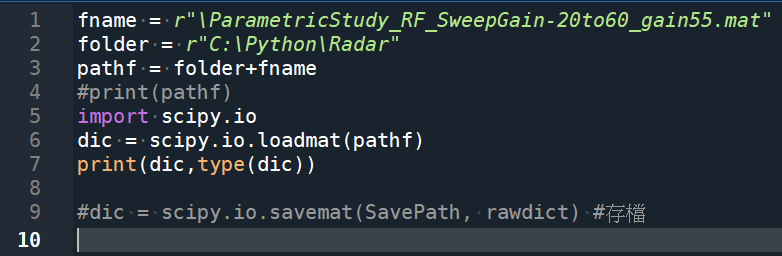
fname = r”\ParametricStudy_RF_SweepGain-20to60_gain55.mat”
folder = r”C:\Python\Radar”
pathf = folder+fname
#print(pathf)
import scipy.io
dic = scipy.io.loadmat(pathf)
print(dic,type(dic))
# scipy.io.savemat(SavePath, rawdict) #存檔
#SavePath = 路徑+檔名+ .mat
部分輸出結果:
")
")
 比對字串相似度並儲存結果")


 as source: audio = r.record(source) ; 如何使用mic當音源? with sr.Microphone() as source: audio_data = recognizer.listen(source)")
")
 同級的「完美縮排」; from lxml import etree ; root = etree.fromstring(xml_bytes) #等效 root = etree.fromstring( xml_str.encode(“utf-8”) ); clean_xml_str = etree.tostring(root, pretty_print=True, encoding=’unicode’, xml_declaration=False) ; import xml.etree.ElementTree as ET")

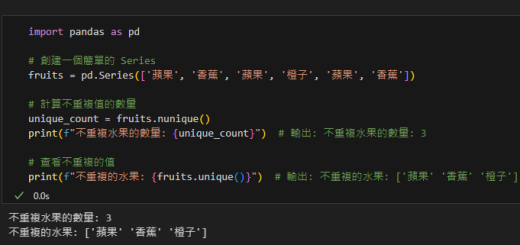

近期留言