#Python TQC考題904 資料計算
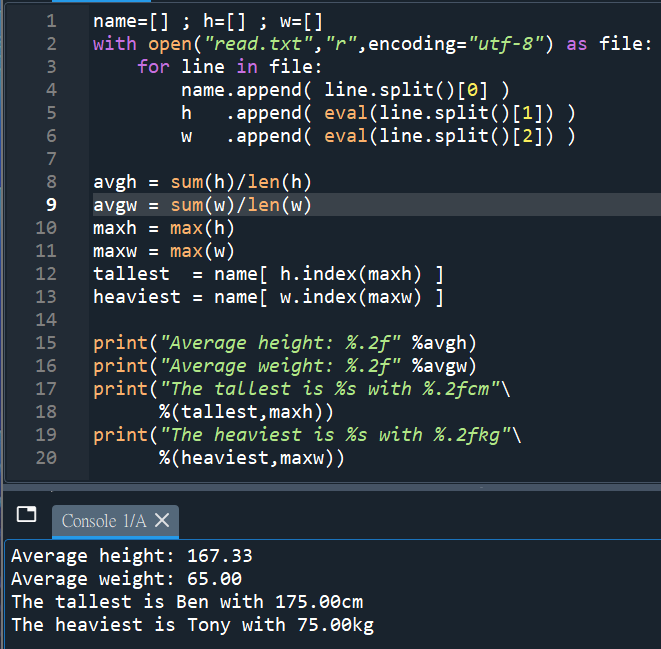
L=[]
with open(“read.txt”,”r”,encoding=”utf-8″) as file:
for line in file:
print(line)
L.append(line.split())
#需要.split() ,不然會多\n
n=len(L)
name=[L[i][0] for i in range(n)]
h=[eval(L[i][1]) for i in range(n)]
w=[eval(L[i][2]) for i in range(n)]
h_avg=sum(h)/n
w_avg=sum(w)/n
print(“Average height: %.2f” %h_avg)
print(“Average weight: %.2f” %w_avg)
h_max=max(h)
w_max=max(w)
print(“The tallest is %s with %.2fcm” %(name[h.index(h_max)],h_max))
print(“The heaviest is %s with %.2fkg” %(name[w.index(w_max)],w_max))
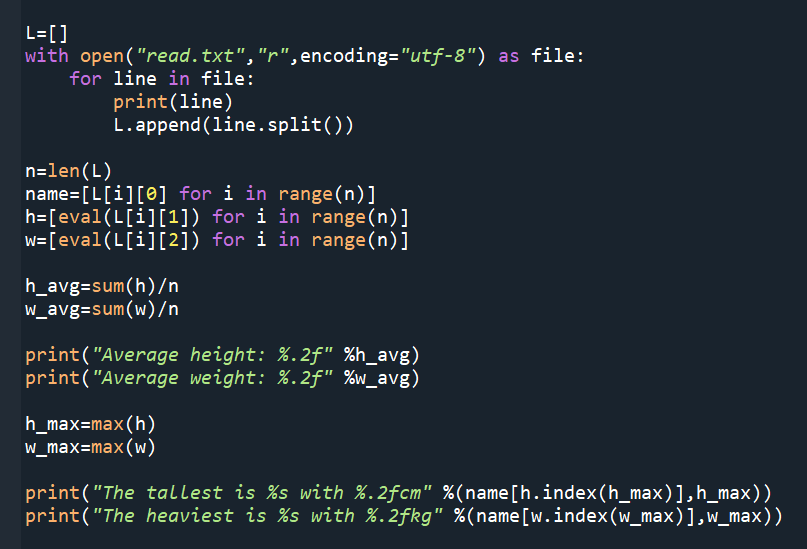
“””
read.txt的內容:
Ben 175 65
Cathy 155 55
Tony 172 75
資料排列都類似
#為多了解程式結構
#多印一些list出來看:
“””
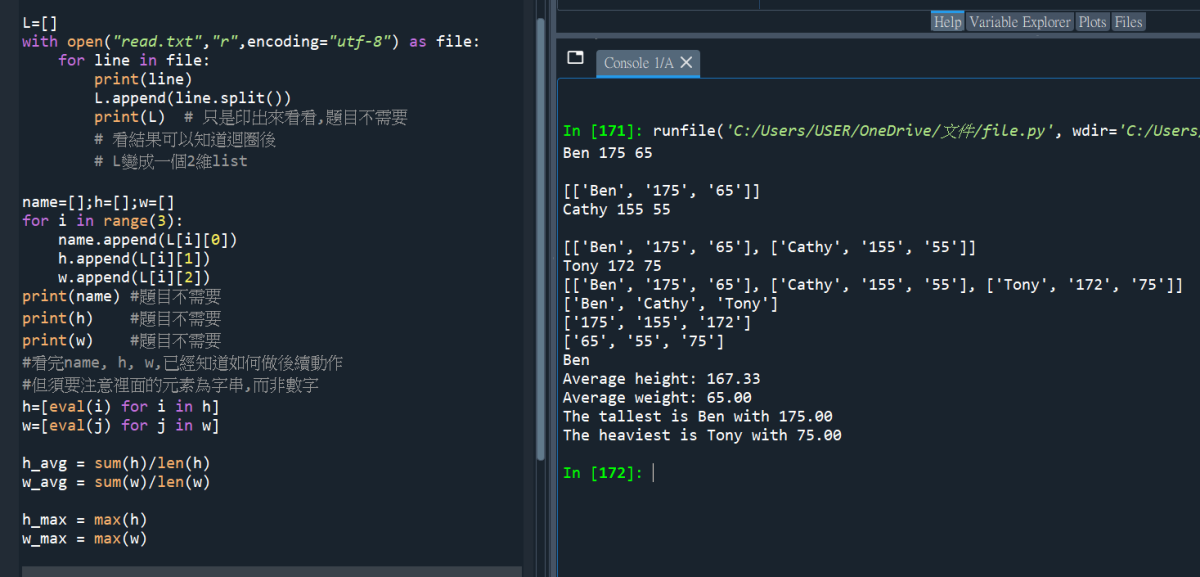

#再練習一次:
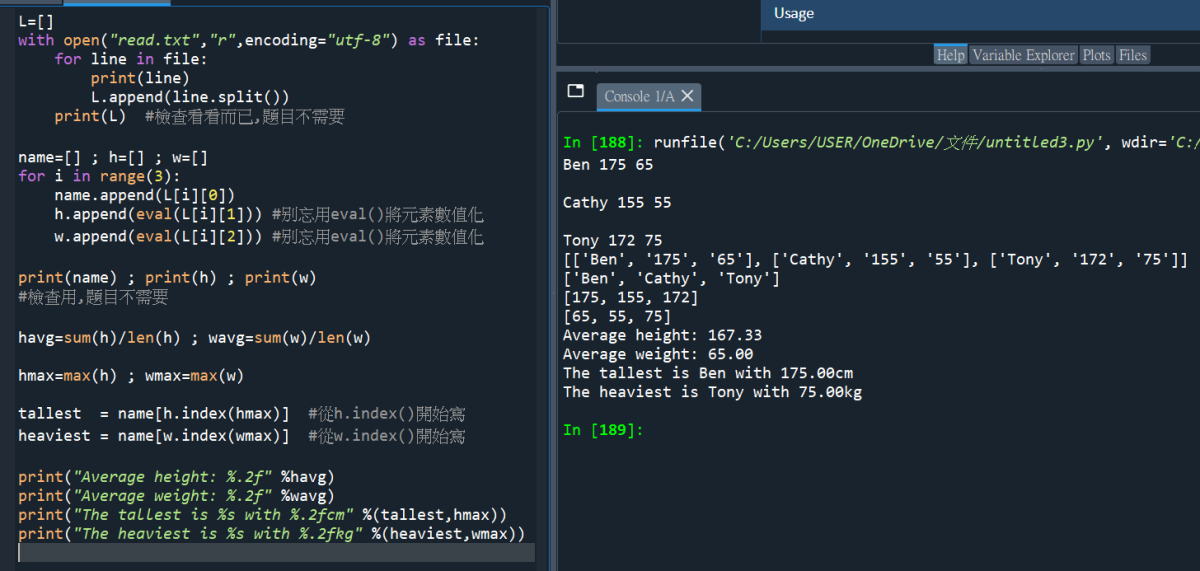
#放大程式碼:
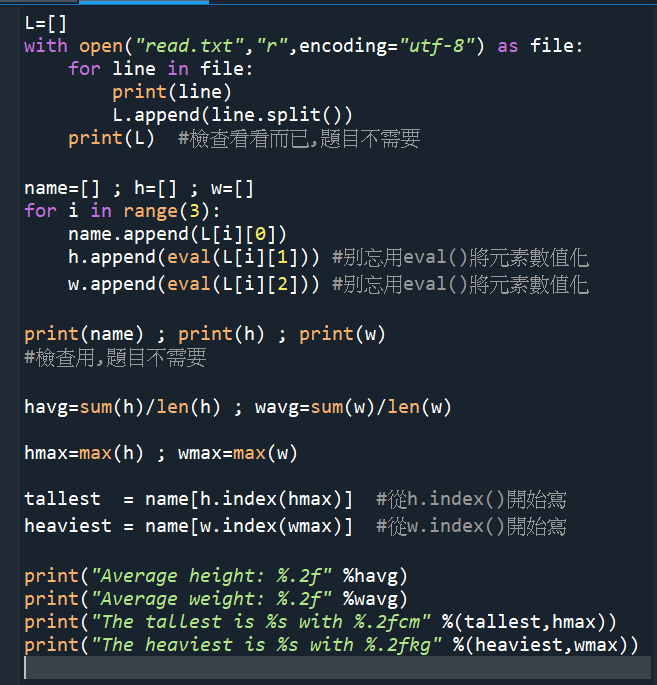
#再練習一次:
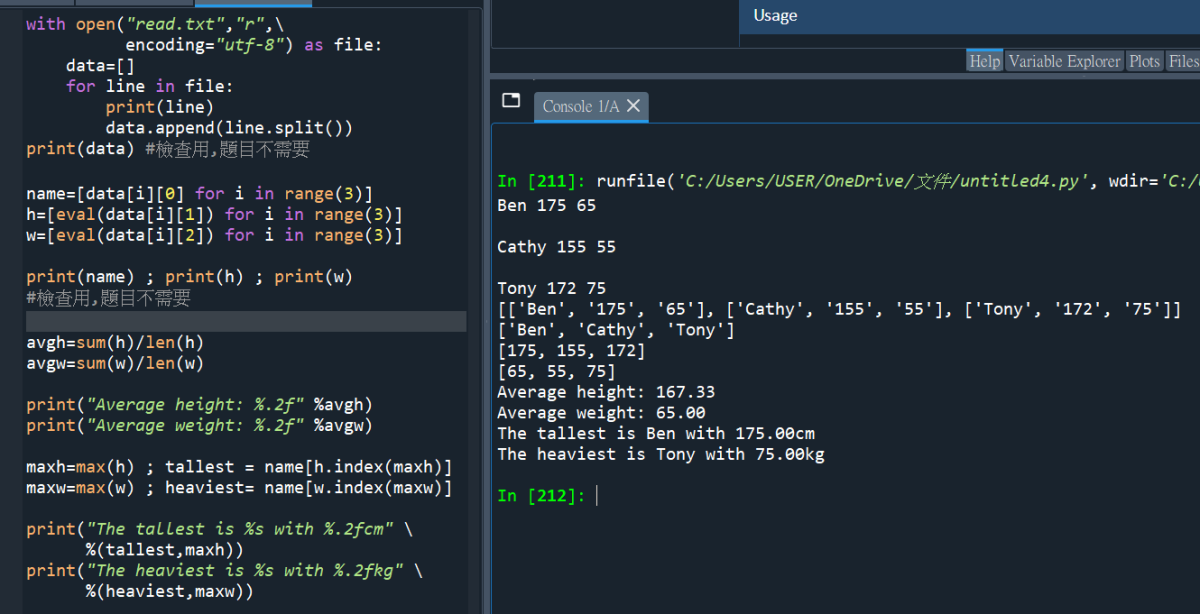
#放大程式碼:
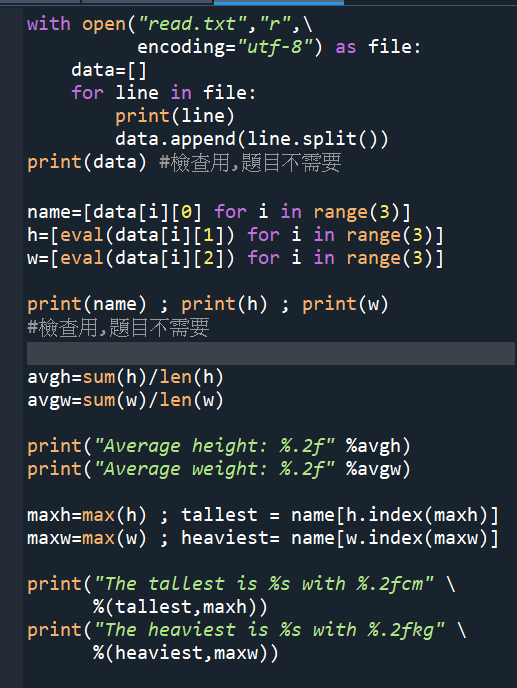
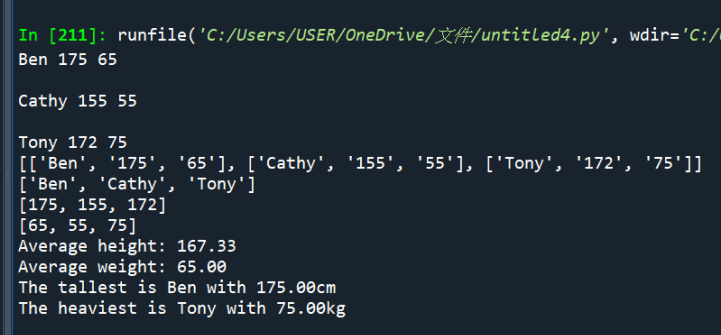
#放大輸出結果:
“””
#這次不用逐行讀取的方式
#使用.readlines()把所有資料都讀進來
#再想辦法處理
#其實少了題目要求的: 顯示檔案內容
前面要再多兩行
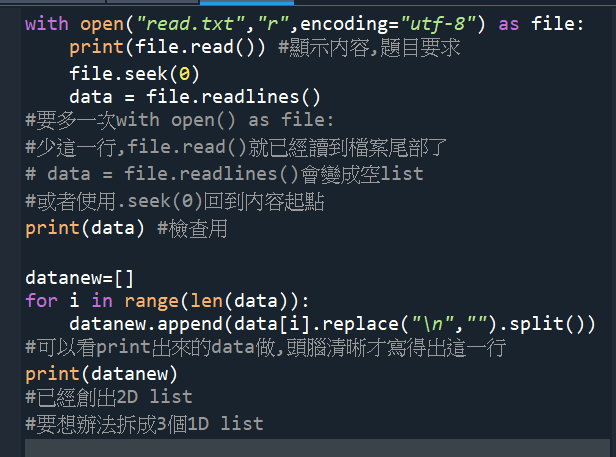
with open(“read.txt”,”r”,encoding=”utf-8″) as file:
print(file.read()) #顯示內容,題目要求
with open() as file: 需要寫兩次
#少一次,file.read()就已經讀到檔案尾部了
# data = file.readlines()會變成空list
# 或用file.seek(0)回到內容的起點處
datanew.append(data[i].replace(“\n”,””).split())
#可以看print出來的data寫,
#頭腦清晰才寫得出這一行
#其實沒有比原本逐行做容易
#程式碼:
“””
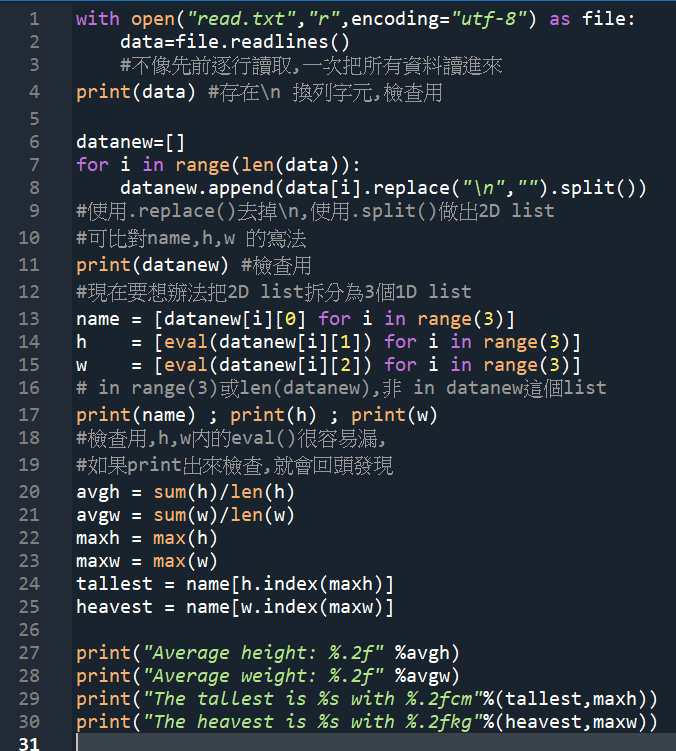
#輸出結果:
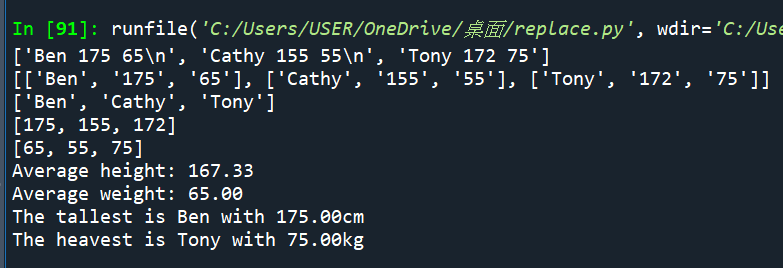
#再寫一次完整的
#包含題目要的顯示內容
#程式碼:
#輸出結果:
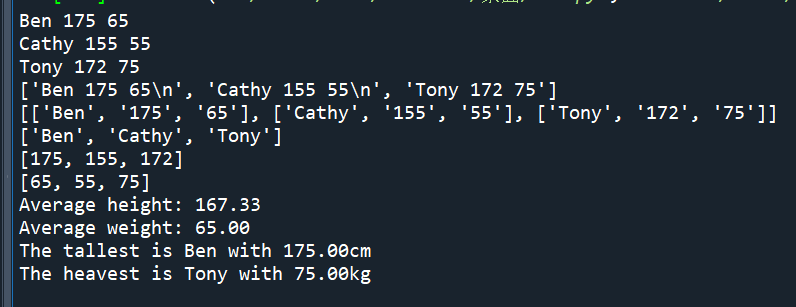
#老師或書上教的大同小異:
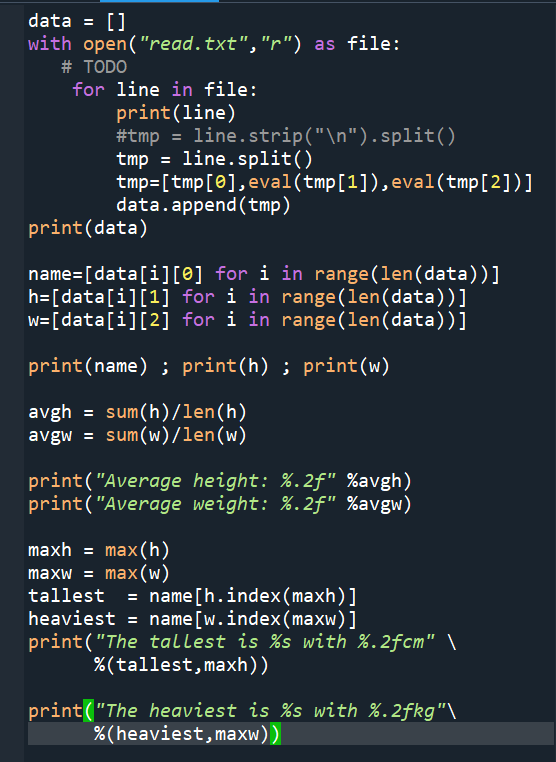
輸出結果:
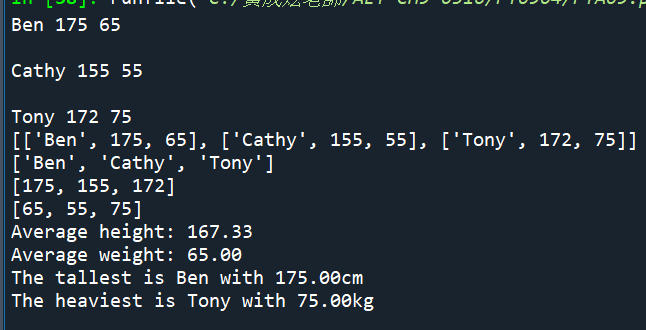
“””
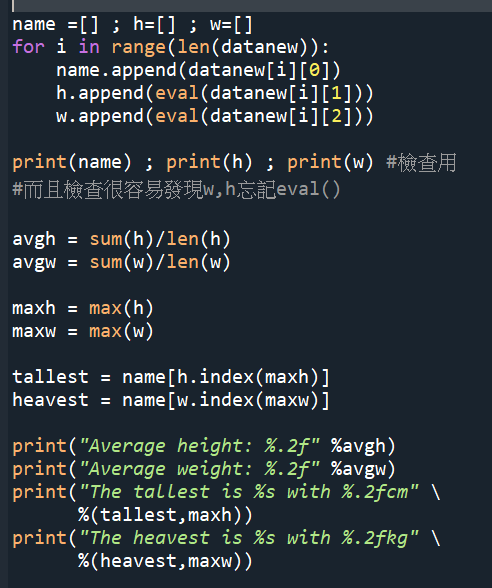
再多一層迴圈
for line in file:
可以不用2D list
再拆分為3個1D list
直接做好3個1D list
“””
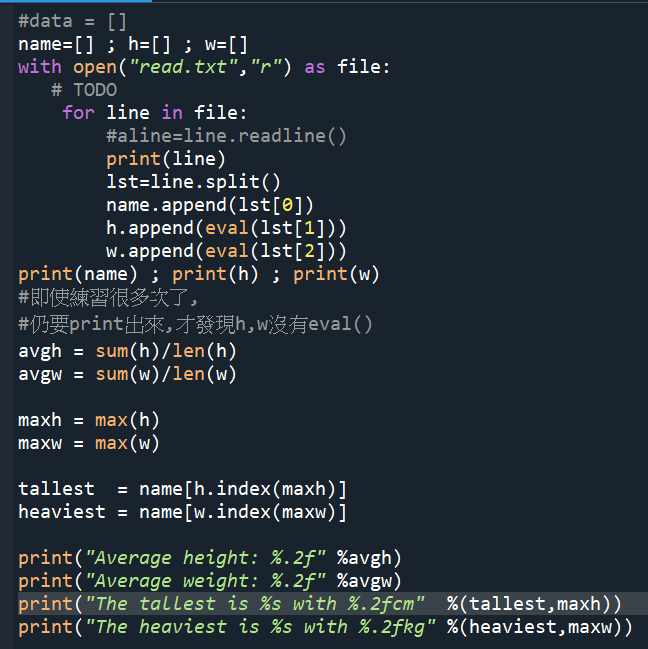
#輸出結果:
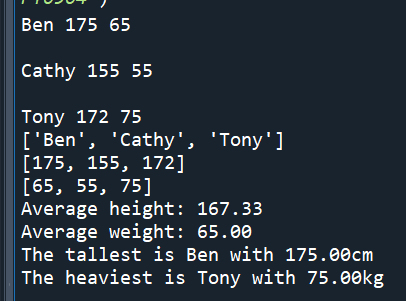
#多餘的空白對於語法沒影響
#但可能有助於理解

 ) ;雙層column name的DF與Series或單層column name的DF做橫向(axis=1)合併會如何? 雙層column name被壓縮成單層的tuple")
 用簡單例子理解 sort_values() 方法")
")
")
 > Ctrl + shift +F9 取消所有超連結;參考資料>插入索引>自動標記,隱藏標記後,參考資料>插入索引")


 增加新的一欄? model = tensorflow.keras.models.Sequential() #均一化資料")
![Python 實戰:用 jieba + Normalize + N-gram 穩定抓出 Family 名稱 ; re.sub(r'[^a-z0-9]+', '', s.lower()) #全部轉小寫 #移除非英數字元 - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2026/04/20260428110138_0_e34bb8-520x245.png)
![Python如何讀取excel檔(.xlsx)?如何用欄標籤提取某一直行?df=pandas.read_excel() ; df["欄標籤"] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/11/20221109163631_39-520x245.png)

近期留言