在 Python 中,jieba 是一個強大的中文分詞工具,
主要用於分詞、詞性標註以及關鍵詞提取。
其中,jieba.analyse.extract_tags() 是一個常用的功能,
用於從文本中提取關鍵詞。
以下是 jieba.analyse.extract_tags() 的詳細教學,
包括基本用法、參數說明和完整範例。
1. 安裝 jieba
如果尚未安裝,可以使用 pip 安裝:pip install jieba
2. jieba.analyse.extract_tags() 的功能
extract_tags() 是 jieba.analyse 模組中的一個方法,
用於基於 TF-IDF 演算法從文本中提取關鍵詞。
3. 語法與參數
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
#是analyse(英式拼法),
#不是analyze(美式拼法)
sentence: 輸入的文本(字符串)。topK: 選擇返回的關鍵詞數量,預設為 20。withWeight: 是否返回每個關鍵詞的權重(TF-IDF 值)。
默認為 False(僅返回關鍵詞)。 allowPOS: 限制關鍵詞的詞性(例如名詞、動詞等)。
默認為空元組 (),表示不限制詞性。
4. 使用範例
4.1 基本用法
提取一段文本中的關鍵詞:
import jieba.analyse
# 輸入文本
text = "機器學習是一門多領域交叉學科,涉及概率論、統計學、逼近論、凸分析、算法複雜度理論等多門學科。"
# 提取文本中的關鍵詞
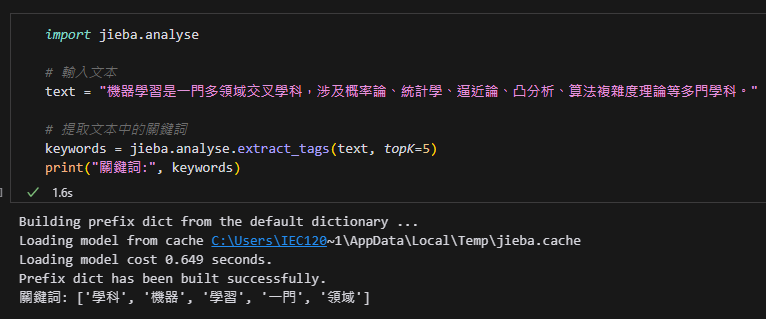
keywords = jieba.analyse.extract_tags(text, topK=5)
print("關鍵詞:", keywords)輸出結果:
4.2 提取關鍵詞及其權重
如果需要獲取每個關鍵詞的權重,可以設置 withWeight=True:
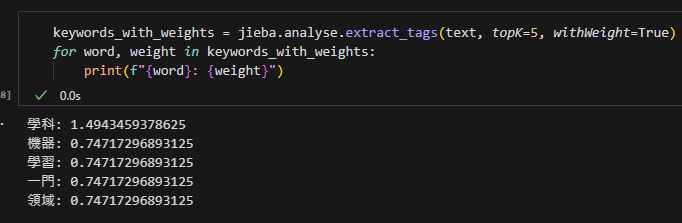
keywords_with_weights = jieba.analyse.extract_tags(text,
topK=5, withWeight=True)
for word, weight in keywords_with_weights:
print(f"{word}: {weight}")輸出結果:
4.3 限制詞性
如果只想提取特定詞性的關鍵詞,例如名詞(n),可以使用 allowPOS 參數。例如:
keywords_nouns = jieba.analyse.extract_tags(text, topK=5,
withWeight=False, allowPOS=('n'))
print("名詞關鍵詞:", keywords_nouns)輸出結果:

詞性標註參考:
n: 名詞v: 動詞a: 形容詞nr: 人名ns: 地名nt: 機構團體名
4.4 自定義停用詞
你可以自定義停用詞列表,過濾掉一些不需要的詞語。例如:
- 創建停用詞文件(
stopwords.txt):

加載停用詞並設置:
import jieba.analyse
# 加載停用詞
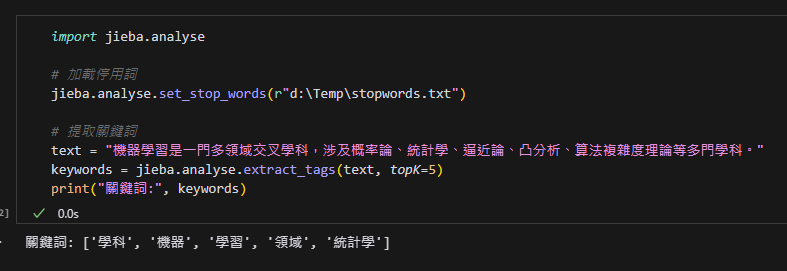
jieba.analyse.set_stop_words(r"d:\Temp\stopwords.txt")
# 提取關鍵詞
text = "機器學習是一門多領域交叉學科,涉及概率論、統計學、逼近論、凸分析、算法複雜度理論等多門學科。"
keywords = jieba.analyse.extract_tags(text, topK=5)
print("關鍵詞:", keywords)輸出結果:
5. 完整範例
以下是一個結合多種功能的完整範例:
import jieba.analyse
# 自定義停用詞
jieba.analyse.set_stop_words(r"d:\Temp\stopwords.txt")
# 測試文本
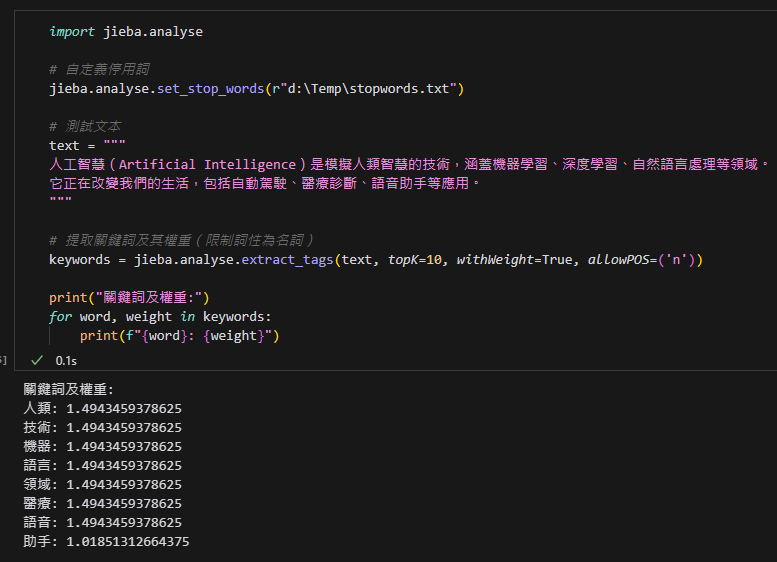
text = """
人工智慧(Artificial Intelligence)是模擬人類智慧的技術,涵蓋機器學習、深度學習、自然語言處理等領域。
它正在改變我們的生活,包括自動駕駛、醫療診斷、語音助手等應用。
"""
# 提取關鍵詞及其權重(限制詞性為名詞)
keywords = jieba.analyse.extract_tags(text, topK=10, withWeight=True, allowPOS=('n'))
print("關鍵詞及權重:")
for word, weight in keywords:
print(f"{word}: {weight}")輸出結果:
List[Tuple[str, float]] #Tuple的長度為2
可以直接轉為dict:
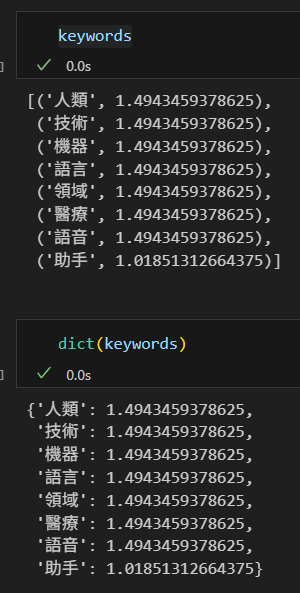
該字典可以用來生成文字雲:
文字雲:

6. 注意事項
- 停用詞的重要性:許多常見詞(如「的」、「是」)可能需要通過停用詞過濾掉,以提升關鍵詞的準確性。
- 文本語料的質量:輸入文本越多、越有意義,提取關鍵詞的準確性就越高。
- 詞性標註的使用:限制詞性可以幫助專注於特定詞類(如名詞)作為關鍵詞。
導入模組的正確方式:
必須使用import jieba.analyse,否則extract_tags()無法使用。
在使用 jieba.analyse.extract_tags() 時,
需要特別注意導入的模組。
雖然 jieba 本身提供分詞功能,
但提取關鍵詞功能位於 jieba.analyse 子模組中。
因此,必須明確導入 jieba.analyse,
否則會導致錯誤。
使用 jieba.analyse.extract_tags() 時,
務必導入 jieba.analyse,否則會導致報錯。
如果只導入 jieba 是無法直接使用 analyse 模組的功能的。
推薦hahow線上學習python: https://igrape.net/30afN
 ; 如何將資料夾中的多個csv檔求平均?")
 ; glob.glob() #讀取資料夾中的所有檔案 ; os.path.split(fpath) = os.path.dirname(fpath) , os.path.basename(fpath) ; os.path.splitext(basename) #分離主/副檔名")
 ; qn(‘w:tbl’) ; qn(‘w:sectPr’)")
")
還是FALSE(0)?你知道為何老是搜尋錯誤嗎?")
? 如何做出計算機? eval() 可將字串還原為python指令")
![Python TQC考題404 數字反轉判斷,n_rev=n[::-1], list1.reverse()](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2022/04/20220825152414_97.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python TQC考題404 數字反轉判斷,n_rev=n[::-1], list1.reverse()")

 完全解析; from docx.oxml import OxmlElement ; from docx.oxml.ns import qn")

近期留言