開篇:為什麼我們需要斷言?
在日常的文本處理中,我們常常遇到這樣的困境:
我們想要找到字串中的某個「特定位置」,但不想破壞或消耗原本的字串內容。
如果用傳統的 (群組) 把字元抓出來,替換時還得把這些字元再補回去,容易顯得囉唆。
這時,斷言(Assertion,或稱零寬度斷言) 就像是一把隱形的游標手術刀!它允許你在字串中設置「守衛」,它只負責檢查該位置的左右兩邊符不符合條件,但絕不會吃掉實際的字元。
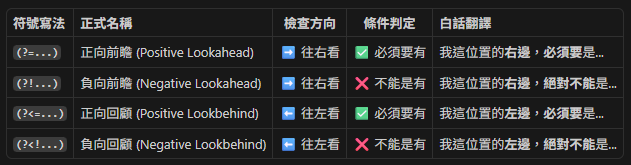
核心速查表與象形記憶法
斷言的符號組合看起來就像顏文字般複雜 (?<=…),但其實這套語法藏著非常直觀的象形含義:
?:特殊指令起手式(這不是普通的群組括號!)
<:箭頭朝左,代表向左回顧 (沒有箭頭就是向右前瞻)
=:代表條件必須成立
!:代表條件絕對不能成立
四大斷言家族
實戰對決:如何拆解駝峰式命名 (CamelCase)?
假設我們有一個連續的程式碼字串 DauntlessFwUpdateProcessStep。
我們的目標是把它拆開,變成有空格分隔的:Dauntless Fw Update Process Step。
為此,我們需要找到小寫字母與大寫字母之間的「交界處」,並在那裡塞入一個空格。
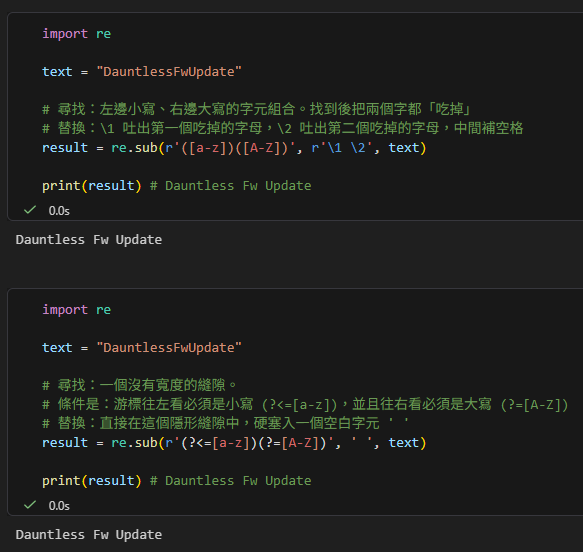
🔪 老派做法:捕獲群組法 (Capturing Groups)
傳統做法是直接找字元,把它們吃進肚子裡,然後重新吐出來。
import re
text = "DauntlessFwUpdate"
# 尋找:左邊小寫、右邊大寫的字元組合。找到後把兩個字都「吃掉」
# 替換:\1 吐出第一個吃掉的字母,\2 吐出第二個吃掉的字母,中間補空格
result = re.sub(r'([a-z])([A-Z])', r'\1 \2', text)
print(result) # Dauntless Fw Update限制:這種寫法步驟繁瑣,且因為涉及記憶體的存取與反向引用 (\1, \2),有時在複雜的替換條件中會顯得笨重。
🪄 現代做法:零寬度斷言法 (Lookaround Assertions)
利用斷言語法,我們不再尋找「字元」,而是精準尋找「字元中間的無形縫隙」!
import re
text = "DauntlessFwUpdate"
# 尋找:一個沒有寬度的縫隙。
# 條件是:游標往左看必須是小寫 (?<=[a-z]),並且往右看必須是大寫 (?=[A-Z])
# 替換:直接在這個隱形縫隙中,硬塞入一個空白字元 ' '
result = re.sub(r'(?<=[a-z])(?=[A-Z])', ' ', text)
print(result) # Dauntless Fw Update優點:意圖極度精準且優雅!原字串的字母自始至終都沒有被「消耗」,我們只是找到那個完美的接縫處,將空白插入。
總結
掌握正則表達式的斷言 (Lookaround) 功能後,你處理字串的思維會從「操作具體字元」,昇華為「操作隱形空間與邏輯條件」。下次當你發現自己寫了一堆括號 () 以及 \1\2\3 在做回補組裝時,不妨停下來回想這張「象形速查表」——試著用斷言,寫出更像頂尖駭客的優雅程式碼吧!
推薦hahow線上學習python: https://igrape.net/30afN
進階實戰:當遇到連續大寫字母 (Acronyms) 該怎麼辦?
在處理真實的程式碼或測試紀錄時,我們經常會遇到首字母縮寫 (Acronym) 與 CamelCase 混用的情況,例如:AAPLCheckProcessStep 或 XMLHTTPRequest。
如果我們只使用基礎版的正則表達式 (?<=[a-z])(?=[A-Z]),會發現它「切不開」連續大寫字母:
✅ Check 與 Process 之間 (k 接 P) -> 成功切開
❌ AAPL 與 Check 之間 (L 接 C) -> 失敗!因為兩邊都是大寫字母。
這時候,我們需要升級我們的 Regex 武器,利用 | (OR) 運算子,將「兩種切換條件」組合起來:
進階正則表示式
pattern = r'(?<=[a-z])(?=[A-Z])|(?<=[A-Z])(?=[A-Z][a-z])'語法拆解與定位原理
這個進階 Pattern 由 | 分成左右兩個條件(只要滿足其中一個就會切開):
- 條件一:
(?<=[a-z])(?=[A-Z])(一般 CamelCase)- Lookbehind:左邊是小寫字母
[a-z] - Lookahead:右邊是大寫字母
[A-Z] - 🎯 作用點:
Check與Process之間的邊界。
- Lookbehind:左邊是小寫字母
- 條件二:
(?<=[A-Z])(?=[A-Z][a-z])(縮寫詞接一般單字)- Lookbehind
(?<=[A-Z]):左邊是一個大寫字母(代表縮寫詞的結尾,例如AAPL的L)。 - Lookahead
(?=[A-Z][a-z]):右邊必須是**「一個大寫字母緊接著一個小寫字母」**(代表新單字的開頭,例如Check的Ch)。 - 🎯 作用點:精準定位在
AAPL的L與Check的C之間的隱形邊界!
- Lookbehind
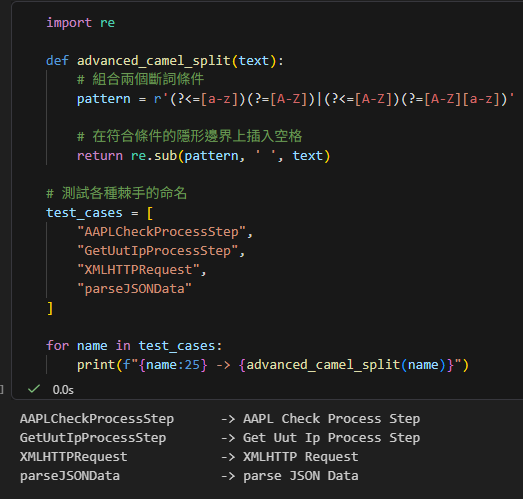
Python 實戰程式碼
import re
def advanced_camel_split(text):
# 組合兩個斷詞條件
pattern = r'(?<=[a-z])(?=[A-Z])|(?<=[A-Z])(?=[A-Z][a-z])'
# 在符合條件的隱形邊界上插入空格
return re.sub(pattern, ' ', text)
# 測試各種棘手的命名
test_cases = [
"AAPLCheckProcessStep",
"GetUutIpProcessStep",
"XMLHTTPRequest",
"parseJSONData"
]
for name in test_cases:
print(f"{name:25} -> {advanced_camel_split(name)}")輸出結果:
💡 提示:為什麼不會把 AAPL 切成 A A P L?
因為 (?=[A-Z][a-z]) 這個條件非常聰明地限定了:右邊的大寫字母後面必須跟著小寫字母。所以 A 後面是 A (沒有小寫),P 後面是 L (沒有小寫),就不會被誤切;直到 L 後面遇到 Ch (大寫接小寫),才會發動切割!
推薦hahow線上學習python: https://igrape.net/30afN
改用 re.split
import re
def advanced_camel_split(text):
# 組合兩個斷詞條件
pattern = r'(?<=[a-z])(?=[A-Z])|(?<=[A-Z])(?=[A-Z][a-z])'
# 在符合條件的隱形邊界上插入空格
return re.sub(pattern, ' ', text)
# 測試各種棘手的命名
test_cases = [
"AAPLCheckProcessStep",
"GetUutIpProcessStep",
"XMLHTTPRequest",
"parseJSONData"
]
for name in test_cases:
print(f"{name:25} -> {advanced_camel_split(name)}")
print("\n--- 換用 re.split 示範 ---\n")
def list_camel_split(text):
pattern = r'(?<=[a-z])(?=[A-Z])|(?<=[A-Z])(?=[A-Z][a-z])'
# 直接在縫隙處切一刀,直接輸出 List
return re.split(pattern, text)
for name in test_cases:
print(f"{name:25} -> {list_camel_split(name)}")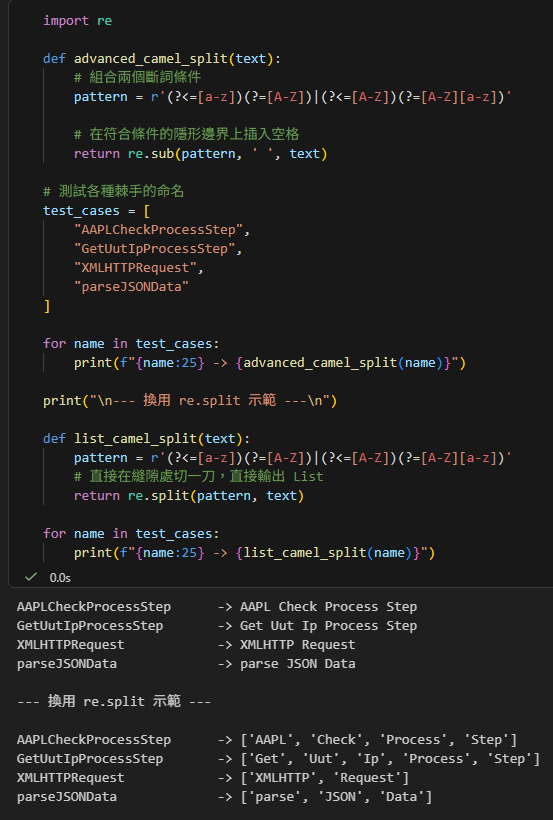
📝 教學:為什麼 re.split 也能「切縫隙」?
在標準的字串處理中,我們習慣用具體的字元來切割,例如 text.split(',') 用逗號切。但在正規表達式中,re.split() 允許我們把「隱形邊界(零寬度)」當作下刀的位置。
1. 什麼是「零寬度 (Zero-width)」?
我們使用的 Regex (?<=[a-z])(?=[A-Z]) 是由 Lookbehind(回溯向後看)與 Lookahead(前瞻向前看)組成的。
這段寫法沒有捕捉任何實體字母,它只捕捉「右邊是大寫、左邊是小寫」的那個虛擬卡榫(縫隙)。
2. re.sub vs re.split 的差異
既然都找到了這個「縫隙」,你有兩種做法:
- 做法 A:塞東西進去 (
re.sub)
也就是您上面原本的寫法,把找到的縫隙填入一個實體的空白" ",會得到加工後的新字串"AAPL Check Process Step"。 - 做法 B:直接斬斷 (
re.split)
當re.split()遇到這個縫隙時,它會直接從該處把字串一分為二(或多份),並直接回傳一個 List。這免去了您先用re.sub塞空白,事後又要呼叫.split(' ')的兩道工序。
3. 陷阱:如果你加了外層括號 ()
在 re.split() 中有一個特殊規則:如果你在 Regex 裡面使用了實體的捕獲群組 (),切割時會把「被當作刀子的那個字串」也一起保留在 List 結果裡。
但因為我們使用的是 (?<=...) 和 (?=...) 這種非捕獲的零寬度斷言,它本身就是空氣,所以切出來的 List 看起來非常乾淨:['AAPL', 'Check', 'Process', 'Step']
總結:
當你需要最終結果是「字串(例如供前端顯示)」,用 re.sub 補空白;
當你需要最終結果是「陣列(例如供模型做 Tokenization 餵資料)」,直接用 re.split 效能最好,最乾脆!
推薦hahow線上學習python: https://igrape.net/30afN
![Python: pandas.Series如何只保留str,去除重複值?#isinstance(x:Any, str) -> bool #.drop_duplicates() #Series.apply( function )逐元素應用function運算 #DataFrame.apply( function )逐Series應用function運算 .drop_duplicates() 跟.unique()有何差別? df.drop_duplicates() 等效於 df[~df.duplicated()]](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2024/11/20241123194900_0_5218de.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: pandas.Series如何只保留str,去除重複值?#isinstance(x:Any, str) -> bool #.drop_duplicates() #Series.apply( function )逐元素應用function運算 #DataFrame.apply( function )逐Series應用function運算 .drop_duplicates() 跟.unique()有何差別? df.drop_duplicates() 等效於 df[~df.duplicated()]")
 ; re.search() ; re.findall() ; re.fullmatch() 有何差別?")
")

與.cget()的差別為何? #configuration ; entry_widget.get() ; label_widget.cget(“text”) ; label_widget = tk.Label( window, text = “Hello, World!”)")
,列高不同之下拉設定")
 ; s.index ; s.values; 類比於dict.keys ; dict.values ; Series有index跟value,可以跟dict互轉;同list的切片可以取值")

![Python, typing: 函數庫規格標註; def addTest(x:float, y:float) -> float: List[資料型態] Set[資料型態] Tuple[資料型態] Dict[str,value的資料型態] Union[資料型態1, 資料型態2] ,函式若有多個輸出值,其實是輸出一個tuple](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2022/09/20220907154601_86.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python, typing: 函數庫規格標註; def addTest(x:float, y:float) -> float: List[資料型態] Set[資料型態] Tuple[資料型態] Dict[str,value的資料型態] Union[資料型態1, 資料型態2] ,函式若有多個輸出值,其實是輸出一個tuple")
![Python 表達式中的魔法:用海象運算子讓斷詞程式碼更乾淨 [w_clean for w in words if (w_clean:=w.lower().strip()) and w_clean not in STOPWORDS] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2026/02/20260210083748_0_a7d9bf-520x245.png)
![Python: 如何判斷字符串內容是否為數字(整數或浮點數)? isinstance( eval( entry.get() ), (float, int) ) ; str.isdigit() #不包括小數點和負號 ; try~ except ValueError~ ; 正則表示法 regular expression ; pattern = '^[-+]?[0-9]*.?[0-9]+([eE][-+]?[0-9]+)?$' - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/05/20230512152430_3-520x245.png)

近期留言