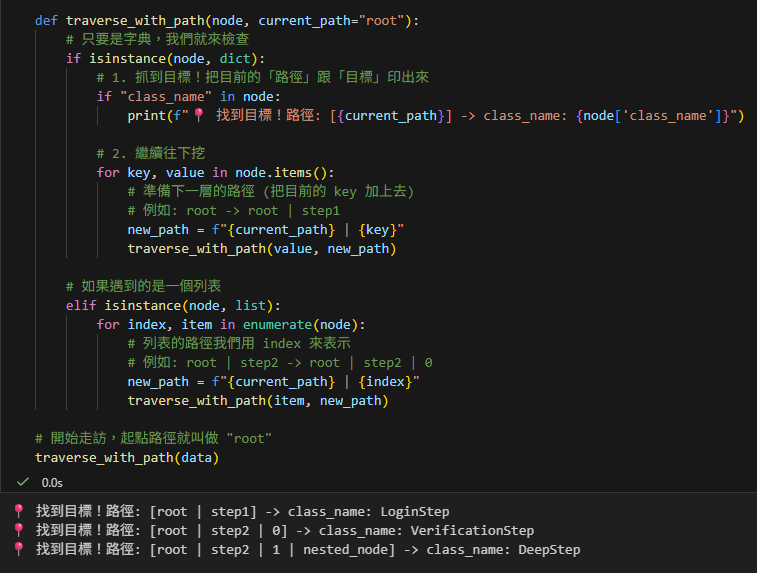
💡 路徑追蹤的關鍵技巧
這個寫法有兩個關鍵點:
路徑狀態的傳遞:
我們不是在函式外面宣告一個全域變數來記錄路徑,
而是把 new_path 當作參數傳給下一層。
這樣一來,每一層看見的都是屬於它自己的「歷史軌跡」。
字典用 Key,列表用 Index:
當遇到字典 (dict) 時,我們串接的是字典的 key;
當遇到列表 (list) 時,因為列表沒有 key,
我們改用 index(索引用法:for index, item in enumerate(…))
來表示它的位置。
遞迴不僅是探索未知的利器,
也是繪製地圖的最佳導航的最佳方式。
推薦hahow線上學習python: https://igrape.net/30afN
這個範例其實已經抓到重點了(遞迴 + 累積路徑),
要更接近「實際 py」的寫法,
主要差在三個地方,整理一下改法:
目前範例的三個弱點
- 只 print,沒收集 → 無法後續處理(存檔、比對、回傳)。
- 路徑是字串 → 之後想「照著路徑回頭取值」很麻煩(要 split 又要判斷 int/str)。
- 函式有副作用(print) → 不好測試、不好複用。
建議改法(三種層次,看你要多「實際」)
版本 A:把結果收集到 list(最小改動)
def traverse_with_path(node, current_path="root", results=None):
if results is None:
results = [] # 避免 mutable default argument 的坑
if isinstance(node, dict):
if "class_name" in node:
results.append((current_path, node["class_name"]))
for key, value in node.items():
traverse_with_path(value, f"{current_path} | {key}", results)
elif isinstance(node, list):
for index, item in enumerate(node):
traverse_with_path(item, f"{current_path} | {index}", results)
return results
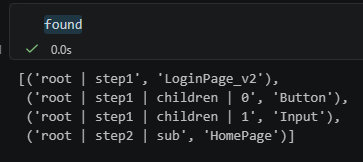
found = traverse_with_path(data)
for path, cls in found:
print(f"📍 {path} -> {cls}")重點:用 results=None + 內部初始化,
避免 Python 「可變預設參數」共用同一個 list 的經典 bug。
found:List[Tuple[str,str]]
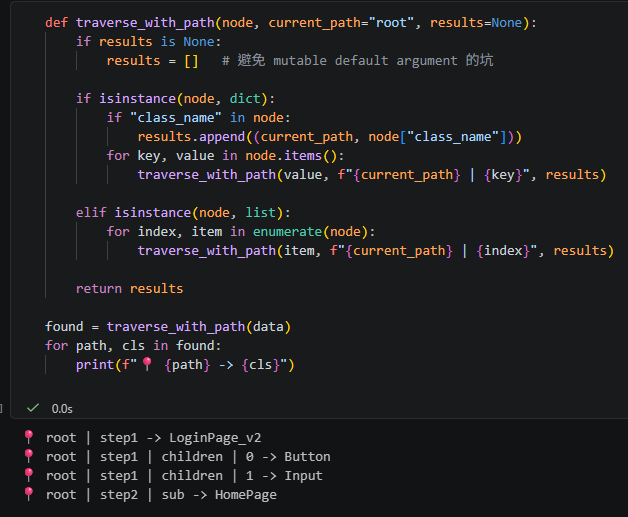
版本 B:路徑用 list of keys(可回頭取值,最實用)
字串路徑看得懂但不好用。
實務上會存「key 的序列」,這樣可以直接拿回原本的值:
# %%
# ---------- 1. 核心函式 ----------
def traverse_with_path(node, path=None, results=None):
if path is None:
path = []
if results is None:
results = []
if isinstance(node, dict):
if "class_name" in node:
results.append({
"path": path, # e.g. ["step1", "children", 0]
"path_str": " | ".join(map(str, path)) or "root",
"class_name": node["class_name"],
})
for key, value in node.items():
traverse_with_path(value, path + [key], results)
elif isinstance(node, list):
for index, item in enumerate(node):
traverse_with_path(item, path + [index], results)
return results
def get_by_path(data, path):
"""照著 path 把該節點取回來(驗證路徑正確 / 之後要改值也靠它)"""
cur = data
for key in path:
cur = cur[key]
return cur
# ---------- 2. 測試資料 ----------
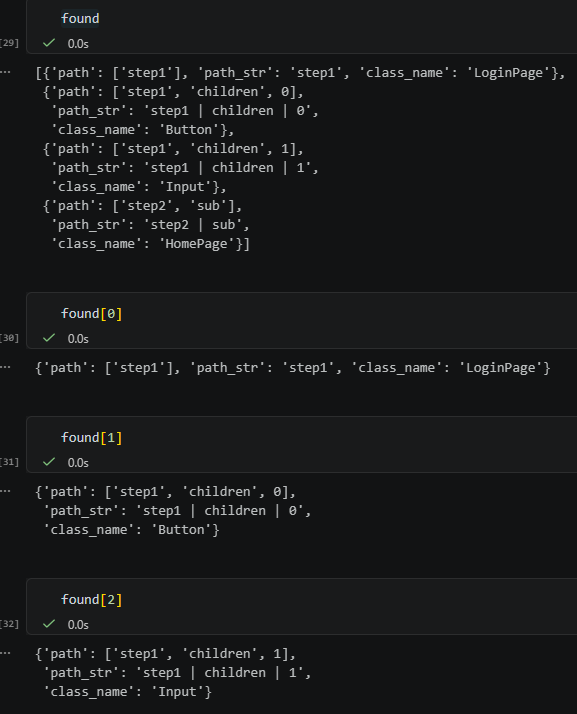
data = {
"step1": {
"class_name": "LoginPage",
"children": [
{"class_name": "Button", "label": "OK"},
{"class_name": "Input", "label": "帳號"},
],
},
"step2": {
"note": "這層沒有 class_name",
"sub": {"class_name": "HomePage"},
},
}
# ---------- 3. 使用方式 ----------
found = traverse_with_path(data)
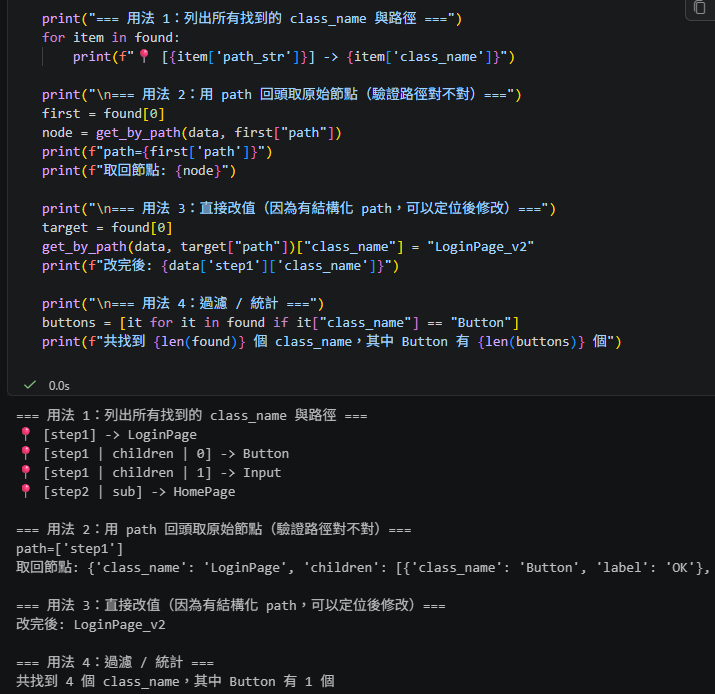
print("=== 用法 1:列出所有找到的 class_name 與路徑 ===")
for item in found:
print(f"📍 [{item['path_str']}] -> {item['class_name']}")
print("\n=== 用法 2:用 path 回頭取原始節點(驗證路徑對不對)===")
first = found[0]
node = get_by_path(data, first["path"])
print(f"path={first['path']}")
print(f"取回節點: {node}")
print("\n=== 用法 3:直接改值(因為有結構化 path,可以定位後修改)===")
target = found[0]
get_by_path(data, target["path"])["class_name"] = "LoginPage_v2"
print(f"改完後: {data['step1']['class_name']}")
print("\n=== 用法 4:過濾 / 統計 ===")
buttons = [it for it in found if it["class_name"] == "Button"]
print(f"共找到 {len(found)} 個 class_name,其中 Button 有 {len(buttons)} 個")
path + [key] 每層都建新 list,不會互相污染;
之後用 get_by_path 就能驗證抓到的位置對不對。
found
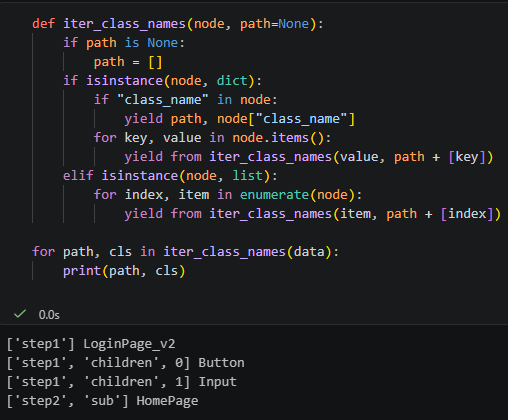
版本 C:用 generator(資料很大時省記憶體)
def iter_class_names(node, path=None):
if path is None:
path = []
if isinstance(node, dict):
if "class_name" in node:
yield path, node["class_name"]
for key, value in node.items():
yield from iter_class_names(value, path + [key])
elif isinstance(node, list):
for index, item in enumerate(node):
yield from iter_class_names(item, path + [index])
for path, cls in iter_class_names(data):
print(path, cls)
如果目標是
「找到 class_name 之後還要對它做事(改值 / 定位 / 輸出報表)」,
用版本 B 最貼近實際專案:路徑是結構化的 list,
搭配 get_by_path 可讀可寫,也方便寫單元測試。
推薦hahow線上學習python: https://igrape.net/30afN


 函數; from docx.oxml.ns import qn #qualified name ; qn(‘w:p’) ; qn(‘w:tbl’)")

![Python: pandas.DataFrame如何移除所有空白列?pandas.isna( df_raw[0] ).tolist() ; df_drop0 = df_raw.drop(nanIdx,axis=0).reset_index(drop=True)](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2022/12/20221206184635_4.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: pandas.DataFrame如何移除所有空白列?pandas.isna( df_raw[0] ).tolist() ; df_drop0 = df_raw.drop(nanIdx,axis=0).reset_index(drop=True)")
![Python如何串接OpenAI /Claude /Gemini API自動將大量維修紀錄JSON轉自然語言描述(並避免中斷資料遺失)response = client.chat.completions.create() ; reply = response.choices[0].message.content](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2025/07/20250716084059_0_c5b368.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python如何串接OpenAI /Claude /Gemini API自動將大量維修紀錄JSON轉自然語言描述(並避免中斷資料遺失)response = client.chat.completions.create() ; reply = response.choices[0].message.content")
還是FALSE(0)?你知道為何老是搜尋錯誤嗎?")
? from tkinter import Tk, Button, filedialog ; 物件導向避免使用全域變數 ; pandas.read_csv(fpath, skip_blank_lines = True) 可以濾掉空列,Tab , 不定數空白")


近期留言