pandas如何去掉空列/空欄? 如何重置DataFrame的index/欄標籤?
前一篇文章處理的資料如下
(已經先dropna刪除空列/空欄):
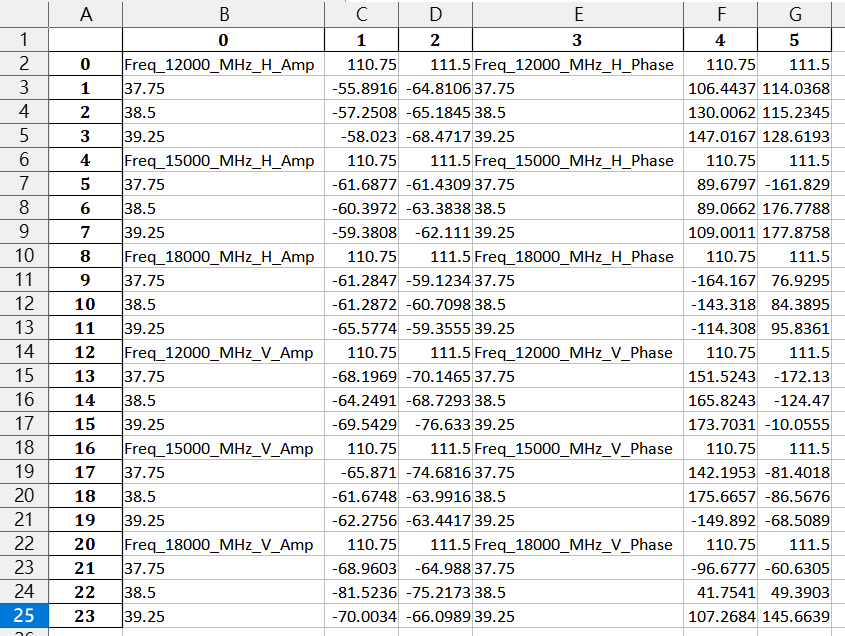
需要對資料做.iloc[切片]
要如何快速找到要切割的位置?
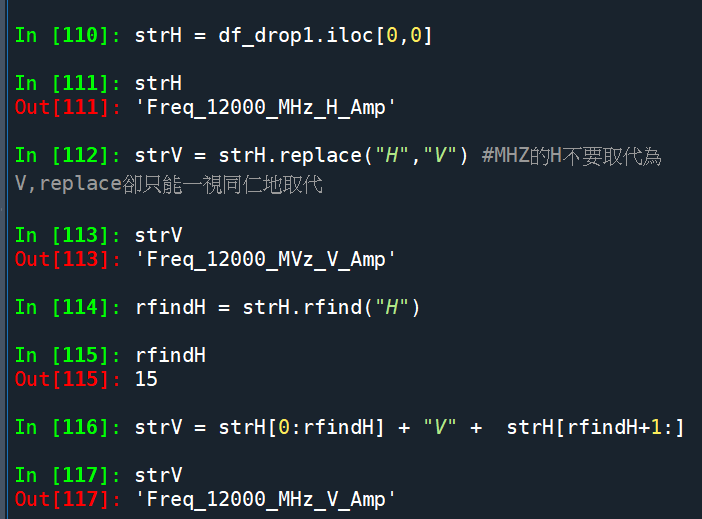
for i in range( len(dfRaw_drop1) ):
if df_drop1.iat[i,0] == strV: splitV=i
其他技巧,利用關鍵字”Hz”
把不同頻率的資料都切開
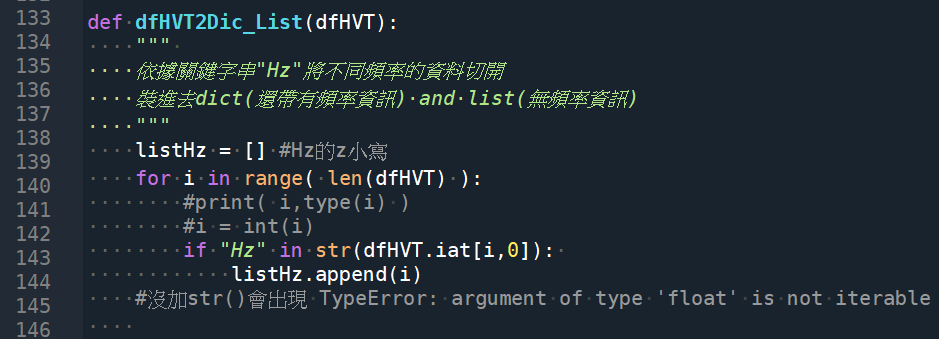
listHz = [] #Hz的z小寫
for i in range( len(dfHVT) ):
#print( i,type(i) )
#i = int(i)
if “Hz” in str(dfHVT.iat[i,0]):
listHz.append(i)
#沒加str()會出現 TypeError: argument of type ‘float’ is not iterable
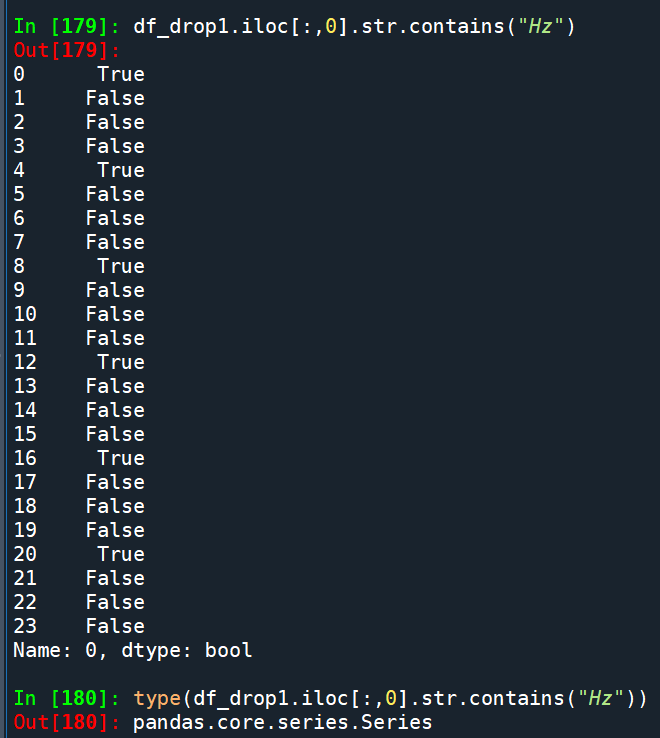
或者使用pandas的功能
df_drop1.iloc[:,0].str.contains(“Hz”)
df_drop1:

df_drop1.iloc[:,0].str.contains(“Hz”)
# “Hz”可以替換為正則表示法
# type(df_drop1.iloc[:,0].str.contains(“Hz”))
# pandas.core.series.Series
bool_list = df_drop1.iloc[:,0].str.contains(“Hz”).to_list()
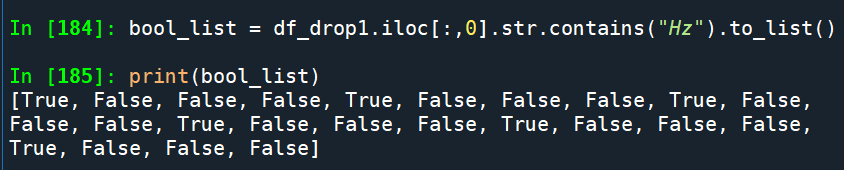
bool_list中的元素若 == True:
將該元素的index
append進去listHz中
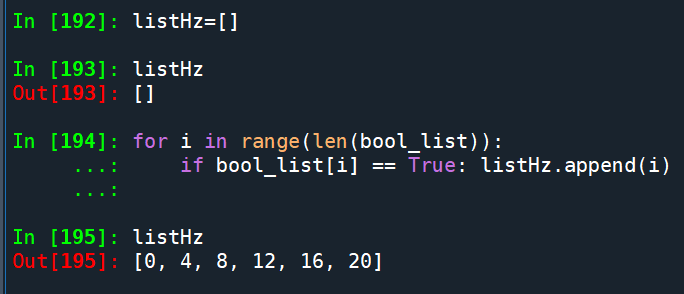
為了切片到最後一個DF
listHz需要append 最後一個元素last
last = listHz[-1] + listHz[1] – listHz[0]
如果想要strip()後,再lower():
ser_process_name.str.strip().str.lower()
#需要兩次.str
若要比對Series與另外一份文件內容
最好都要做這個動作
以免因為首末的空格或大小寫
比對為False
推薦hahow線上學習python: https://igrape.net/30afN
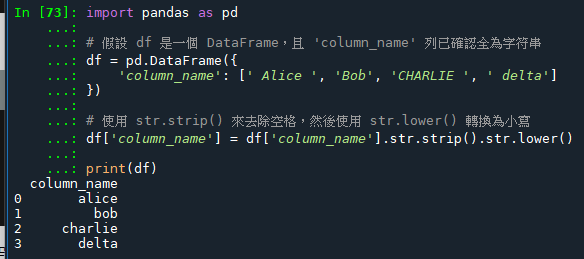
如果你已經確保了 pandas 的 Series 中的所有元素都是字符串類型(str type),那麼連續使用 .str.strip().str.lower() 是完全沒問題的,這不會導致錯誤。
下面是一個示例,展示了如何在確保所有元素都為字符串後連續使用 .str.strip() 和 .str.lower() 方法:
在使用 Pandas 的 .str 方法链式调用时,如果忘记在每个字符串方法前加上 .str,这会导致错误。每个字符串操作(如 .strip(), .lower(), .upper(), 等)都必须通过 .str 访问器来调用,因为这些方法是定义在 StringMethods 类上的,而这个类是通过 .str 属性暴露给 Series 的。
示例说明
当您尝试执行 .str.strip().lower() 时,以下是发生的情况:
.str.strip()正确执行,因为.strip()是通过.str调用的,它作用于 Series 中的每个字符串元素,去除两端空格。- 接下来,
.lower()尝试直接在 Series 上执行,而不是字符串上。由于.lower()不是 Series 对象的方法,这会抛出一个 AttributeError。
这里是一个具体的错误示例:
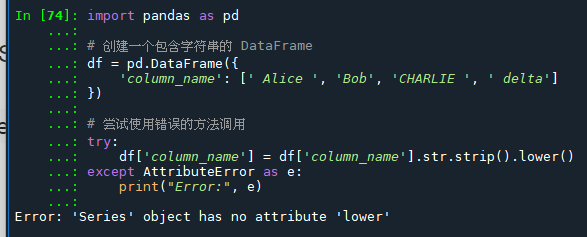
这段代码会抛出一个错误,因为在执行 .lower() 时,它不是在单个字符串上执行,而是尝试在经过 .str.strip() 处理后返回的 Series 上执行。Series 对象没有 .lower() 方法,这导致 AttributeError。
正确的方法
每次调用字符串操作方法时,都应使用 .str:
df['column_name'] = df['column_name'].str.strip().str.lower()
这样,每个操作都正确地应用于 Series 中的每个字符串元素,避免了错误。
推薦hahow線上學習python: https://igrape.net/30afN
在 Pandas 中,.str.contains() 和 .str.match() 是用于处理字符串的两种不同的方法,它们用于不同的匹配需求:
.str.contains(pat):检查每个元素是否包含模式pat。这个方法返回一个布尔型 Series,表示每个元素是否包含指定的模式。.str.match(pat):检查每个元素是否在字符串的开始位置匹配模式pat。这个方法同样返回一个布尔型 Series,但它只在字符串起始处查找匹配。
下面通过一个示例来展示如何使用这两个方法。假设我们有一个包含频率数据的 DataFrame,我们要找出包含 “Hz” 和以 “Hz” 开头的字符串。
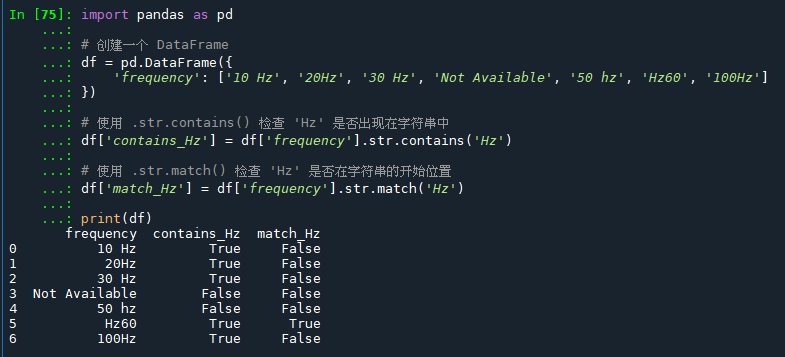
如您所见:
contains_Hz列显示了Hz是否在各元素中出现。match_Hz列显示了元素是否以Hz开始。
注意
.str.contains()和.str.match()默认区分大小写。如果需要进行大小写不敏感的匹配,可以传递case=False参数。- 这些方法可以接受正则表达式,增加匹配的灵活性。
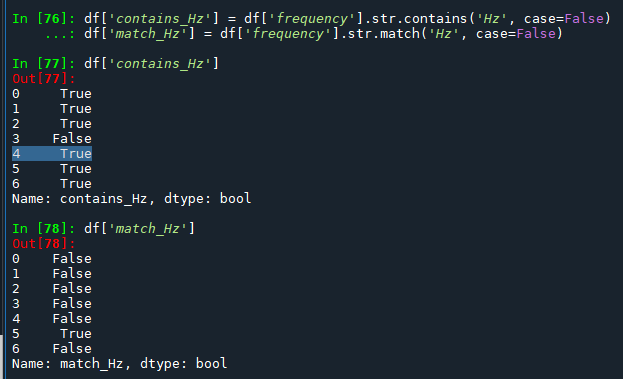
例如,如果想要大小写不敏感的匹配,可以修改调用方式:
df['contains_Hz'] = df['frequency'].str.contains('Hz', case=False)
df['match_Hz'] = df['frequency'].str.match('Hz', case=False)
推薦hahow線上學習python: https://igrape.net/30afN
套件處理pdf文件?如何搜尋有指定標題的頁面,抓取該頁的所有圖片?")

與tuple, set, issubset(), issuperset()")


.resolve().parent")
字串與字串的對齊{:8.2f}預設靠右, {:<8.2f}靠左,{:>8.2f}靠右,{:^8.2f}置中,{:=^10s}”.format(“傳說中的分隔線”) ; print(f”{s:=<10}\") ; \"傳說中的分隔符號\".center(40, \"=\")")
 對二進位數據打包、解包 data = struct.pack (format_str, 1, 2, 3.14) ; result = struct.unpack (format_str, data) ; numpy.fromfile() ;")



近期留言