collections.Counter 是專門用來做
“可雜湊元素的頻率統計”的 dict 子類。
核心概念:Counter = dict where
key = item,
value = 出現次數(int >= 0)。
比普通 dict 多一組方便的初始化 / 運算方法。
1. 建立 Counter 的幾種方式
from collections import Counter
Counter(['a', 'b', 'a']) # {'a': 2, 'b': 1}
Counter('banana') # {'a':3,'n':2,'b':1}
Counter({'a': 2, 'b': 5}) # 直接用 dict
Counter(a=2, b=5) # 關鍵字參數空的:
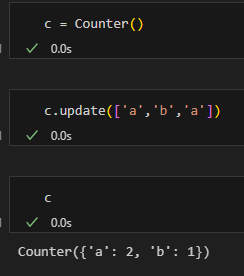
c = Counter()遞增:
c.update(['a','b','a'])輸出:
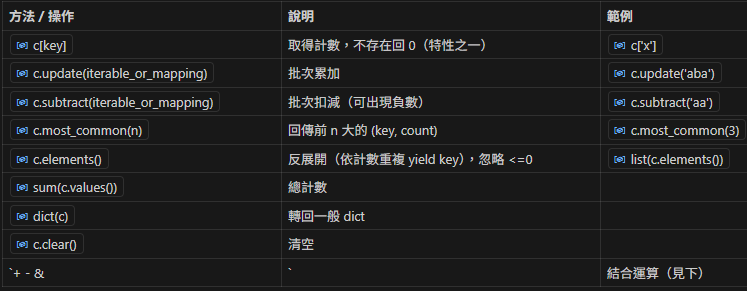
2. 常用屬性與方法
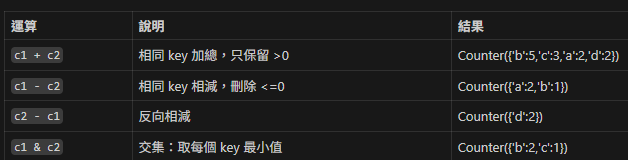
3. 與數學運算子的結合
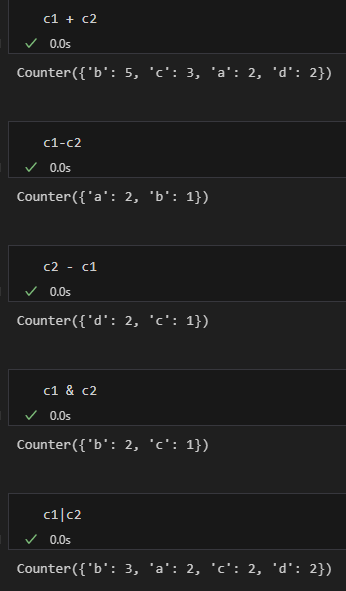
假設:
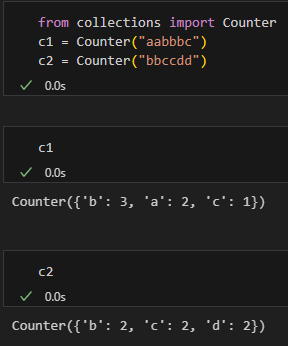
from collections import Counter
c1 = Counter("aabbbc")
c2 = Counter("bbccdd")運算:
c1 / c2:
運算 與 交集/聯集:
4. 典型實戰場景
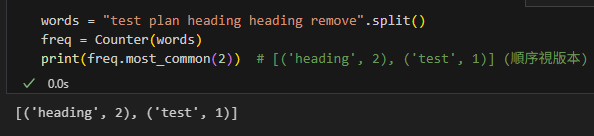
4.1 統計字元 / 詞頻
words = "test plan heading heading remove".split()
freq = Counter(words)
print(freq.most_common(2)) # [('heading', 2), ('test', 1)] (順序視版本)輸出:
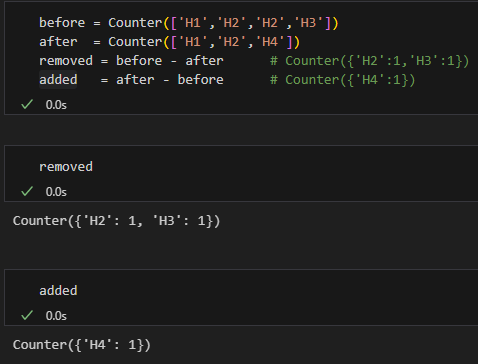
4.2 比較兩組元素差異
before = Counter(['H1','H2','H2','H3'])
after = Counter(['H1','H2','H4'])
removed = before - after # Counter({'H2':1,'H3':1})
added = after - before # Counter({'H4':1})輸出:
4.3 正規化“分層編號”時的層級計數
counters = Counter()
# 每遇到 level = L 的 heading:
counters[L] += 1
# 取得目前路徑
path = '.'.join(str(counters[i]) for i in range(1, L+1))(也可以用普通 dict;
Counter 的好處是缺席 key 自動回 0)
4.4 計算多個來源合併頻率
total = Counter()
for chunk in chunks: # 每個 chunk 是 list 或字串
total.update(chunk)4.5 找出“不平衡”或“負數異常”
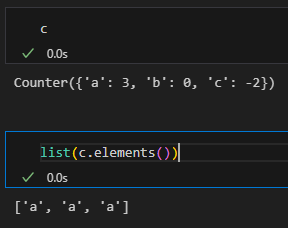
c = Counter("aab")
c.subtract("abc") # a:1, b:0, c:-1
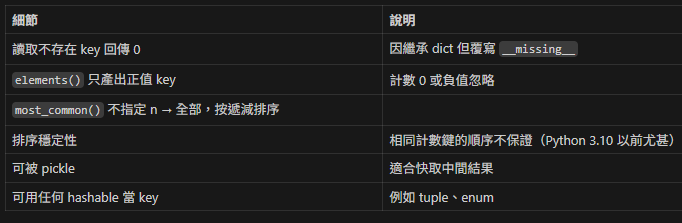
negatives = {k:v for k,v in c.items() if v < 0}5. 常被忽略的細節
6. 與 defaultdict(int) 差異
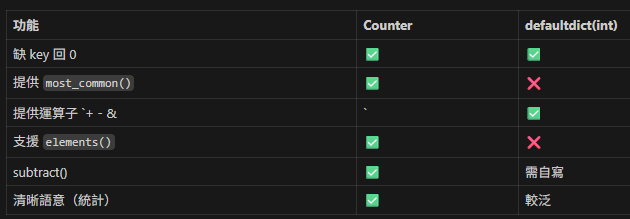
如果你只做“線性累加”且不需要報表功能,兩者都可;
若要排名、集合運算 → 用 Counter。
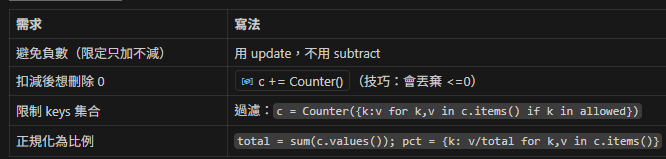
7. 防禦性小技巧
8. 與(章節編號 / 刪除報表)結合範例
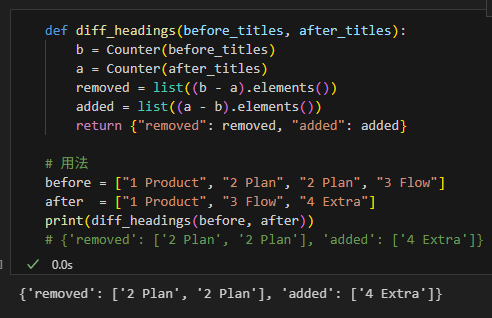
8.1 建立刪除前後差異報告
def diff_headings(before_titles, after_titles):
b = Counter(before_titles)
a = Counter(after_titles)
removed = list((b - a).elements())
added = list((a - b).elements())
return {"removed": removed, "added": added}
# 用法
before = ["1 Product", "2 Plan", "2 Plan", "3 Flow"]
after = ["1 Product", "3 Flow", "4 Extra"]
print(diff_headings(before, after))
# {'removed': ['2 Plan', '2 Plan'], 'added': ['4 Extra']}輸出:
list(c.elements()):
8.2 計算每個 level 出現次數(驗證層級合理性)
levels = [1,1,2,2,3,1,2,3,3]
level_counter = Counter(levels)
# 假設最大層級不能超過 3,且每層至少 1
invalid = [lvl for lvl,cnt in level_counter.items() if lvl < 1 or lvl > 3 or cnt == 0]8.3 生成 slug 衝突處理次序
slugs = ["test-flow","test-flow","test-flow","plan"]
c = Counter()
unique = []
for s in slugs:
c[s] += 1
if c[s] == 1:
unique.append(s)
else:
unique.append(f"{s}-{c[s]}")
# ['test-flow','test-flow-2','test-flow-3','plan']9. 效能概念
- 基於 dict → 單次計數操作平均 O(1)
- 與手寫 dict +=1 相比 overhead 很低(多數場景可忽略)
- 大量合併建議:改用
update一次餵 iterable 避免 Python 層 for-loop
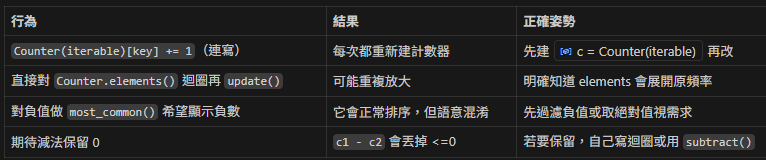
10. 小心誤用(常見雷點)
11. 超精簡備忘(可貼註解)
from collections import Counter
c = Counter() # 建立
c.update(data) # 加
c.subtract(other) # 減(允許負數)
top3 = c.most_common(3) # 前 3
intersection = c1 & c2 # min
union = c1 | c2 # max
positive_only = +c # 等價 c - Counter();過濾 <=0
expanded = list(c.elements())(+c 在某些版本等價於 c.copy() 再丟棄 <=0 的值,語意上是“去掉非正”。)
+c(一元加號 / unary plus)跟 c += …(就地加法)是兩件完全不同的東西:
+c 是什麼?
對 collections.Counter 物件做「一元加號」
會回傳一個「新的 Counter」,
把所有計數 <= 0 的 key 濾掉。
官方文件的定義(邏輯上等同):
+c == c – Counter()
(做一次“與空 Counter 的減法”會刪除非正值)。
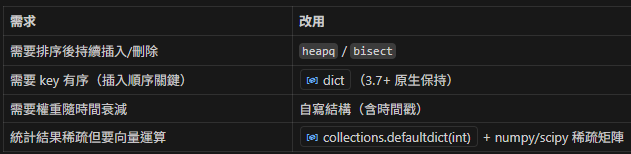
12. 何時不要用 Counter
13. 自製封裝
快速統計“刪掉章節/新增章節差異”:
def summarize_heading_changes(before, after):
before_set = Counter(before)
after_set = Counter(after)
removed = before_set - after_set
added = after_set - before_set
return {
"removed_count": sum(removed.values()),
"added_count": sum(added.values()),
"removed_list": list(removed.elements()),
"added_list": list(added.elements()),
}14. 一句話總結
Counter = “比 dict 多一組天然頻率操作、
集合運算、排名與批次加減的統計容器”,
適合任何“離散元素出現次數”問題,
尤其是處理 heading 層級、slug 去重、章節差異這些任務。
推薦hahow線上學習python: https://igrape.net/30afN
 or(|) xor(^) not ; assert 預期為真的條件式, “錯誤訊息” ; 條件式為真的話,繼續往下跑,否則AssertionError: “錯誤訊息”")
 在不同資料類型(array/dict)下的 columns 參數用法 #賦值 #選擇")
![Python: 自定義函數計算計程車車資(先typing,再用預設值), 巢狀字典以及typing.Union[ ], assert 斷言](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2022/09/20220923222039_57.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: 自定義函數計算計程車車資(先typing,再用預設值), 巢狀字典以及typing.Union[ ], assert 斷言")
 : from openai import OpenAI ; client = OpenAI (api_key = api_key) ; response = client .audio .speech .create( model= “tts-1-hd”, input= text_content, response_format= “mp3”)")
 ; y_new = np.polyval(coeffs, x_new) ; p = np.poly1d(coeffs) ; print(p(x_new)) #效果同 np.polyval(coeffs, x_new)")
.resolve().parent")
")
: #range參數不含結束值")
 ; 那些參數可以設為None?")

近期留言