code:
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 28 19:53:53 2024
@author: SavingKing
"""
import pandas as pd
import json
from openpyxl import load_workbook, Workbook
from openpyxl.utils import get_column_letter
from openpyxl.styles import Alignment
#創建一個含有 JSON 字符串的 DataFrame
data = {
'ID': [1, 2],
'Data': [
json.dumps({"x": 1, "y": 2, "info": {"a": "hello",
"b": "world"}},
indent=2),
json.dumps({"x": 10, "y": 20, "info": {"a": "test",
"b": "example",
"c": "demo"}},
indent=2)
]
}
df = pd.DataFrame(data)
# 指定保存的 Excel 文件路徑
path = "complex_data_sequence.xlsx"
# 保存 DataFrame 到 Excel
df.to_excel(path, sheet_name='Data Sequence',
index=False, engine='openpyxl')
# 加載工作簿以調整col寬和row高
workbook = load_workbook(path)
worksheet = workbook['Data Sequence']
# 調整col寬,並為包含 JSON 的列啟用文本自動換行
for col in worksheet.columns:
max_length = 0
column = col[0].column # 獲取col number: 1->A ; 2->B ; 3->C
column_letter = get_column_letter(column)
for cell in col:
if cell.value: # 检查单元格是否有内容
cell.alignment = Alignment(wrap_text=True)
cell_length = max(len(line) for line in str(cell.value).split('\n'))
max_length = max(max_length, cell_length)
worksheet.column_dimensions[column_letter].width = max_length + 2
# 調整row高,考慮到 JSON 字符串的row數
for row in worksheet.iter_rows(min_row=2,
max_col=worksheet.max_column,
max_row=worksheet.max_row):
for cell in row:
if cell.column == 2: # 假設 JSON 數據在第二col
formatted_json = json.dumps(json.loads(cell.value), indent=2)
line_count = formatted_json.count('\n') + 1
worksheet.row_dimensions[cell.row].height = line_count * 15
# 假設每row高度15
# 保存調整後的 Excel 文件
workbook.save(path)
print(f"Excel 文件已經調整並保存到'{path}'。")code:
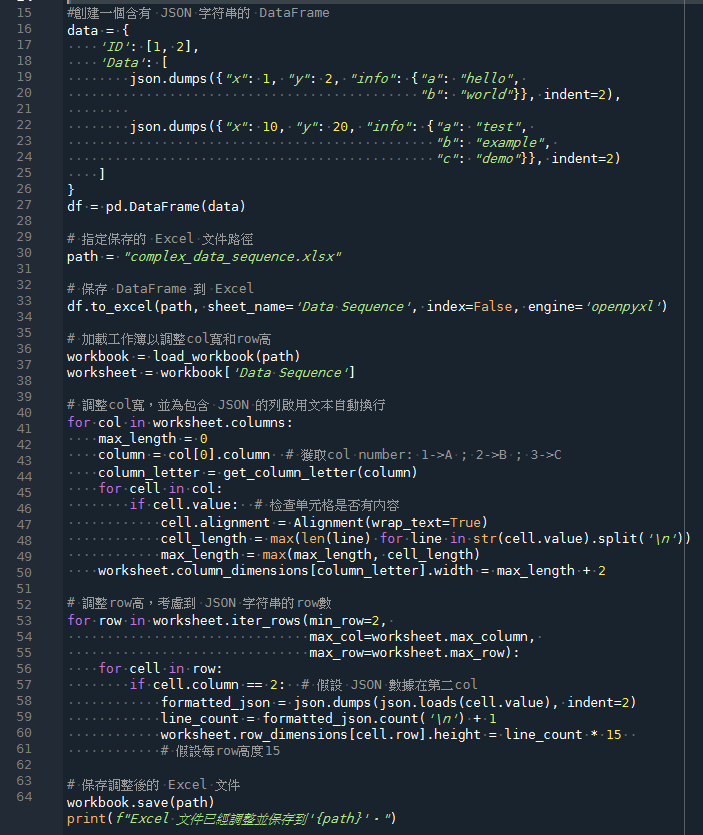
輸出的xlsx:

推薦hahow線上學習python: https://igrape.net/30afN
![Python 如何做excel的樞紐分析? pandas.pivot_table() 或 pandas.DataFrame .groupby() ; 如何指定欄位順序? DataFrame.reindex() ; .sortlevel() ; DataFrame[[col1, col2, col3 ]] ; df.columns.map() ; 如何顯示所有欄? pandas.set_option (“display.max_columns”, None)](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2023/03/20230323101848_80.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python 如何做excel的樞紐分析? pandas.pivot_table() 或 pandas.DataFrame .groupby() ; 如何指定欄位順序? DataFrame.reindex() ; .sortlevel() ; DataFrame[[col1, col2, col3 ]] ; df.columns.map() ; 如何顯示所有欄? pandas.set_option (“display.max_columns”, None)")
![Python: matplotlib如何設定座標軸刻度? plt.xticks(seq, labels) ;如何生成fig, ax物件? fig = plt.figure(figsize= (10.24, 7.68)) ; ax = fig.add_subplot() ; fig, ax = plt.subplots(figsize=(10.24, 7.68)) ; 如何使用中文? plt.rcParams[“font.family”] = [“Microsoft JhengHei”]](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2023/02/20230209083006_41.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: matplotlib如何設定座標軸刻度? plt.xticks(seq, labels) ;如何生成fig, ax物件? fig = plt.figure(figsize= (10.24, 7.68)) ; ax = fig.add_subplot() ; fig, ax = plt.subplots(figsize=(10.24, 7.68)) ; 如何使用中文? plt.rcParams[“font.family”] = [“Microsoft JhengHei”]")
; typing : np.ndarray")
![Python: pandas.DataFrame如何移除所有空白列?pandas.isna( df_raw[0] ).tolist() ; df_drop0 = df_raw.drop(nanIdx,axis=0).reset_index(drop=True)](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2022/12/20221206184635_4.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: pandas.DataFrame如何移除所有空白列?pandas.isna( df_raw[0] ).tolist() ; df_drop0 = df_raw.drop(nanIdx,axis=0).reset_index(drop=True)")
:台灣龍頭電信線路466吃到飽(不限速,不綁約,免預繳),吃不完還給你,月租最低只要166,養門號都划算;輸入推薦碼 L672PMU5 就送連續6個月帳單折抵$100,等同$450上網吃到飽6個月;無框出任務:有機會獲得100元帳單減免")

位置? ax.legend( bbox_to_anchor = (1, 1), borderaxespad=0)")
 ; pandas.Series() 的isin() 函式")


近期留言