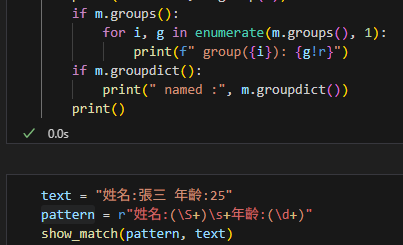
# %%
import pandas as pd
# 創建兩個 DataFrame
df1 = pd.DataFrame({
'A': [1, 2, 3],
'B': ['a', 'b', 'c']
})
df2 = pd.DataFrame({
'A': [4, 5, 6],
'B': ['d', 'e', 'f']
})
# 不使用 ignore_index=True
result1 = pd.concat([df1, df2])
print("不使用 ignore_index=True:")
print(result1)輸出結果:
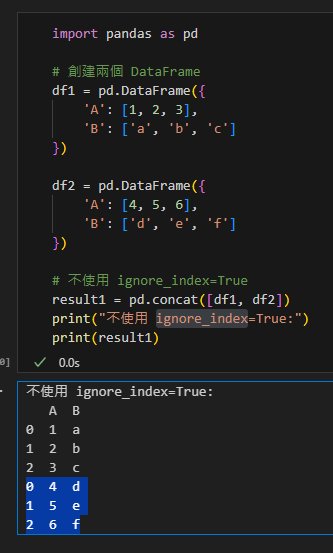
合併的df有重複的索引
# %%
import pandas as pd
# 創建兩個 DataFrame
df1 = pd.DataFrame({
'A': [1, 2, 3],
'B': ['a', 'b', 'c']
})
df2 = pd.DataFrame({
'A': [4, 5, 6],
'B': ['d', 'e', 'f']
})
# 不使用 ignore_index=True
result1 = pd.concat([df1, df2],ignore_index=True)
print("使用 ignore_index=True:")
print(result1)輸出結果:
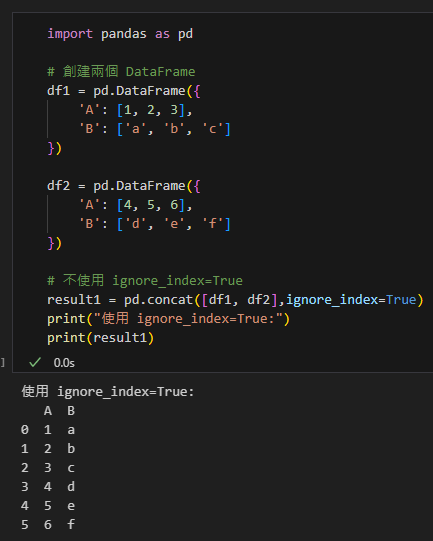
索引連續且唯一
pd.concat([df1, df2]).reset_index(drop=True)
也有相同效果:
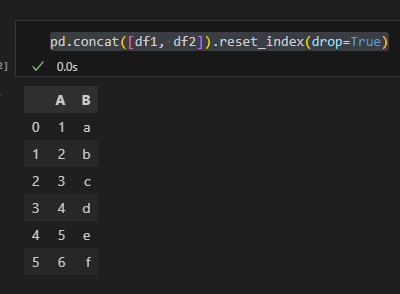
關鍵差異
| 特性 | ignore_index=True | .reset_index(drop=True) |
|---|---|---|
| 處理方式 | 在合併時直接忽略索引, 生成新索引。 | 先合併保留索引, 然後重置索引。 |
| 效率 | 更高效, 因為一步完成。 | 稍低,因為多了一步 索引處理。 |
| 原始索引是否可用 | 不可用, 索引在合併時 直接被忽略。 | drop=True的話,不可用 |
原因分析
ignore_index=True的行為:- 在執行
pd.concat()時,直接忽略原始索引,並重新為結果生成一個從0開始的連續索引,無論原索引是否重複。
- 在執行
.reset_index(drop=True)的行為:- 先保留原始索引,合併後的結果中仍然保留重複的索引。
- 然後執行
.reset_index(drop=True),刪除原始索引並重新生成新的連續索引。
由於兩者最終都會重新生成索引,因此在這種情況下,結果是一樣的。
推薦hahow線上學習python: https://igrape.net/30afN
![Python: 如何將folder_name, file_name合併為file_path? fpath = os.path .join(folder, fname) ; “\\”.join([folder, fname]) ; 如何將file_path拆分出folder?](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2023/03/20230330132954_84.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: 如何將folder_name, file_name合併為file_path? fpath = os.path .join(folder, fname) ; “\\”.join([folder, fname]) ; 如何將file_path拆分出folder?")

與tuple, set, issubset(), issuperset()")
![Python: 資料格式如 List[dict],如何快速將SN加入每一個dict中,以利Excel輸出?如何解包dict? **dict ; 將List[dict]的資料轉為pandas.DataFrame 長什麼樣子?](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2024/02/20240208093926_0.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: 資料格式如 List[dict],如何快速將SN加入每一個dict中,以利Excel輸出?如何解包dict? **dict ; 將List[dict]的資料轉為pandas.DataFrame 長什麼樣子?")
; dict(key)提取dict內的元素; importlib.reload(); np.zeros(); np.array()")
from openai import AsyncAzureOpenAI")


, x)` ; sorted(items, key=lambda x: (-len(x), x)) 與 json_repair strategy pipeline")

近期留言