安裝(Windows PowerShell)
py -m pip install -U tqdm1) 套在 range(最簡單)
from tqdm import tqdm
import time
for i in tqdm(range(100), desc="Loop", unit="step"):
time.sleep(0.02) # 模擬工作輸出結果:
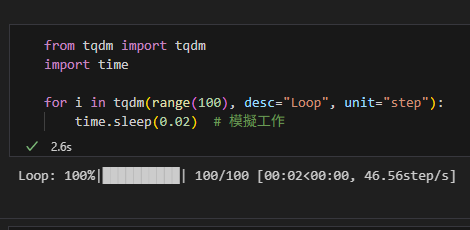
2) 套在任何可迭代物件
from tqdm import tqdm
items = ["a", "b", "c"]
for x in tqdm(items, desc="Processing", unit="item"):
# do_work(x)
pass輸出結果:
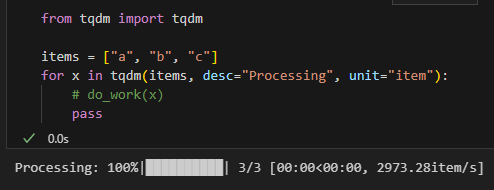
3) 當你不知道總數(手動更新 total / update)
很多人卡在這裡,因為沒有總數或第一筆要很久才出現,看起來就像「一直 0%」。
from tqdm import tqdm
import time
pbar = tqdm(total=3000, desc="API calls", unit="req") # 有總數就先給
for _ in range(3000):
# call_api() # 可能很久才返回
time.sleep(0.05)
pbar.update(1) # 每完成一筆就手動 +1
pbar.close()輸出結果:
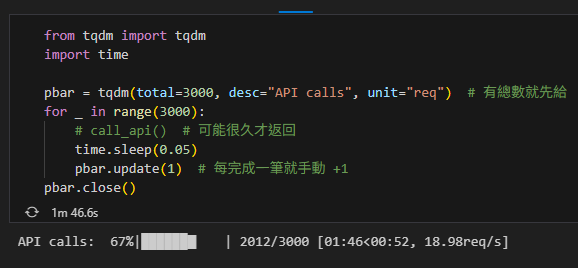
若真的不知道總數,也可以不給 total,僅把 update 當作計數器:
import time
from tqdm import tqdm
def stream():
# 這裡用 generator 模擬逐筆到來的資料(tqdm 看不到總數)
for i in range(37):
time.sleep(0.05)
yield f"item-{i}"
pbar = tqdm(desc="Streaming", unit="item")
for _ in stream():
# 處理一筆...
pbar.update(1)
pbar.close()輸出:
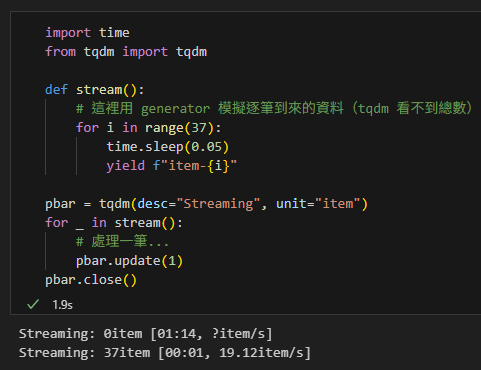
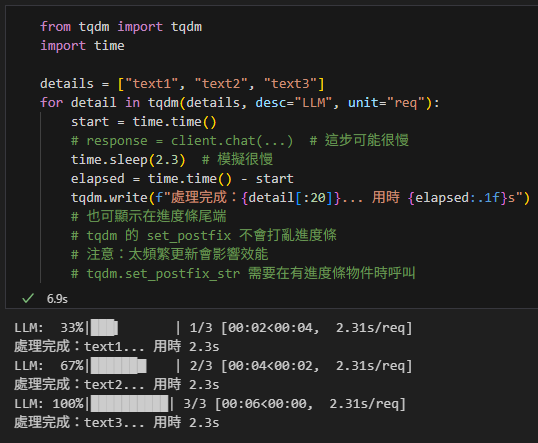
4) 長任務每筆很慢時:顯示進度與狀態
當單筆任務很慢(例如 local LLM),即使有進度條,也會在每筆完成前停在原地。你可以用 set_postfix 顯示即時狀態,減少「卡住」的錯覺。
from tqdm import tqdm
import time
details = ["text1", "text2", "text3"]
for detail in tqdm(details, desc="LLM", unit="req"):
start = time.time()
# response = client.chat(...) # 這步可能很慢
time.sleep(2.3) # 模擬很慢
elapsed = time.time() - start
tqdm.write(f"處理完成:{detail[:20]}... 用時 {elapsed:.1f}s")
# 也可顯示在進度條尾端
# tqdm 的 set_postfix 不會打亂進度條
# 注意:太頻繁更新會影響效能
# tqdm.set_postfix_str 需要在有進度條物件時呼叫輸出:
想在條尾即時顯示資訊(例如每筆用時):
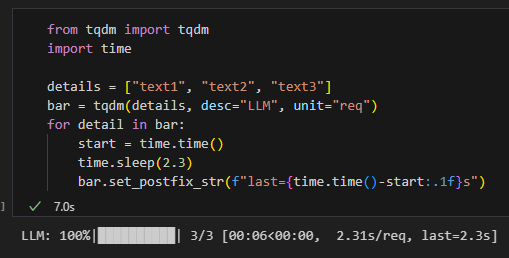
小技巧(更新頻率):如果覺得條更新太慢,可調參數讓它更常刷新
miniters=1 強制每次迭代都嘗試刷新
mininterval=0.1 降低最小刷新間隔(秒)
for x in tqdm(details, desc=”LLM”, unit=”req”, miniters=1, mininterval=0.1): …
for x in tqdm(details, desc="LLM", unit="req", miniters=1, mininterval=0.1):
...5) 巢狀進度條(外層/內層)
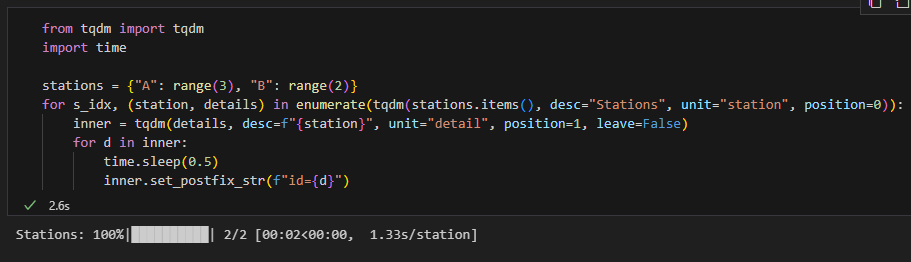
6) 在 Jupyter/Notebook
from tqdm.notebook import tqdm # 更漂亮
for i in tqdm(range(100), desc="Notebook"):
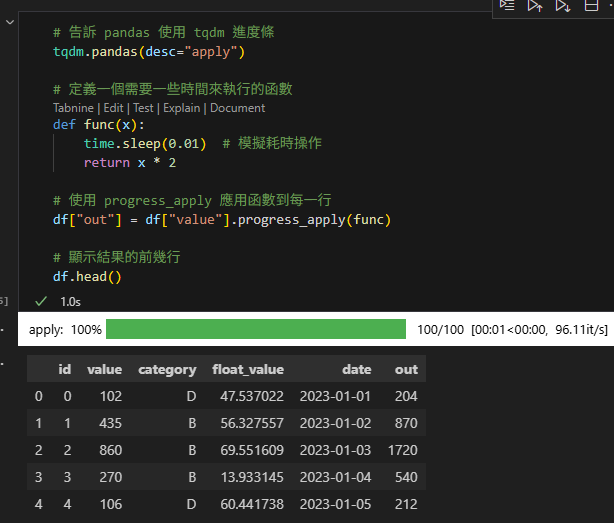
...7) Pandas 一鍵顯示 apply 進度
#from tqdm import tqdm
#tqdm.pandas(desc="apply")
#df["out"] = df["col"].progress_apply(func)
# 導入所需的庫
import time
import pandas as pd
import numpy as np
from tqdm.auto import tqdm
# 設置隨機種子以確保結果一致
np.random.seed(42)
# 創建一個包含示例數據的 DataFrame
# 這裡我們創建一個包含 100 行的 DataFrame,有數值、字符串和日期時間列
# 生成一些隨機數據
n_rows = 100
df = pd.DataFrame({
'id': range(n_rows),
'value': np.random.randint(0, 1000, size=n_rows),
'category': np.random.choice(['A', 'B', 'C', 'D'], size=n_rows),
'float_value': np.random.random(size=n_rows) * 100,
'date': pd.date_range(start='2023-01-01', periods=n_rows)
})
# 顯示 DataFrame 的前幾行
print("DataFrame 的形狀:", df.shape)
df.head()
# 告訴 pandas 使用 tqdm 進度條
tqdm.pandas(desc="apply")
# 定義一個需要一些時間來執行的函數
def func(x):
time.sleep(0.01) # 模擬耗時操作
return x * 2
# 使用 progress_apply 應用函數到每一行
df["out"] = df["value"].progress_apply(func)
# 顯示結果的前幾行
df.head()輸出:
常見問題:為什麼一直 0%?
你的迴圈第一筆就很久(例如等待模型首個回覆)。解法:
若知道總數,先設 total,進度條會先顯示 0/總數。
任務開始就先 tqdm.write 一行狀態,讓你知道程式在跑。
完成一筆就 update/set_postfix,至少能看到「正在處理第 N 筆」與耗時。
print 破壞進度條畫面:用 tqdm.write 取代 print,或用 set_postfix_str。
終端顯示寬度:可用 ncols=80 或 dynamic_ncols=True。
多重進度條重疊:用 position 控制行數,內層 leave=False 結束時不保留。
常用參數速查
desc=”文字”:標題
total=整數:總數
unit=”item”:單位
leave=False:完成後不保留條
ncols=80 / dynamic_ncols=True:寬度
mininterval / miniters:刷新頻率
position=0/1/…:多條時各自位置
colour=”green”:顏色(部分終端支援)
有了這些範例,你可以很快把 tqdm 套進任何慢迴圈,避免「看起來卡住」的焦慮,同時保留乾淨的輸出和基本的效能。
推薦hahow線上學習python: https://igrape.net/30afN
 ; str.isspace() ; str.isalpha()")
![Python如何讀寫csv逗點分隔檔(每列內容為新光增有利現金流)?pandas.read_csv(r”路徑\檔名.副檔名”),如何移除list中的nan元素?math.isnan(),如何計算新光增有利IRR?numpy_financial(array) ;輸出csv檔時如何去掉index跟header?如何選擇要寫入的直欄columns? dfFinal.to_csv(fpath, index=False, header=None, columns=[0,1])](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2022/11/20221110122900_3.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python如何讀寫csv逗點分隔檔(每列內容為新光增有利現金流)?pandas.read_csv(r”路徑\檔名.副檔名”),如何移除list中的nan元素?math.isnan(),如何計算新光增有利IRR?numpy_financial(array) ;輸出csv檔時如何去掉index跟header?如何選擇要寫入的直欄columns? dfFinal.to_csv(fpath, index=False, header=None, columns=[0,1])")
 > Ctrl + shift +F9 取消所有超連結;參考資料>插入索引>自動標記,隱藏標記後,參考資料>插入索引")
 客戶端:Azure、OpenAI 與 Poe 整合指南")
![Python Logging 完全指南:從基礎到實戰應用; import logging ; logging.basicConfig(level=logging.INFO, handlers=[ logging.StreamHandler(), logging.FileHandler(‘app.log’, mode=’a’, encoding=’utf-8′)] ) ; inspect.currentframe().f_code.co_name #動態取得funcName](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2025/10/20251021155823_0_c16012.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python Logging 完全指南:從基礎到實戰應用; import logging ; logging.basicConfig(level=logging.INFO, handlers=[ logging.StreamHandler(), logging.FileHandler(‘app.log’, mode=’a’, encoding=’utf-8′)] ) ; inspect.currentframe().f_code.co_name #動態取得funcName")
 的 keep 參數")


 在不同資料類型(array/dict)下的 columns 參數用法 #賦值 #選擇")


近期留言