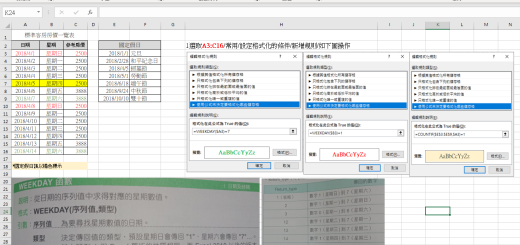
前置作業:
1. 需要先到graphviz官網下載並安裝 #graphviz本身
2. pip install graphviz #python與graphviz的接口package
若使用anaconda 環境:conda install conda-forge::python-graphvizconda install conda-forge/label/broken::python-graphvizconda install conda-forge/label/cf201901::python-graphvizconda install conda-forge/label/cf202003::python-graphviz
code:
# -*- coding: utf-8 -*-
"""
Created on Sun Oct 27 00:33:23 2024
@author: SavingKing
"""
# -*- coding: utf-8 -*-
"""
Created on Sat Oct 26 23:41:55 2024
@author: SavingKing
"""
from graphviz import Digraph
# 定義步驟列表
steps = [
"get uut ip", "connect to ovss", "bmc ip check", "bmc comm set to ssh",
"fis check bmc mac number", "Check BMC MAC", "check fru common header",
"bmc led check", "create meltan ssh", "gsys cpu info", "gsys storage info",
"USB info chain check", "gsys restart service", "gsys version",
"gsys system thermal test", "CPU dimm virtual sensor check", "gsys hw configuration",
"gsys dimm info", "gsys fan count check", "gsys bmc fw check", "bios info",
"cpld version check", "CPLD OTP update", "meltan havenmap", "meltan ncsi_cable",
"gsys check fru", "ipmitool check fru", "ipmi fan speed max check",
"ipmi fan speed min check", "chassis info"
]
# 創建一個有向圖,設置預設方向為從上到下
dot = Digraph() #graphviz.graphs.Digraph
dot.attr(rankdir='TB', size='10,15') # 設置畫布大小
# 定義每列的步驟數
steps_per_column = 10
# 創建節點
for step in steps:
dot.node(step, step)
#dot.node(ID, 標籤名)
# 添加邊,連接節點
for i in range(len(steps) - 1):
if (i + 1) % steps_per_column == 0: # 如果是列的最後一個節點
# 將這一列的最後一個節點與下一列的第一個節點連接,並設置為稍微向右的線
dot.edge(steps[i], steps[i + 1], constraint='false')
else:
# 連接同一列內的節點
dot.edge(steps[i], steps[i + 1])
# 渲染圖形到PNG文件
output_path = dot.render('step_flow_chart04', format='png', cleanup=True)
print(f"圖形已渲染於 {output_path}")
輸出的png檔:
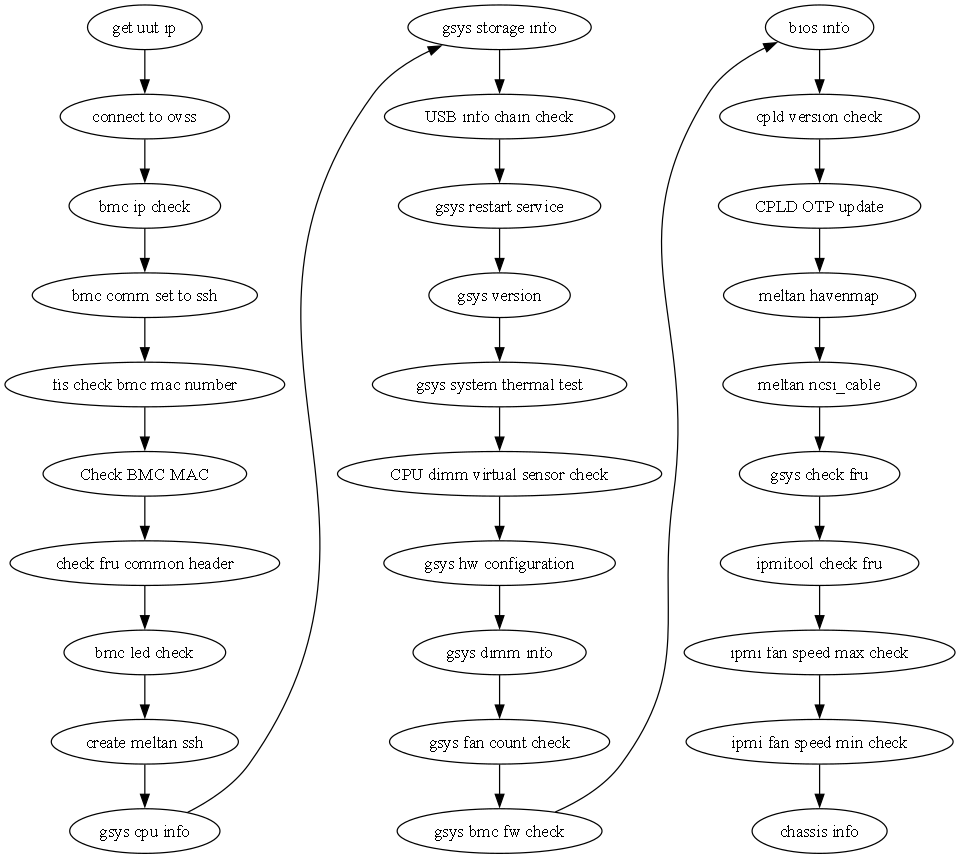
在Graphviz中使用 constraint=’false’ 並不是直接解除由上而下的箭頭方向,而是對於特定的邊(edge)來說,這個設置會使得該邊不再影響節點的排列約束。這有助於在需要時自定義圖的布局,尤其是在排列和方向方面。
理解 constraint=’false’
在Graphviz的默認行為中,每條邊都會對節點的排列造成影響,使得圖的布局符合某種邏輯(如由上至下或由左至右的順序)。當設定 constraint=’false’ 時,對應的邊不會影響節點的排列,這意味著:
節點位置:雖然設置 constraint=’false’,節點的位置仍然可能按照其他邊的約束或是圖的全局屬性(如 rankdir)來決定,但該邊不會對節點的垂直或水平排列造成強制性影響。
邊方向:該設置不會改變邊本身的方向(仍然會從一個節點指向另一個節點),但它允許更自由地控制邊在視覺展示上的表現,特別是在跨列或跨行連接時。
使用場景
constraint=’false’ 常用於如下幾種場景:
跨列連接:當需要在多列的圖中繪製橫跨幾列的連接線時,使用 constraint=’false’ 可以避免這條邊造成不必要的列間距調整。
子圖布局:在使用子圖時,如果想要子圖內部的布局獨立於外部圖的布局,可以對子圖內的連接使用此屬性。
避免布局變形:在複雜的圖中,某些邊的約束可能會導致不希望的節點重新排列或布局壓縮,使用 constraint=’false’ 可以減少這類影響。
dot.attr?
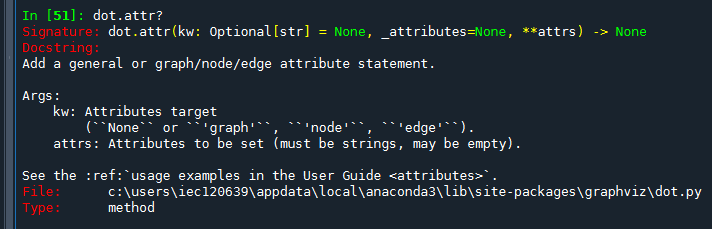
dot.attr 是 Graphviz Python 庫中 dot 對象的一個方法,用於添加圖形、節點或邊的屬性。這個方法非常靈活,允許你為不同的圖形元素指定不同的屬性,從而控制圖形的外觀和行為。
方法簽名解析
kw: 可選參數,用於指定屬性應用的目標。它可以是 None(默認值,適用於當前上下文)、’graph’、’node’ 或 ‘edge’。這決定了屬性是應用於整個圖形、所有節點還是所有邊。
_attributes: 這是一個內部使用的參數,通常不需要手動提供。
**attrs: 這是可變關鍵字參數,用於傳遞具體的屬性值。例如,可以設置節點的形狀、顏色、樣式等。
關於 Graphviz 屬性
Graphviz 支持大量的屬性,這些屬性可以應用於圖形、節點和邊。這些屬性包括但不限於:
rankdir: 設置圖形的排列方向(如 TB 代表自上而下,LR 代表從左向右)。
size: 設置圖形的最大尺寸,單位為英寸。
shape: 節點的形狀(如 circle, rectangle 等)。
color: 邊或節點的顏色。
style: 節點或邊的樣式(如 dotted, bold 等)。
這種設計使得 dot.attr 非常靈活,可以使用任何 Graphviz 支持的屬性,而不需要在方法簽名中列出每一個可能的屬性。這也是為什麽你不在方法簽名中看到特定的屬性如 rankdir 或 size。
dot.edge?
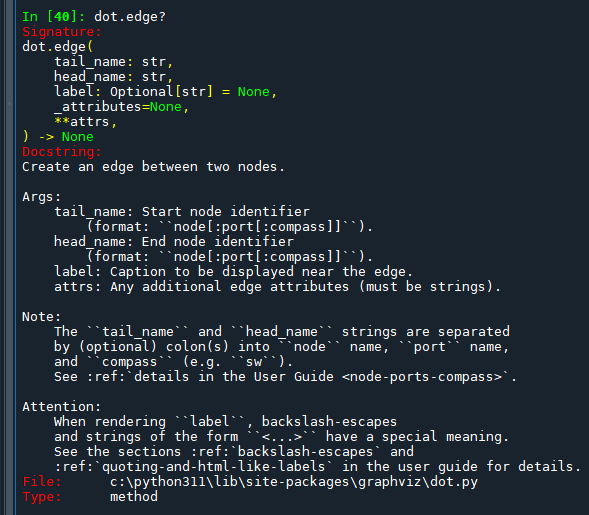
dot.edge 方法是在 Graphviz Python 函式庫中用來創建兩個節點之間的有向邊。理解如何有效使用此方法,可以讓您自定義圖形中的連接,更好地表示關係或流程。以下是該方法的詳細說明和使用方式:
方法簽名
**dot.edge(tail_name: str, head_name: str, label: Optional[str] = None, _attributes=None, attrs) -> None
tail_name: 開始節點(邊的尾部)的標識符。
head_name: 結束節點(邊的頭部)的標識符。
label: 可選,顯示在邊附近的標注。
_attributes: 內部參數,用於附加屬性;通常在一般使用中不需要。
**attrs: 允許設置額外的邊屬性,屬性以鍵值對的形式出現,鍵和值都必須是字符串。
使用說明
節點標識符: tail_name 和 head_name 可以包括不僅是節點名稱,也可以包括可選的端口和指南針方向。語法為 node[:port[:compass]]。例如,”node1:port1:n” 中,node1 是節點標識符,port1 是節點上的特定端口(適用於更複雜的圖形),n 是指南針點,指示節點的特定側面(北、南、東、西等)。
標籤和屬性:
label 允許您在邊上添加描述性文本,這對於指示關係或互動的性質非常有用。
**attrs 可用於自定義邊的外觀和行為。常見屬性包括 color(顏色)、style(風格)、weight(權重)和 constraint(約束)。
特別注意事項
label 的渲染: 與節點標籤一樣,邊的標籤也可以解釋反斜線轉義和 HTML-like 標籤(<…>)。這一功能可以用來包括特殊格式或整合 HTML 標籤,以實現更複雜的標籤需求。
參考部分: 方法文檔提到了用戶指南部分,對節點端口和指南針方向的詳細解釋,以及標籤中的特殊格式選項的詳細說明。如果您需要對如何連接邊到節點或如何顯示標籤進行詳細控制,應該查閱這些部分。
dot.node?
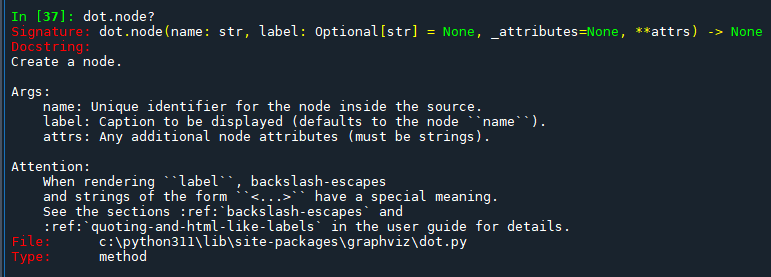
dot.node 方法的簽名和文檔說明中,可以看到如何使用這個方法來創建圖形中的節點。這里是一個詳細的解釋如何使用這個方法,並在您的代碼中如何實現:
方法簽名解釋
**dot.node(name: str, label: Optional[str] = None, _attributes=None, attrs) -> None
name: 節點的唯一標識符,在圖形的源代碼中必須是唯一的。
(小心step有重複的)
label: 顯示在節點上的文本,默認是 name 參數的值。
_attributes: 這是一個內部參數,通常不需要手動設置。
**attrs: 允許設置任何額外的節點屬性,這些屬性必須是字符串。例如,可以設置節點的形狀、顏色、字體等。
文檔字符串解釋
文檔字符串中提到了 label 參數在渲染時對反斜杠轉義和 <…> 形式的字符串有特殊含義。這意味著可以在 label 中使用HTML-like的標記,或者使用轉義字符來控制顯示的格式。
在使用 graphviz 创建图形时,节点的 name 参数是用来唯一标识每个节点的。如果在图形中有多个节点使用同样的 name,会出现一些问题,具体表现取决于具体的图形库和渲染方式,但一般情况如下:
覆盖问题:如果多次调用 dot.node() 使用相同的 name,可能会导致先前创建的节点被后续的节点覆盖。最终,图形中只会显示最后一次使用该 name 的节点设置。
连接错误:由于节点名称的唯一性,如果多个步骤具有相同的文字描述并用作节点名称,那么在添加边(连接)时,所有指向该名称的连接只会指向一个节点实例。这可能会导致预期中的多个独立步骤被错误地合并为一个步骤,从而使流程图的逻辑表达出现错误。
解决方法
为了避免因步骤名称重复而导致的问题,可以通过以下几种方法来确保节点名称的唯一性:
添加唯一后缀:可以为每个节点的名称添加一个唯一的标识符(如序号)。例如,如果步骤名称是从列表中读取的,可以将步骤的索引或其他唯一标识符附加到名称上:
for i, step in enumerate(steps):
unique_name = f"{step}_{i}" # 创建唯一名称
dot.node(unique_name, step) # 使用唯一名称作为节点名称,原名称作为标签使用字典管理:构建一个字典来关联步骤的文本和它们的唯一标识符:
step_dict = {f"{step}_{i}": step for i, step in enumerate(steps)}
for unique_name, step_label in step_dict.items():
dot.node(unique_name, step_label)- 检查重复:在添加节点之前检查名称是否已被使用,如果已存在,则修改名称以避免重复。
通过以上方法,可以确保即使步骤的描述文字相同,它们在图形中也能作为独立的节点存在,从而保持流程图的准确性和清晰度。
推薦hahow線上學習python: https://igrape.net/30afN
# -*- coding: utf-8 -*-
"""
Created on Mon Oct 27 20:32:43 2024
@author: SavingKing
ver02:
ver 01 OK,多建一個export 子資料夾輸出圖形
steps 要從xlsx中讀取,有重複的steps,
dot.node(step, step),第一個參數必須是獨一無二的ID,不可使用有重複的step
for loop中的dot.edge() 也要修改
ver03:
ver02 OK, df_xlsx_test_sq 有 5 columns,
取5個Series並轉成list,看能不能用for迴圈,
還是想要用Series,可以用Series.name(源自於df.columns) 作為輸出檔名中的一部分
"""
from graphviz import Digraph
import os
import pandas as pd
import numpy as np
def mkdir_export(dirname,sub_dirname="export"):
"""
在原本一堆log的資料夾之下,
建立一個export的子資料夾,放自己輸出的檔案
Parameters
----------
dirname : TYPE str
DESCRIPTION
D:\\user\\240414~240504_FBT_log_PASS\\CMOIVT
Returns
-------
dirname_ex : TYPE str
DESCRIPTION.
D:\\user\\240414~240504_FBT_log_PASS\\CMOIVT\export
"""
#dirname_ex = dirname+"\export"
#dirname_ex = dirname+"\\" +sub_dirname
dirname_ex = os.path.join(dirname, sub_dirname)
if not os.path.exists(dirname_ex):
os.mkdir(dirname_ex)
print(f"\n已經建立資料夾:\n{dirname_ex}")
else:
print(f"\n資料夾已經存在:\n{dirname_ex}")
return dirname_ex
dirname_graphviz = r"D:\user\Python\test_plan\python_graphviz"
basename_png = "flow_chart.png"
main_fname_png = os.path.splitext(basename_png)[0]
#'step_flow_chart'
dirname_ex = mkdir_export(dirname_graphviz)
#'D:\\user\\Python\\test_plan\\python_graphviz\\export'
path_ex = os.path.join(dirname_ex, main_fname_png)
#'D:\\user\\Python\\test_plan\\python_graphviz\\export\\step_flow_chart'
#注意: 沒有.png 的副檔名
#dot.render() 就是需要這樣的參數,用format='png'定義附檔名
pd.set_option('display.max_columns', None)
basename_xlsx_test_sq= "Capala MFG BFT L6_L10 Test Coverage & Test Capacity (go_capala-mfg-tests).xlsx"
path_xlsx_test_sq = os.path.join(dirname_graphviz,basename_xlsx_test_sq)
#'D:\\user\\Python\\test_plan\\python_graphviz\\Test Capacity (go_capala-mfg-tests).xlsx'
sheet_name="Test Sequence"
df_xlsx_test_sq = pd.read_excel(path_xlsx_test_sq,sheet_name=sheet_name,header=0,index_col="Item")
#[64 rows x 5 columns]
#df_xlsx_test_sq.columns
#Out[32]: Index(['MOBO', 'HSBP', 'FAN', 'FAT', 'Run-in'], dtype='object')
ser_MOBO = df_xlsx_test_sq['MOBO']
ser_HSBP = df_xlsx_test_sq['HSBP']
ser_FAN = df_xlsx_test_sq['FAN']
ser_FAT = df_xlsx_test_sq['FAT']
ser_RunIn= df_xlsx_test_sq['Run-in']
def rm_NaN(lis):
"""
TypeError: ufunc 'isnan' not supported for the input types, and the inputs could not be safely coerced to any supported types according to the casting rule ''safe''
類型檢查:首先檢查 x 是否是整數或浮點數 (isinstance(x, (int, float)))。
NaN 檢查:如果 x 是數值類型,再檢查它是否不是 NaN (not np.isnan(x))。
組合邏輯:使用 or 將兩個條件組合。如果 x 不是數值類型,則第一個條件 not isinstance(x, (int, float)) 就為真,元素會被保留。如果 x 是數值類型且不是 NaN,第二條件 not np.isnan(x) 為真,元素同樣被保留。
這種邏輯有效防止了在 np.isnan(x) 調用時出現的類型錯誤,並確保了所有非 NaN 的數值和所有非數值類型的元素都被正確保留。
"""
#lis_No_NaN = [x for x in lis if not isinstance(x, (int, float)) or not np.isnan(x)]
#type(np.NaN) #Out[83]: float
lis_No_NaN = [x for x in lis if not isinstance(x, float) or not np.isnan(x)]
return lis_No_NaN
def df2lis_lis_steps(df):
"""
df_xlsx_test_sq #[64 rows x 5 columns]
有5個columns ,可以拆分為5個Series,並轉為list
一開始先一個空list,裝載這5個list
"""
lis_lis_steps = []
for col in df_xlsx_test_sq.columns:
tests = df_xlsx_test_sq[col].to_list()
tests_No_NaN = rm_NaN(tests)
lis_lis_steps.append(tests_No_NaN)
return lis_lis_steps
lis_lis_steps = df2lis_lis_steps(df=df_xlsx_test_sq)
#長度5 沒錯,但元素lis_steps 含有很多pd.NaN
#多定義了function: rm_NaN
def df2lis_ser_steps(df):
"""
跟 df2lis_lis_steps(df) 相仿
lis_ser_steps 原為空list
要裝5個Series,使用dropna() 去掉np.nan
"""
lis_ser_steps=[]
for col in df_xlsx_test_sq.columns:
ser_tests = df_xlsx_test_sq[col]
ser_tests.dropna(inplace=True)
lis_ser_steps.append(ser_tests)
return lis_ser_steps
lis_ser_steps = df2lis_ser_steps(df=df_xlsx_test_sq)
# 定義步驟列表
# =============================================================================
# steps = [
# "get uut ip", "connect to ovss", "bmc ip check", "bmc comm set to ssh",
# "fis check bmc mac number", "Check BMC MAC", "check fru common header",
# "bmc led check", "create meltan ssh", "gsys cpu info", "gsys storage info",
# "USB info chain check", "gsys restart service", "gsys version",
# "gsys system thermal test", "CPU dimm virtual sensor check", "gsys hw configuration",
# "gsys dimm info", "gsys fan count check", "gsys bmc fw check", "bios info",
# "cpld version check", "CPLD OTP update", "meltan havenmap", "meltan ncsi_cable",
# "gsys check fru", "ipmitool check fru", "ipmi fan speed max check",
# "ipmi fan speed min check", "chassis info"
# ]
# =============================================================================
#使用從Test Coverage.xlsx 中的Test Sequence提取steps資料
#steps = ser_MOBO.to_list()
def create_flow_chart(steps,path_ex,steps_per_column=16,format="png"):
#from graphviz import Digraph #未免func外部沒有import,內部import也可
# 創建一個有向圖,設置預設方向為從上到下
dot = Digraph() #graphviz.graphs.Digraph
dot.attr(rankdir='TB', size='10,15') # 設置畫布大小
# 定義每列的步驟數
steps_per_column = steps_per_column
# 創建節點
for idx,step in enumerate(steps):
dot.node(f"{step}_{idx}", step)
#dot.node(ID, 標籤名)
# 添加邊,連接節點
for i in range(len(steps) - 1):
if (i + 1) % steps_per_column == 0:
dot.edge(f"{steps[i]}_{i}", f"{steps[i + 1]}_{i + 1}", constraint='false')
else:
dot.edge(f"{steps[i]}_{i}", f"{steps[i + 1]}_{i + 1}")
# 渲染圖形到PNG文件
output_path = dot.render(path_ex, format=format, cleanup=True)
print(f"圖形已渲染於 {output_path}")
return None
""" len(ser):
63 19 18 59 16
#長度最長是59,63 (16個step為一個column)
其他10個step一個column
"""
#for i,steps in enumerate(lis_lis_steps):
for ser in lis_ser_steps:
if len(ser)>50:
create_flow_chart(ser.values,path_ex=path_ex+f"_{ser.name}",steps_per_column=16,format="png")
#steps_per_column=16對於step 較多的MOBO適合,
#但是其他step較少的flow就不適合,可能不使用迴圈,
#或者迴圈中還要訂step數多少以上的話,才用steps_per_column=16
else:
create_flow_chart(ser.values,path_ex=path_ex+f"_{ser.name}",steps_per_column=10,format="png") ; Python的命名慣例: 全大寫表示常數,首字大寫表示Class")
 增加新的一欄? model = tensorflow.keras.models.Sequential() #均一化資料")


 #像操作 List 一樣操作文件; target_xml_node.addnext(p_new)")
 ; axis參數如何用? numpy.max() ; numpy.min() ; numpy.argmax() #沿軸max的index; numpy.argmin() #沿軸min的index")
?如何使用jieba做中文斷詞? lis_jieba = jieba.lcut(strr)")
")
,計算新光人壽增有利IRR,免費下載IRR計算機")


近期留言