接續前篇: 如何計算全文件詞頻(term frequency,簡稱TF)
逆向檔案頻率(Inverse Document Frequency,簡稱 IDF)是文本處理和信息檢索領域中的一個概念,用於量化一個詞語在文檔集合中的重要性。IDF 的基本思想是,如果一個詞在很多文檔中都出現,那麽它可能不具有很好的區分能力,因此應該給予較低的權重。相反,如果一個詞只在少數文檔中出現,那麽它可能更能體現文檔的特殊性,因此應該給予較高的權重。IDF 的計算公式通常如下:
IDF = log(N / n)
IDF 代表逆向檔案頻率。
log 代表自然對數。
N 是文檔集合中的文檔總數。
n 是包含特定詞匯的文檔數量。
log 是對數函數,用於確保數值不會過大。
舉例: 100篇文章中,每篇文章都存在逗點
逗點的IDF=log(100/100)=log(1)=0
在文本分析和自然語言處理中,IDF 通常與詞頻(TF,Term Frequency)結合使用,形成 TF-IDF 方法。TF-IDF 方法能有效評估一個詞對於一個文檔集合中某個文檔的重要性。這種方法廣泛應用於搜索引擎的關鍵詞權重計算、文檔內容的自動提取、文本相似性比較等場合。通過 TF-IDF,可以識別出文檔中最具代表性和區分度的關鍵詞或短語。
使用 TF-IDF 方法時,TF 部分強調了一個詞在特定文檔中出現的頻率,而 IDF 部分則降低了那些在文檔集合中普遍出現的詞的重要性。這樣,TF-IDF 值越高的詞,就越能代表該文檔的內容,而不是整個文檔集合的通用內容。
code:
# -*- coding: utf-8 -*-
"""
Created on Mon Jan 15 06:30:23 2024
@author: SavingKing
"""
import os
import json
import jieba
import numpy as np
folder = r"D:\Python code\240107_爬蟲"
fname = "my_lis_msg_backup.json"
fpath = os.path.join(folder,fname)
#'D:\\Python code\\240107_爬蟲\\my_lis_msg.json'
with open(fpath,"r",encoding="UTF-8") as f:
dic = json.load(f)
k0 = list(dic.keys())[0]
lis = dic[k0]
lis2D = []
for strr in lis:
lis_jieba = jieba.lcut(strr)
lis2D.append(lis_jieba)
lenN = len( lis2D )
#951
lis2D_flatten = []
for ele in lis2D:
lis2D_flatten.extend(ele)
#len = 9051
rm = [ ',', '。', '、', ';', ':', '“', '”', '?', '!', '(', ')', '《', '》', '...',
'的', '是', '在', '有', '和', '也', '了', '不', '人', '我', '他', '之', '為', '與',
'大', '來', '到', '上', '就', '很', '個', '去', '而', '要', '會', '可以', '你',
'對', '着', '還', '但', '年', '這', '那', '得', '着', '中', '一個',' ', '/', '\n','.'
# 可以繼續添加更多的詞
]
for strr in rm:
if strr in lis2D_flatten:
while strr in lis2D_flatten:
lis2D_flatten.remove(strr)
dic_term_freq = {}
for term in lis2D_flatten:
if term in dic_term_freq:
dic_term_freq[term] += 1/len(lis2D_flatten)
else:
dic_term_freq[term] = 1/len(lis2D_flatten)
print("dic_term_freq:",dic_term_freq)
#出現最多的是那些詞? 詞頻多少?
max_count = max(dic_term_freq.values())
lis_max_count=[]
for k in dic_term_freq:
if dic_term_freq[k] == max_count:
lis_max_count.append(k)
print("max_count:",max_count)
print("lis_max_count:",lis_max_count)
#若沒有事先去掉不重要的詞
#lis_max_count: [',']
#詞頻最高的是 不重要的標點符號
#使用IDF過濾
set_lis2D_flatten = set(lis2D_flatten )
#去掉重複的詞,節省for迴圈次數
dic_IDF = {}
for strr in set_lis2D_flatten:
cnt= 0
for i in range(lenN):
if strr in lis2D[i]:
cnt+=1
idf = np.log(lenN/cnt)
dic_tmp = {strr:idf}
dic_IDF.update(dic_tmp)
max_IDF = max(dic_IDF.values())
lis_max_IDF = []
for word in dic_IDF:
if dic_IDF[word] == max_IDF:
lis_max_IDF.append(word)
# =============================================================================
# print("max_IDF:",max_IDF)
# print("lis_max_IDF:",lis_max_IDF)
# =============================================================================
dic_TFxIDF = {}
for word in dic_IDF.keys():
tf = dic_term_freq [word]
idf = dic_IDF [word]
dic_tmp = {word:tf*idf}
dic_TFxIDF.update(dic_tmp)
max_TFxIDF = max(dic_TFxIDF.values())
lis_max_TFxIDF = []
for word in dic_TFxIDF:
if dic_TFxIDF[word] == max_TFxIDF:
lis_max_TFxIDF.append(word)
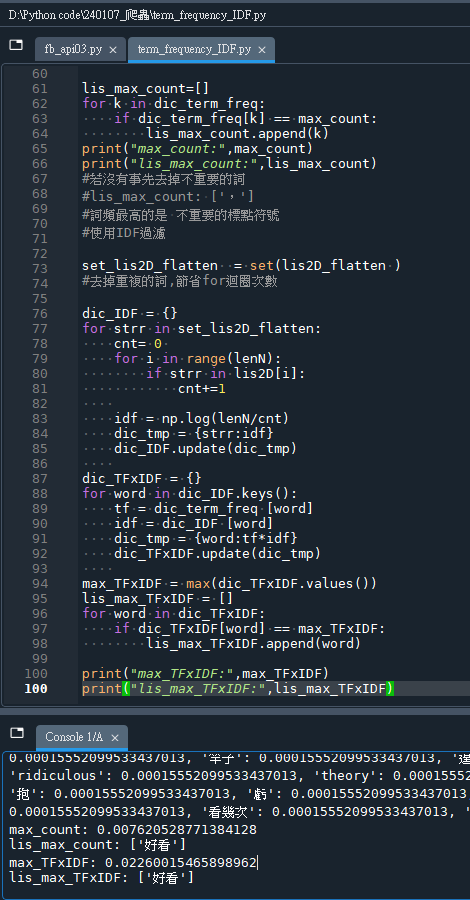
print("max_TFxIDF:",max_TFxIDF)
print("lis_max_TFxIDF:",lis_max_TFxIDF)輸出結果:
推薦hahow線上學習python: https://igrape.net/30afN


 會判斷為 True , dropna() 也刪不掉")
和深拷貝(Deep Copy); list切片有淺拷貝的效果 ; pandas.Series.copy(deep=True) 可對Series對向執行深拷貝")
 與 C3 線性化算; 物件導向:多型")
 ; axis參數如何用? numpy.max() ; numpy.min() ; numpy.argmax() #沿軸max的index; numpy.argmin() #沿軸min的index")
![Python: 如何使用numpy.newaxis 增加資料的維度? y = x[:, np.newaxis]](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2023/03/20230313184351_57.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: 如何使用numpy.newaxis 增加資料的維度? y = x[:, np.newaxis]")
 #Bytes → Element Object 與 lxml.etree.tostring(Element, encoding= “utf-8”) #Element Object → Bytes ; lxml.etree._Element; 處理 XML 時,盡量全程保持 Bytes (二進位) 狀態。")
![Python PyMuPDF fitz 教學:從pdf中抓文字、抓 fonts、抓表格; pip install PyMuPDF ; import fitz ; text_dict = page.get_text(“dict”) #type(page) is pymupdf.Page ; blocks:list[dict] = text_dict[‘blocks’] ; page.find_tables().tables [0].extract() ;如何判斷粗體字?](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2026/05/20260527141829_0_5a8a75.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python PyMuPDF fitz 教學:從pdf中抓文字、抓 fonts、抓表格; pip install PyMuPDF ; import fitz ; text_dict = page.get_text(“dict”) #type(page) is pymupdf.Page ; blocks:list[dict] = text_dict[‘blocks’] ; page.find_tables().tables [0].extract() ;如何判斷粗體字?")
![Python: matplotlib繪製出的圖表如何插入背景圖? img = plt.imread(‘background_image.png’) ; ax.imshow(img, extent=[0, 10, -1.2, 1.2], aspect=’auto’, alpha=0.5)](https://savingking.com.tw/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)

近期留言