Spyder終端機:
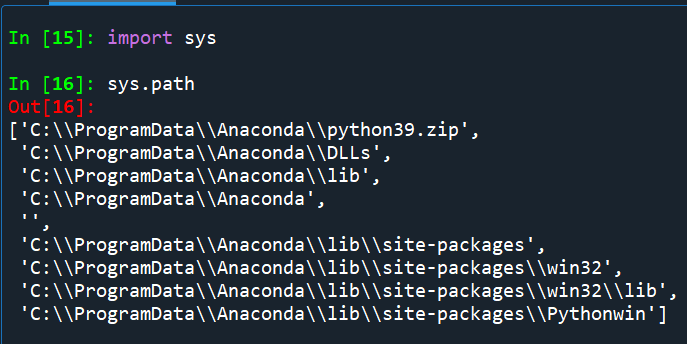
路徑:
C:\ProgramData\Anaconda
(\\改為\)
Windows:
開始>設定>
系統>關於>
進階系統設定>
環境變數>
Path新增上面查到的路徑(\\改為\)
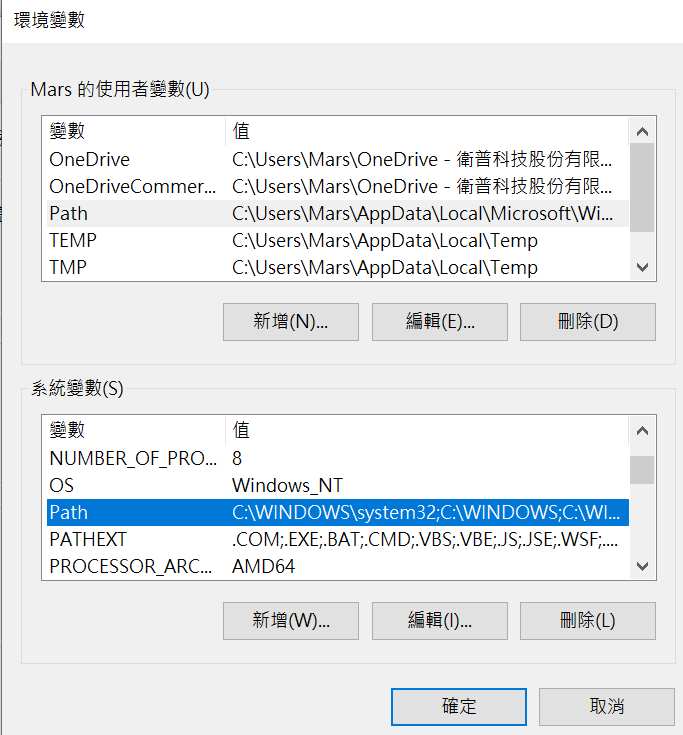
Windows11:
開始>設定>
系統>系統資訊>
進階系統設定>
環境變數>
CMD mode底下執行 set PATH=
可以暫時設定路徑(切換舊版python)
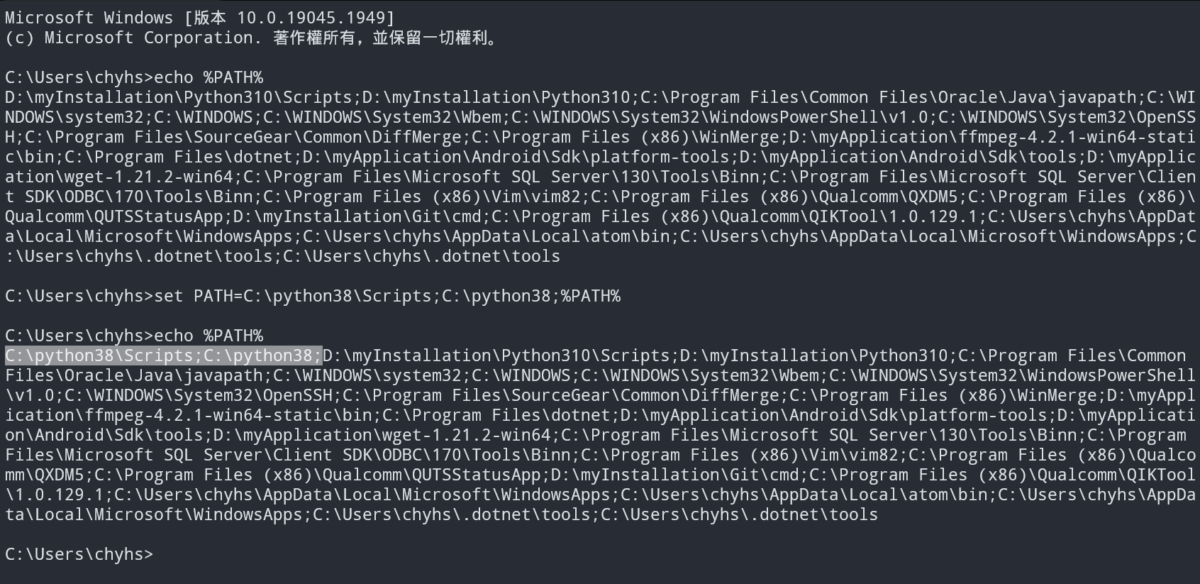
set PATH 照理說應該是不能用,
如果能用,應該是剛好
用的模組的 PATH 與
PYTHONPATH 有重疊到的關係
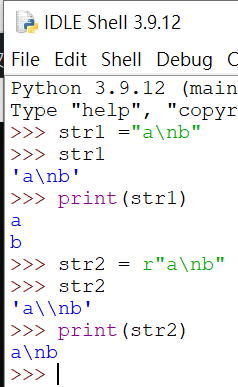
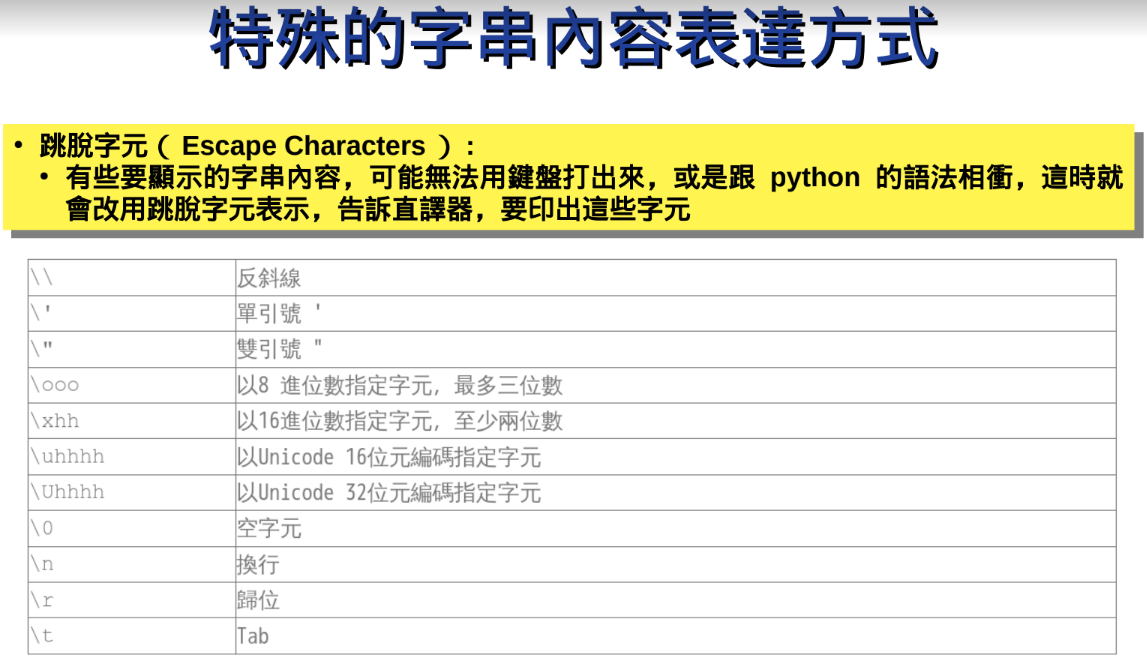
字串前方加一個 r 是一個特殊的字串前輟旗標,代表要求直譯器以 raw string 的方式解析目前的字串內容,換句話說包括跳脫字元等的解析都會被忽略。因此以下兩個字串,是等價的喔:
strr1 = “\\n”
#Python的字串中輸入\\,輸出\,
#輸入%%,輸出%
strr2 = r”\n”
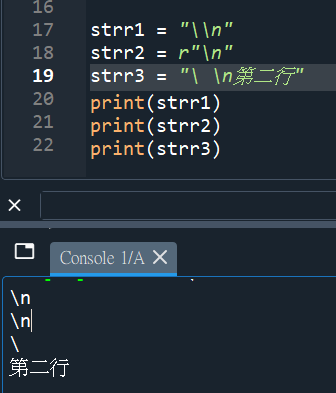
\220 的部份,簡單來說在 str 中,這個是跳脫字元無誤,
220 是八進位,換算成 16 進位的話是 \x90
\x90 目前在 ASCII 表格是空的
有無加r旗標:
跳脫字元:
推薦hahow線上學習python: https://igrape.net/30afN
 #文本流輸入輸出封裝器; json.loads(str) 有何差別? 如何跳到文件的一開頭? f.seek(0,0) ; dict的key若重複,後面覆蓋前面")

![Python如何串接OpenAI /Claude /Gemini API自動將大量維修紀錄JSON轉自然語言描述(並避免中斷資料遺失)response = client.chat.completions.create() ; reply = response.choices[0].message.content](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2025/07/20250716084059_0_c5b368.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python如何串接OpenAI /Claude /Gemini API自動將大量維修紀錄JSON轉自然語言描述(並避免中斷資料遺失)response = client.chat.completions.create() ; reply = response.choices[0].message.content")

")
 會判斷為 True , dropna() 也刪不掉")
 ; 如果y是2D的 pandas.DataFrame ; 如何一次加入所有欄標籤當作圖例(legend)的labels? labels= y.columns.tolist() ; ax.legend(lines, labels)")
將 JSON 逐筆自動轉成中文自然語言")
![Python socket連線出現[WinError 10049] 內容中所要求的位址不正確 cmd.exe: ipconfig/all ; TCP/IPv4 vs IPv6](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2022/10/20221028151556_42.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python socket連線出現[WinError 10049] 內容中所要求的位址不正確 cmd.exe: ipconfig/all ; TCP/IPv4 vs IPv6")

![Python TQC考題910 學生基本資料, print(line.decode("utf-8")), if line.decode("utf-8").split()[2] =="0": female += 1 - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/05/20220514163621_72-520x245.png)

近期留言