在數據處理和分析中,經常需要將新的數據列加入到現有的DataFrame中。在Pandas中,這通常涉及到兩種常見的數據類型:Series和列表(list)。本教程將詳細介紹如何將這兩種類型的數據正確地分配給DataFrame的新列,特別是關注列表長度的匹配問題以及Series索引不對齊時可能出現的情況。
將列表分配給DataFrame的新列
向DataFrame添加一個列表作為新列是一個直接的操作,但需要確保列表的長度與DataFrame的行數完全相等。如果長度不匹配,Pandas會拋出一個錯誤,因為它無法決定如何填充多出來或缺少的行。
示例:
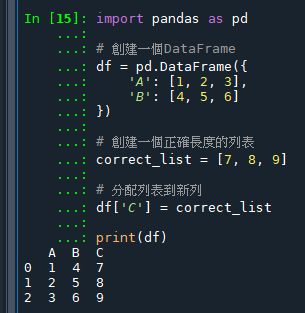
import pandas as pd
# 創建一個DataFrame
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6]
})
# 創建一個正確長度的列表
correct_list = [7, 8, 9]
# 分配列表到新列
df['C'] = correct_list
print(df)輸出結果:
如果列表長度與DataFrame的行數不一致,例如:
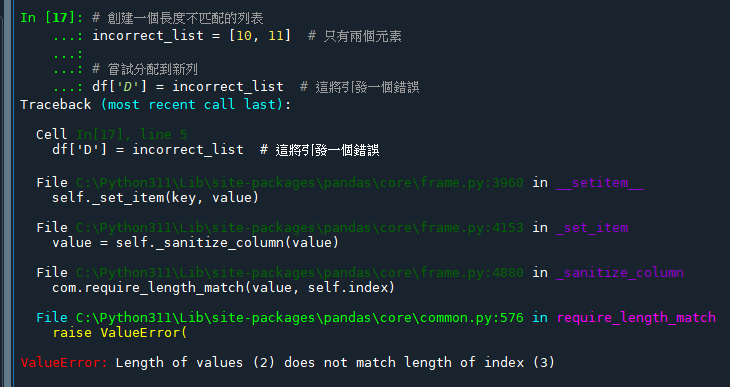
# 創建一個長度不匹配的列表
incorrect_list = [10, 11] # 只有兩個元素
# 嘗試分配到新列
df['D'] = incorrect_list # 這將引發一個錯誤這將引發一個ValueError,因為列表的長度不等於DataFrame的rows數。
ValueError: Length of values (2) does not match length of index (3)
將Series分配給DataFrame的新列
當分配一個Series到DataFrame的新列時,如果Series的索引與DataFrame的索引不對齊,Pandas會嘗試根據索引進行對齊操作。不匹配的索引會在新column中產生NaN值。
示例:
# 創建一個Series,索引不對齊
s = pd.Series([10, 11, 12], index=[1, 2, 4], name='D')
# 分配Series到新列
df['D'] = s
print(df)輸出結果:
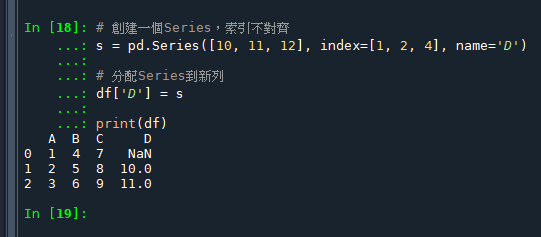
可以看到,由於原df有的索引0在Series中不存在,
對應的值在新column中顯示為NaN。
總結
在將列表或Series分配給DataFrame的新列時,重要的是要確保數據的對齊:
列表必須具有與DataFrame rows數相同的長度。
Series的索引應與DataFrame的索引對齊,否則將在不匹配的索引處生成NaN。
正確處理這些數據類型的添加不僅可以避免運行時錯誤,
還能確保數據的準確性和完整性。
推薦hahow線上學習python: https://igrape.net/30afN


![Python: Regular Expression 正規表示法 正則表達式 import re ; pattn = “[\d]{4}\/[01][\d]\/[0123][\d] [\d]{6}” ; match = re .search (pattn,text) .group()](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2022/09/20220901154435_19.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: Regular Expression 正規表示法 正則表達式 import re ; pattn = “[\d]{4}\/[01][\d]\/[0123][\d] [\d]{6}” ; match = re .search (pattn,text) .group()")
 合併兩個DataFrame? 具關聯性欄位合併")
計算終值?")
 ; 如果y是2D的 pandas.DataFrame ; 如何一次加入所有欄標籤當作圖例(legend)的labels? labels= y.columns.tolist() ; ax.legend(lines, labels)")

 #.cut() return generator 如果需要獲取具體結果,需要用 join() 或 list() 處理 #.lcut() 直接生成list")
 教學; Path .read_text( encoding = “utf-8-sig”) ; `Ctrl+Shift+P` => `Preferences: Open User Settings (JSON)` => “files.encoding”: “utf8”")

近期留言