## 1. 先理解 PyMuPDF 抽出的 PDF 文字結構
在 `my_pdf2text_08.py` 裡,文字抽取的起點是:
text_dict = page.get_text("dict")其中 `page` 是 PyMuPDF 的 `fitz.Page` 物件,
也就是一頁 PDF。
`page.get_text(“dict”)` 會把這一頁的文字
整理成巢狀 dict/list 結構。大致是:
text_dict = page.get_text("dict") # type(page) is pymupdf.Page / fitz.Page
-> blocks: list[dict]
-> block: dict
keys: ['number', 'type', 'bbox', 'lines']
-> lines: list[dict]
-> line: dict
keys: ['spans', 'wmode', 'dir', 'bbox']
-> spans: list[dict]
-> span: dict
keys: [
'size', 'flags', 'bidi', 'char_flags', 'font', 'color',
'alpha', 'ascender', 'descender', 'text', 'origin', 'bbox'
]所以 PDF 文字不是一開始就等於 Excel 的 row。
它比較像這樣:
page
-> text_dict
-> text blocks
-> text lines
-> text spans這也是為什麼程式後來會命名成:
– `page_blocks`
– `page_lines`
– `page_spans`
– `text_block_count`
因為這些名稱是在對齊
PyMuPDF 實際回傳的 PDF 文字階層。
## 2. 為什麼 PageExtraction 要定義這些欄位?
`PageExtraction` 是 iterator 每處理一頁 PDF 時產生的 page-level 資料包。
它把同一頁中抽到的文字與表格結果集中在一起,
方便後面的 `write_pdf_workbook()` 一頁一頁寫入 Excel。
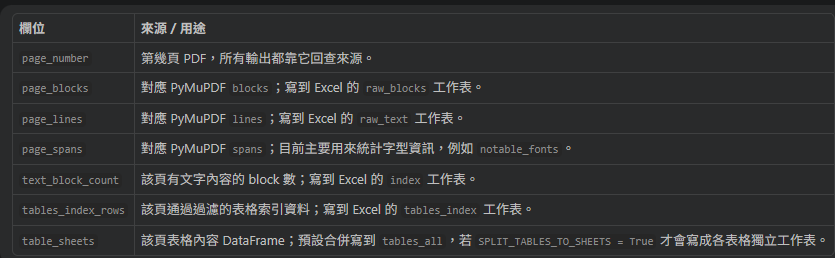
目前的欄位是:
class PageExtraction(NamedTuple):
page_number: int
page_blocks: List[Dict[str, Any]]
page_lines: List[Dict[str, Any]]
page_spans: List[Dict[str, Any]]
text_block_count: int
tables_index_rows: List[Dict[str, Any]]
table_sheets: List[Tuple[str, pd.DataFrame]]這裡的 `sheet` 指的是同一個 Excel `.xlsx` 檔裡的工作表分頁,
也就是 Excel 底下可以切換的 tab,不是另一個檔案。
目前預設 `SPLIT_TABLES_TO_SHEETS = False`,
所以每個 PDF 輸出的 Excel 大致會有:
– `index`
– `raw_blocks`
– `raw_text`
– `tables_index`
– `tables_all`
只有把 `SPLIT_TABLES_TO_SHEETS` 改成 `True` 時,
才會額外把每個表格輸出成獨立的表格分頁。
欄位和 PDF / Excel 輸出的關係如下:
換句話說,先理解 `page.get_text(“dict”)` 的階層,
才會知道為什麼不是只用一包扁平文字資料,
而是分成 `page_blocks`、`page_lines`、`page_spans`。
## 3. NamedTuple 是什麼?
`NamedTuple` 可以把「一組固定欄位的資料」
包成一個有名字的 tuple-like class。
在 `my_pdf2text_08.py` 裡:
class PageExtraction(NamedTuple):
page_number: int
page_blocks: List[Dict[str, Any]]
page_lines: List[Dict[str, Any]]
page_spans: List[Dict[str, Any]]
text_block_count: int
tables_index_rows: List[Dict[str, Any]]
table_sheets: List[Tuple[str, pd.DataFrame]]這段的意思是建立一個叫
`PageExtraction` 的資料類型。
它每一筆資料固定包含:
– `page_number`
– `page_blocks`
– `page_lines`
– `page_spans`
– `text_block_count`
– `tables_index_rows`
– `table_sheets`
所以這段不是普通變數宣告,
而是在宣告 `PageExtraction` 這個資料包的欄位結構。
## 4. 為什麼用 class 語法?
`NamedTuple` 支援兩種寫法。
第一種是 class 寫法:
class Employee(NamedTuple):
name: str
id: int第二種是 function 寫法:
Employee = NamedTuple("Employee", [("name", str), ("id", int)])兩者概念接近。
在 Jupyter / Notebook 裡可以這樣測:
from typing import NamedTuple
class Employee(NamedTuple):
name: str
id: int
employee = Employee(name="Alice", id=1001)
employee輸出會像這樣:
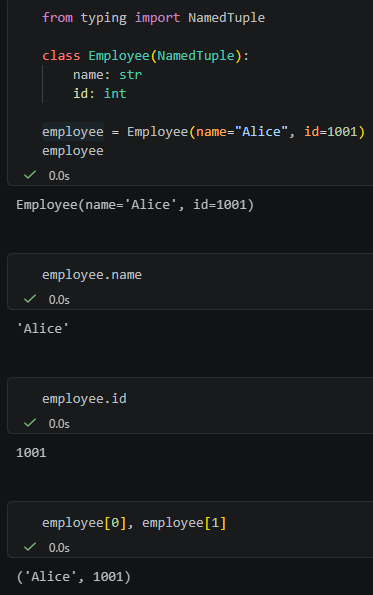
雖然它底層像 tuple,但可以用欄位名稱取值:
“`python
employee.name
“`
輸出:
“`text
‘Alice’
“`
“`python
employee.id
“`
輸出:
“`text
1001
“`
也仍然可以用 tuple 的位置取值:
“`python
employee[0], employee[1]
“`
輸出:
“`text
(‘Alice’, 1001)
“`
如果改用 function 寫法,效果也一樣:
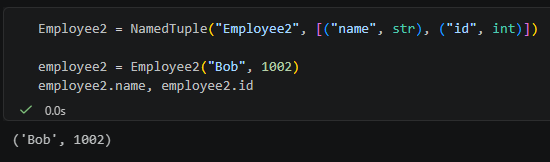
Employee2 = NamedTuple("Employee2", [("name", str), ("id", int)])
employee2 = Employee2("Bob", 1002)
employee2.name, employee2.id輸出:
class 寫法比較像一般 Python 類別,
也比較容易加型別註解、註解文字、預設值,
所以現在程式用 class 寫法是合理的。
## 5. 它跟一般 class 有什麼不同?
一般 class 通常要自己寫 `__init__()`:
class PageExtraction:
def __init__(self, page_number, page_blocks, page_lines):
self.page_number = page_number
self.page_blocks = page_blocks
self.page_lines = page_lines`NamedTuple` 會自動幫你產生初始化介面:
page_extraction = PageExtraction(
page_number=1,
page_blocks=[],
page_lines=[],
page_spans=[],
text_block_count=0,
tables_index_rows=[],
table_sheets=[],
)讀取時可以用欄位名稱:
page_extraction.page_number
page_extraction.page_lines也可以像 tuple 一樣用位置取值:
page_extraction[0] # page_number
page_extraction[1] # page_blocks但一般情況建議用欄位名稱讀,因為比較不容易看錯。
## 6. 可以寫 `page_number: int = -1` 嗎?
可以,但有一個重要限制。
在 `NamedTuple` 裡,
有預設值的欄位必須放在沒有預設值的欄位後面。
例如這樣不可以:
class PageExtraction(NamedTuple):
page_number: int = -1
page_blocks: List[Dict[str, Any]]
page_lines: List[Dict[str, Any]]原因是 `page_number` 已經有預設值,
但後面的 `page_blocks`、`page_lines` 沒有預設值。
Python 會視為類似這種 function 參數錯誤:
def func(page_number=-1, page_blocks):
pass這在 Python 是不合法的,
因為「沒有預設值的參數」
不能放在「有預設值的參數」後面。
## 7. 正確的預設值寫法
如果只想讓 `page_number` 有預設值,可以把它放到最後:
class Example(NamedTuple):
page_blocks: List[Dict[str, Any]]
page_lines: List[Dict[str, Any]]
page_number: int = -1但這對 `PageExtraction` 不太適合,
因為 `page_number` 是最重要的定位欄位,
放第一個比較好讀。
另一種做法是所有後面的欄位也都給預設值:
class PageExtraction(NamedTuple):
page_number: int = -1
page_blocks: List[Dict[str, Any]] = []
page_lines: List[Dict[str, Any]] = []
page_spans: List[Dict[str, Any]] = []
text_block_count: int = 0
tables_index_rows: List[Dict[str, Any]] = []
table_sheets: List[Tuple[str, pd.DataFrame]] = []但這種寫法不建議,因為 list 是 mutable object。
多個 instance 可能共享同一個預設 list,容易埋 bug。
## 8. 那 PageExtraction 要不要給預設值?
目前不建議。
現在的 `PageExtraction` 是
iterator 每處理一頁時產生的完整資料包:
yield PageExtraction(
page_number=page_number,
page_blocks=page_blocks,
page_lines=page_lines,
page_spans=page_spans,
text_block_count=text_block_count,
tables_index_rows=tables_index_rows,
table_sheets=table_sheets,
)這些欄位都應該由抽取流程明確給值。
如果 `page_number` 預設為 `-1`,
反而可能讓漏傳 `page_number` 的錯誤被藏起來。
目前比較好的策略是:
“`text
PageExtraction 每個欄位都必填。
沒有資料時傳空 list 或 0。
不要讓 page_number 靠 -1 補洞。
“`
## 9. 什麼時候應該改成 dataclass?
如果只是單純傳資料,
`NamedTuple` 很適合。
如果之後想要:
– 欄位可修改
– 使用 `default_factory=list`
– 加 method
– 更像一般物件
可以改成 `dataclass`:
from dataclasses import dataclass, field
@dataclass
class PageExtraction:
page_number: int = -1
page_blocks: List[Dict[str, Any]] = field(default_factory=list)
page_lines: List[Dict[str, Any]] = field(default_factory=list)
page_spans: List[Dict[str, Any]] = field(default_factory=list)
text_block_count: int = 0
tables_index_rows: List[Dict[str, Any]] = field(default_factory=list)
table_sheets: List[Tuple[str, pd.DataFrame]] = field(default_factory=list)`dataclass` 對 mutable 預設值比較安全,
因為可以用 `field(default_factory=list)`
讓每個 instance 都拿到自己的新 list。
## 10. 結論
`NamedTuple` 雖然用 class 語法寫,但它不是一般 class。
它的重點是:
“`text
用 class 名稱建立一個 namedtuple 類型。
class body 裡的 annotation 變成欄位名稱與型別提示。
Python 自動產生初始化方法。
欄位通常不可重新指派。
適合固定結構、單純傳遞資料的場景。
“`
以目前 `PageExtraction` 的用途來說,
它是 iterator 傳給 writer 的 page-level 資料包,
因此使用 `NamedTuple` 合理。
但 `page_number: int = -1` 不建議加在目前位置;
如果真的需要很多預設值,
通常代表可以考慮改成 `dataclass`。
推薦hahow線上學習python: https://igrape.net/30afN
![Python: matplotlib繪製出的圖表如何插入背景圖? img = plt.imread(‘background_image.png’) ; ax.imshow(img, extent=[0, 10, -1.2, 1.2], aspect=’auto’, alpha=0.5)](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2023/02/20230216183536_29.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: matplotlib繪製出的圖表如何插入背景圖? img = plt.imread(‘background_image.png’) ; ax.imshow(img, extent=[0, 10, -1.2, 1.2], aspect=’auto’, alpha=0.5)")
 ; dot.attr(rankdir=’TB’, size=’10,15′) #”TB”: Top to Bottom, 從上而下的佈局")
 ; np.hstack(tuple) ; ravel(“F”) #解開(線團等),把二維array轉成一維")
的函式.rfind() .replace() 切片與串接; 如何尋找直欄中,含有特定關鍵字的列數? pandas.Series.str.contains(“Hz”) ;如何將Series中的內容去掉首末的空格並小寫? pandas.Series .str.strip() .str.lower() #需要兩次.str")
![Python PyMuPDF fitz 教學:從pdf中抓文字、抓 fonts、抓表格; pip install PyMuPDF ; import fitz ; text_dict = page.get_text(“dict”) #type(page) is pymupdf.Page ; blocks:list[dict] = text_dict[‘blocks’] ; page.find_tables().tables [0].extract() ;如何判斷粗體字?](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2026/05/20260527141829_0_5a8a75.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python PyMuPDF fitz 教學:從pdf中抓文字、抓 fonts、抓表格; pip install PyMuPDF ; import fitz ; text_dict = page.get_text(“dict”) #type(page) is pymupdf.Page ; blocks:list[dict] = text_dict[‘blocks’] ; page.find_tables().tables [0].extract() ;如何判斷粗體字?")
")
 排序,參數key = lambda 匿名函式 ;物件導向 def __repr__(self): #原形畢露; def __str__(self): #給人閱讀")
非貪婪模式(.*?) or (.+?),取出以下字串所有被雙引號包圍的部分?response: addr=”0000:01:00.0″ vid=”0x144d” did=”0xa826″ svid=”0x144d” sid=”0xab4c” speed=”16.0GT/s” width=”x4″ max_width=”x4″ expected_width=”x4″ expected_speed=”16.0GT/s” devpath=”/phys/SB_CAB0/DOWNLINK/U2_15:device:nvme:nvme”")


近期留言