#Python計算平均值與標準差
#Python 3.X 程式語言特訓教材 6-47頁
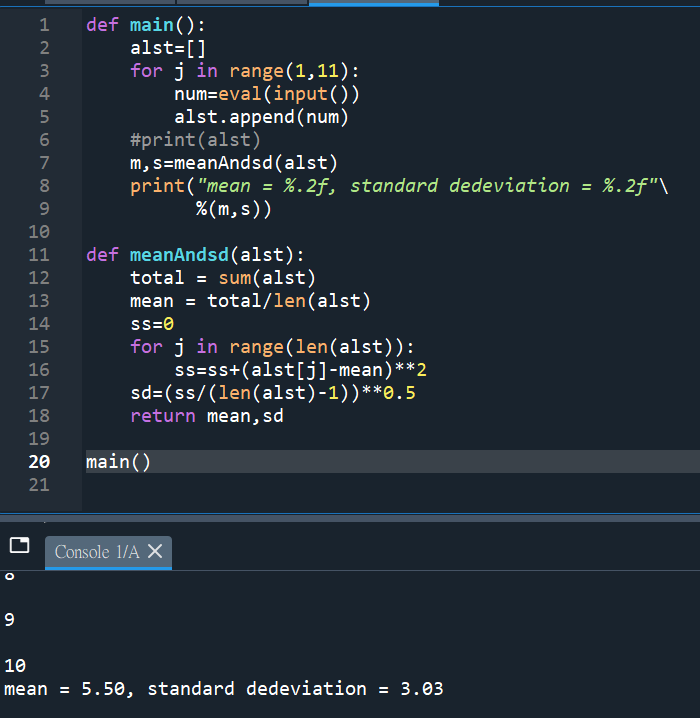
def main():
alst=[]
for j in range(1,11):
num=eval(input())
alst.append(num)
#print(alst)
m,s=meanAndsd(alst)
print(“mean = %.2f, standard dedeviation = %.2f”\
%(m,s))
def meanAndsd(alst):
total = sum(alst)
mean = total/len(alst)
ss=0
for j in range(len(alst)):
ss=ss+(alst[j]-mean)**2
sd=(ss/(len(alst)-1))**0.5
return mean,sd
main()
, loc=’upper left’) ; plt.tight_layout() ; 如何防止儲存的檔案圖例被裁切? plt.savefig(‘example.png’, dpi=300, format=’png’, bbox_extra_artists=(lg,), bbox_inches=’tight’)")
:BFS(Breadth-First Search,廣度優先)層寬統計與 DFS(Depth-First Search,深度優先)Leaf 計數 #遞迴")
")
 ; json的保留字:null, true, false(區分大小寫,全小寫), null(非”null”,非Null)自動轉譯為None, true(非”true”,非True)自動轉譯為True(bool), false(非”false”,非False)自動轉譯為False(bool);colab如何掛載雲端硬碟? from google.colab import drive ; json檔的decode與encode? json.load() ; json.loads() ; json.dump() ; json.dumps() #s代表string的意思,有s的指令,參數需使用str type")
:使用 ignore_index=True 合併 DataFrame 的奧秘 #效果同 reset_index( drop=True )")
 as plt; from pylab import *")
 計算每月應投資金額?送GUI介面程式")

; typing : np.ndarray")
![Python list[] dictionary{key: value},如何從兩個list,建立一個dictionary? - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/09/20220904074100_2-508x245.png)

近期留言