import seaborn as sns
# 加载数据
tips = sns.load_dataset(‘tips’)
# 使用 relplot 绘制散点图,并使用 facet_wrap 排列子图
sns.relplot(data=tips, x=’total_bill’, y=’tip’,
hue=’sex’, col=’day’, row=’time’,
facet_kws={‘margin_titles’: True}, height=3,
aspect=1.2).set_axis_labels(‘Total Bill’, ‘Tip’)
sns.relplot(data=tips, x=’total_bill’, y=’tip’,
hue=’sex’, col=’time’, row=’day’,
facet_kws={‘margin_titles’: True}, height=3,
aspect=1.2).set_axis_labels(‘Total Bill’, ‘Tip’)
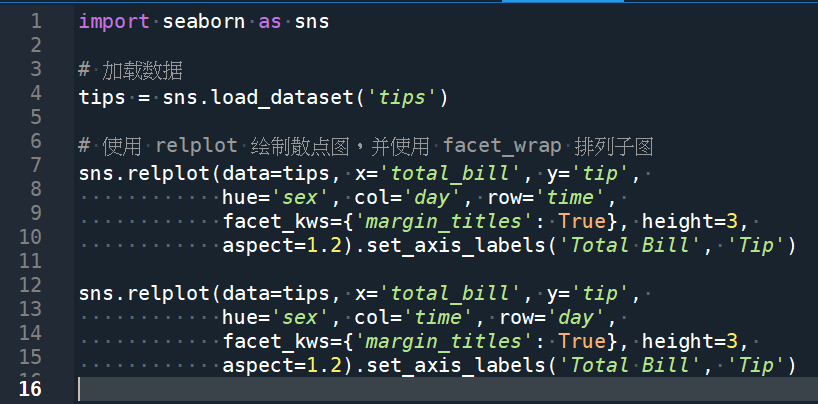
tips(pandas.core.frame.DataFrame):
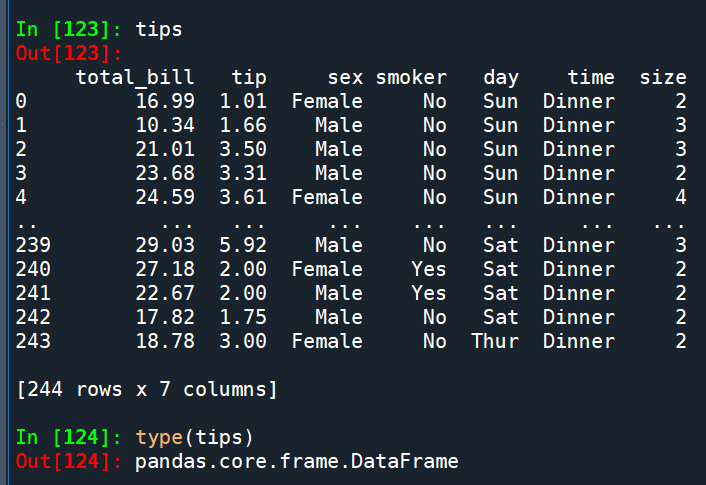
col=’day’, row=’time’
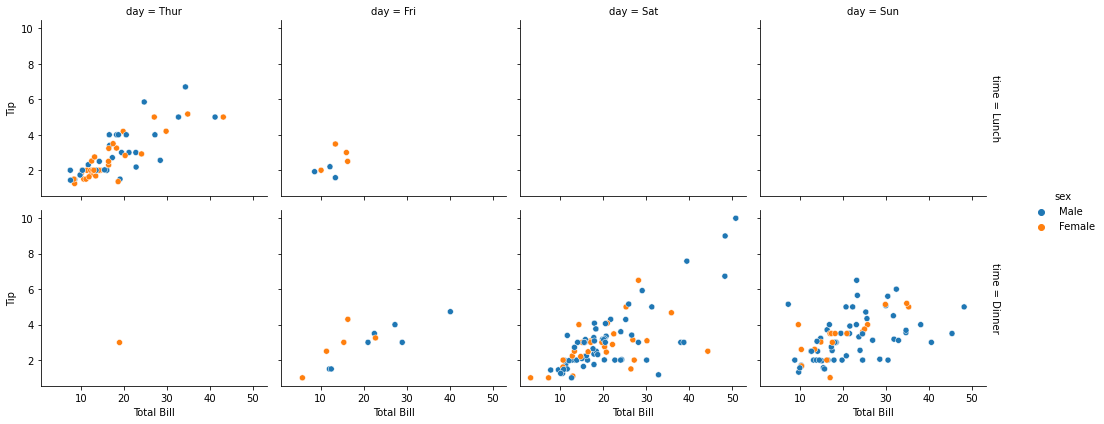
col=’time’, row=’day’
推薦hahow線上學習python: https://igrape.net/30afN

 ) ) ; listbox = tk.Listbox (root, listvariable = menu)")

#只接受2D數據 ; from sklearn.preprocessing import StandardScaler ; 儲存/載入 scaler or model: joblib.dump() / joblib.load()")

 如何萃取關鍵字? import jieba.analyse ; jieba.analyse.extract_tags()")

 與 C3 線性化算; 物件導向:多型")
 與 os.stat() 讀懂檔案資訊; from pathlib import Path ; type(p).__name__ #’WindowsPath’; p.stat().st_size == os.stat(p).st_size == os.path.getsize(p)")
![Python爬蟲: 如何使用Selenium自動打開Chrome瀏覽器,連線在職訓練網,自動輸入資料查詢? #ID選擇器 .類選擇器; "#Form_KEYWORDS" 等效於'[id="Form_KEYWORDS"]' ; ".btn-orange" 等效於 '[class="btn-orange"]' ; 如何結合BeautifulSoup? soup = BeautifulSoup(driver.page_source,"html.parser") - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2024/02/20240212083035_0-520x245.png)


近期留言