# -*- coding: utf-8 -*-
"""
Created on Sun Dec 8 12:02:25 2024
@author: SavingKing
"""
from collections import namedtuple
# 定義一個 namedtuple 類型,名為 "Person",並指定字段名
Person = namedtuple('Person', ['name', 'age'])
# 創建三個 Person 實例
alice = Person(name="Alice", age=30)
bob = Person(name="Bob", age=25)
carol = Person(name="Carol", age=27)
# 將這些實例存儲在字典中
people = {
'001': alice,
'002': bob,
'003': carol
}
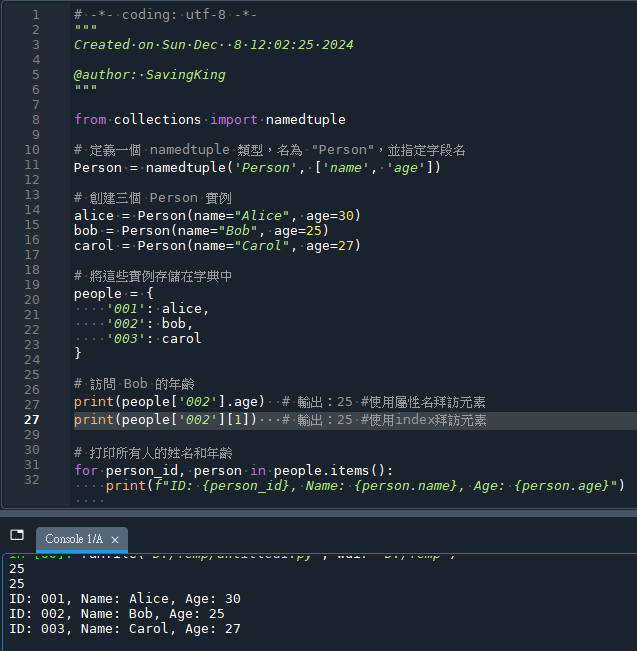
# 訪問 Bob 的年齡
print(people['002'].age) # 輸出:25 #使用屬性名拜訪元素
print(people['002'][1]) # 輸出:25 #使用index拜訪元素
# 打印所有人的姓名和年齡
for person_id, person in people.items():
print(f"ID: {person_id}, Name: {person.name}, Age: {person.age}")
輸出結果
在 Python 編程中,數據組織和結構化是非常重要的概念,特別是當處理覆雜的數據集時。namedtuple,作為標準庫 collections 模塊中的一個功能強大的工具,提供了一種方式來創建類似於元組的對象,但與普通元組相比,它們是可命名的、不可變的,並且可以通過字段名而非索引來訪問,這使得代碼更加直觀和可維護。本教程將向您展示如何在 Dict[str, tuple] 類型的數據結構中利用 namedtuple 來提升數據處理的效率和清晰度。
- 理解 namedtuple
namedtuple 是 Python 中的一個工廠函數,它允許你創建自定義的元組類型,並可以通過屬性而不是索引來訪問元組的元素。這使得代碼不僅更易讀,而且更不容易出錯。
from collections import namedtuple
# 定義一個 namedtuple 類型,名為 "Person",並指定字段(屬性)名
Person = namedtuple('Person', ['name', 'age'])
"""
type(Person)
Out[61]: type
"""在這個例子中,Person 是一個 namedtuple,具有 name 和 age 兩個字段(屬性)。
- 在字典中使用 namedtuple
在很多應用場景中,使用字典來存儲數據是非常常見的。字典提供了一種快速訪問數據的方式,但當字典值為元組時,使用索引訪問數據可能會導致代碼難以理解。使用 namedtuple 可以有效解決這一問題。
示例:創建一個存儲多個人信息的字典
# 創建三個 Person 實例
alice = Person(name="Alice", age=30)
bob = Person(name="Bob", age=25)
carol = Person(name="Carol", age=27)
# 將這些實例存儲在字典中
people = {
'001': alice,
'002': bob,
'003': carol
}訪問字典中的 namedtuple 數據
# 訪問 Bob 的年齡
print(people['002'].age) # 輸出:25 #使用屬性名拜訪元素
print(people['002'][1]) # 輸出:25 #使用index拜訪元素
# 打印所有人的姓名和年齡
for person_id, person in people.items():
print(f"ID: {person_id}, Name: {person.name}, Age: {person.age}")- namedtuple 的優勢
可讀性和可維護性:通過字段(屬性)名訪問數據比通過索引訪問更直觀,更容易維護。
不可變性:namedtuple 是不可變的,這有助於保持數據的一致性和防止被意外修改。
效率:namedtuple 訪問屬性的速度幾乎與常規元組相同,因此它在提供額外功能的同時保持高效。
- 結論
通過在 Dict[str, tuple] 數據結構中使用 namedtuple,您可以顯著提升代碼的整潔度與效率。這不僅使得數據操作更加安全和直觀,還可以幫助其他開發者更快地理解您的代碼,從而降低錯誤的幾率並提升整體的開發效率。是否應用 namedtuple,取決於您對數據訪問的具體需求和場景,但在多數情況下,它都是增強數據結構表達力的優秀選擇。
在 Python 中使用 namedtuple 時,第一個參數通常是這個 namedtuple 類型的名稱。這個名稱是用來定義這個 namedtuple 生成的新類的類型名稱。這個名稱會反映在該 namedtuple 對象的 repr 方法中,使得打印出的對象信息更加清晰易懂。
Person = namedtuple('Person', ['name', 'age'])
這里的第一個參數 ‘Person’ 是指定 namedtuple 類型的名稱,而 Person = 的部分是將這個新創建的 namedtuple 類型賦值給名為 Person 的變量。這兩個 “Person” 用法相關但有不同的含義:
‘Person’(單引號內的字符串)是 namedtuple 類型的名稱,它定義了這個 namedtuple 生成的類的名稱。在 Python 的內部表示中,這個名稱用於識別對象的類型。
Person = 的 Person 是 Python 中的變量名,用於引用你剛剛創建的 namedtuple 類型。
這兩者通常是相同的名稱,這樣做是為了代碼的一致性和可讀性。使得當你查看或打印該對象的類型時,輸出的信息與你賦值的變量名相匹配,從而增加代碼的直觀性和易於理解。但技術上來說,這兩個名稱可以不一樣,例如:
Human = namedtuple('Person', ['name', 'age'])
在這種情況下,namedtuple 創建的類型名稱是 ‘Person’,但是我們用 Human 這個變量來引用它。這是合法的,但可能會導致代碼閱讀上的混淆,因此一般推薦保持這兩個名稱一致。
第一個參數單引號中的Person是類別名稱,
不賦值給任何變數可以嗎?
在 Python 中使用 namedtuple 時,如果您只是調用 namedtuple 函數而不將結果賦值給任何變量,那麽您創建的 namedtuple 類型將無法被引用或使用,因此這樣做通常沒有意義。
例如,如果您執行:
namedtuple('Person', ['name', 'age'])
而沒有將其賦值給變量,那麽雖然一個 namedtuple 類型被創建了,但您沒有任何方式去引用它來創建實例或者進一步使用它。這相當於臨時創建了一個對象但立即讓它無法訪問,因此這個對象會在沒有被任何變量引用的情況下被垃圾回收。
為了能夠使用您創建的 namedtuple 類型,您應該將它賦值給一個變量:
Person = namedtuple('Person', ['name', 'age'])
這樣,您就可以通過 Person 變量來創建 Person 類型的實例,或者進行其他操作,例如:
alice = Person(name="Alice", age=30)
print(alice.name) # 輸出 Alice
print(alice.age) # 輸出 30賦值給變量使得您可以在程序的其他部分引用並使用這個 namedtuple 類型,從而實現數據的組織和操作。所以,雖然技術上可以不賦值給任何變量,但這麽做會使 namedtuple 無法被有效使用。
當您在 namedtuple 中使用的第一個參數(即類名)與賦值給變量的名稱不同時,如下所示:
# 使用 namedtuple 創建一個新類型
Human = namedtuple('Person', ['name', 'age'])在這里,’Person’ 是 namedtuple 創建的新類型的內部名稱,而 Human 是指向這個 namedtuple 類型的變量名。這意味著在 Python 內部,創建的類型被認為是 Person 類型,但我們通過 Human 這個變量來引用和操作這個類型。
創建實例
使用 Human 變量來創建 Person 類型的實例:
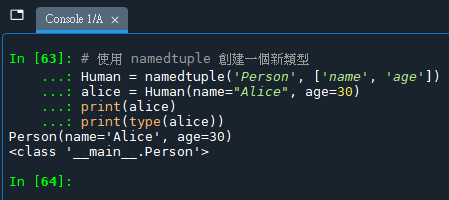
可以看到,盡管變量名是 Human,輸出的實例和類型名稱卻是 Person。這顯示出 namedtuple 函數的第一個參數定義了類型的內部名稱,而不是如何引用它。
為什麽保持名稱一致
保持 namedtuple 類型的名稱和賦值給的變量名稱一致,是為了避免混淆和增強代碼的可讀性。例如:
Person = namedtuple('Person', ['name', 'age'])
bob = Person(name="Bob", age=25)這樣的代碼更直觀,當其他開發者(或未來的您)閱讀代碼時,可以立即理解 Person 不僅是類型的內部名稱,也是引用該類型的變量名。這種一致性有助於維護代碼的清晰性和邏輯一致性。
總的來說,盡管技術上可以使用不同的名稱,但最佳實踐是使用相同的名稱來避免不必要的混淆。這樣做確保了代碼的清晰度和一致性,使得維護和理解代碼更為容易。
namedtuple?
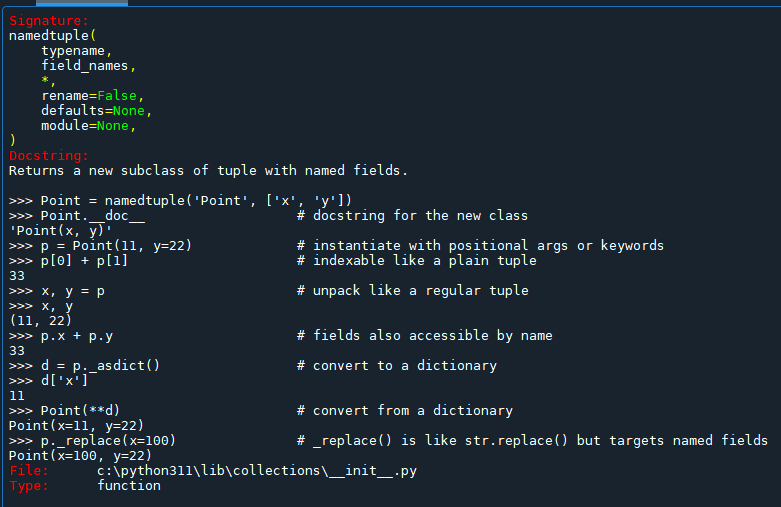
namedtuple 是 Python 的 collections 模塊中一個非常有用的工具,允許您快速地創建一個具有命名字段的元組子類。這種數據結構對於那些希望元組的元素可以通過名字訪問,從而提高代碼可讀性的場景非常有用。下面是關於 namedtuple 的各個參數和方法的中文說明:
namedtuple 的參數:
- typename:新子類的名稱,應為字符串形式,代表類名。
- field_names:字段名,可以是由空格或逗號分隔的單一字符串,或是一個字段名的可迭代對象。這些名稱將用於訪問元組的值。
- rename(可選):如果設為
True,則會自動替換不符合字段名規則的名稱(如以數字開頭或包含特殊字符的名稱),用位置名(如_0、_1等)代替。這在字段名來自外部數據時特別有用。 - defaults(可選):為從最右側開始的字段指定默認值。這可以是默認值的元組或列表。
- module(可選):指定類的
__module__屬性的值。這對於進行序列化或檢查類被定義在哪個模塊中很有用。
方法和特殊功能:
- 索引訪問:可以像普通元組一樣使用索引訪問
namedtuple的元素(例如p[0])。 - 命名訪問:字段也可以通過它們的名稱訪問,這增強了代碼的可讀性(例如
p.x)。 - 解包:像元組一樣,
namedtuple實例可以直接解包到變量中(例如x, y = p)。 - _asdict():將
namedtuple實例轉換為OrderedDict,便於進行 JSON 序列化或更復雜的數據操作。 - _replace():提供一種類似於不可變對象的方法來“替換”字段,返回一個指定字段改變後的新
namedtuple實例。
namedtuple 相比 dict 有以下主要優點:
記憶體效率更高:
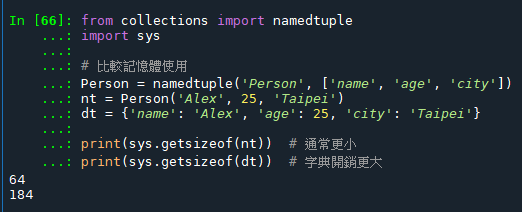
代碼可讀性更好:
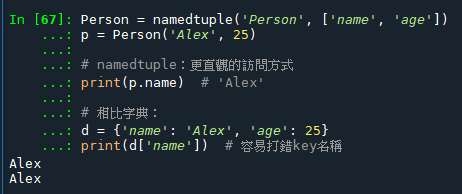
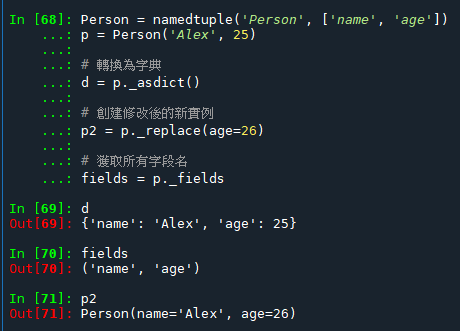
方便的轉換和操作方法:
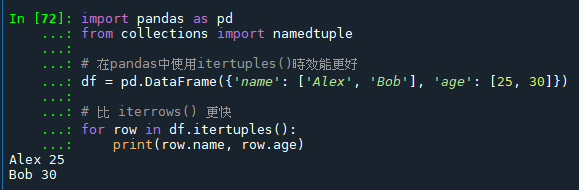
用於數據分析時的效能優勢:
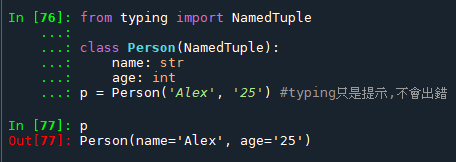
typing.NamedTuple
總結:
- 當需要不可變性時,用namedtuple
- 當需要更好的記憶體效率時,用namedtuple
- 當需要更好的代碼可讀性時,用namedtuple
- 當需要可變數據時,用dict
- 當需要動態添加/刪除鍵值對時,用dict
? 為什麼 np.nan == np.nan 返回 False? numpy.isnan() ; pandas.isna() ; pandas.isnull() ; np.isnan() 只能處理數值型資料(np.nan) ; pd.isna() , pd.isnull() 除了np.nan以外,還可以處理None, pd.DataFrame, pd.Series")
")

 ; 如何將Series依據分隔子(tab與不定數空白混用) 拆分為多欄的DataFrame?")
轉成 AST (Abstract Syntax Tree , 抽象語法樹)並匯出成 JSON; markdown = mistune.create_markdown( renderer=’ast’ )")

![Python: pandas.DataFrame如何移除所有空白列?if df_raw.iloc[r,0] is np.nan: nanLst.append(r) ; df_drop0 = df_raw.drop(nanLst,axis=0) ; pandas.isna() ;df_drop0 = df_raw.drop(nanLst,axis=0).reset_index(drop=True)](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2022/12/20221206144233_67.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: pandas.DataFrame如何移除所有空白列?if df_raw.iloc[r,0] is np.nan: nanLst.append(r) ; df_drop0 = df_raw.drop(nanLst,axis=0) ; pandas.isna() ;df_drop0 = df_raw.drop(nanLst,axis=0).reset_index(drop=True)")
")
 colab如何掛載雲端硬碟?from google.colab import drive; drive.mount( ‘/content/drive’ ) ; 檔案複製shutil.copy() #shell utility; 檔案移動shutil.move( source_file, destination_path); 刪除整個資料夾shutil.rmtree( folder_to_delete ); 刪除某一個檔案os.remove() #shutil.remove()會觸發AttributeError; 如何將檔案路徑拆分為父資料夾與檔案名稱(含副檔名)? os.path.dirname( file_path) ; os.path.basename( file_path) 如何將檔案名稱拆分為主檔名與副檔名? os.path.splitext( file_name) #split(分裂) ext的意思")

近期留言