本文教你如何將以 python-docx 擷取的 Word 標題(Heading 1/2/3)資料,新增一個連續的章節編號欄位 full_num_path。即使原本的 num_text 因刪除或重排而不連續,也能依實際出現順序重編為 1、1.1、1.1.1、2、2.1、2.1.1 等規則化編號。
適合讀者
- 已用 python-docx 擷取 Word 的章節、節、小節資訊
- 希望得到「連續且一致」的章節編號,方便渲染目錄、生成側邊目錄、匯出 JSON 等
目標說明
- 輸入:List[dict],每個 dict 至少包含 raw、style、level、num_text、title
- 輸出:在原 dict 上新增 full_num_path,代表依出現順序重新計算的連續編號
- 支援層級:1、2、3(可擴充)
核心想法
- 維護一個層級計數器 lvl_cnt,如 {1:0, 2:0, 3:0}
- 遇到某層 level:
- 該層計數 +1
- 將更深層的計數清零(確保子層從 1 開始)
- 以 1..level 的計數串成 full_num_path(用點號連接)
- 若 level 不在 {1,2,3},可選擇跳過或拋錯
完整程式碼
from typing import List, Dict
def assign_full_num_path(items: List[Dict]) -> List[Dict]:
"""
依據出現順序為 Heading 1/2/3 新增連續編號 full_num_path。
例:
level=1 -> 1, 2, 3, ...
level=2 -> x.1, x.2, ...
level=3 -> x.y.1, x.y.2, ...
"""
lvl_cnt = {1: 0, 2: 0, 3: 0}
valid_levels = set(range(1,4))
# {1, 2, 3}
for item in items:
level = item.get("level", None)
if level not in valid_levels:
# 也可改為:raise ValueError(f"Invalid level: {level}")
# 不修改 item,但也可選擇 item["full_num_path"] = None
continue
# 當前層 +1
lvl_cnt[level] += 1
# 更深層歸零
for deeper in range(level + 1, max(valid_levels)+1):
lvl_cnt[deeper] = 0
# 產生 full_num_path
parts = [str(lvl_cnt[l]) for l in range(1, level + 1)]
item["full_num_path"] = ".".join(parts)
#item["full_num_path"] = ".".join(str(lvl_cnt[i]) for i in range(1, level + 1))
#generator expression
return items
if __name__== "__main__":
data = [
{"raw":"1\t章標題","style":"Heading 1","level":1,"num_text":"1","title":"章標題"},
{"raw":"1.1\t節標題","style":"Heading 2","level":2,"num_text":"1.1","title":"節標題"},
{"raw":"1.1.1\t小節標題","style":"Heading 3","level":3,"num_text":"1.1.1","title":"小節標題"},
# 假設中間有刪除,導致 num_text 不連續
{"raw":"3\t章標題","style":"Heading 1","level":1,"num_text":"3","title":"章標題(實際第2章)"},
{"raw":"3.5\t節標題","style":"Heading 2","level":2,"num_text":"3.5","title":"節標題(實際第2.1節)"},
{"raw":"3.5.10\t小節標題","style":"Heading 3","level":3,"num_text":"3.5.10","title":"小節標題(實際第2.1.1)"},
]
updated = assign_full_num_path(data)
for it in updated:
print(it)輸出:
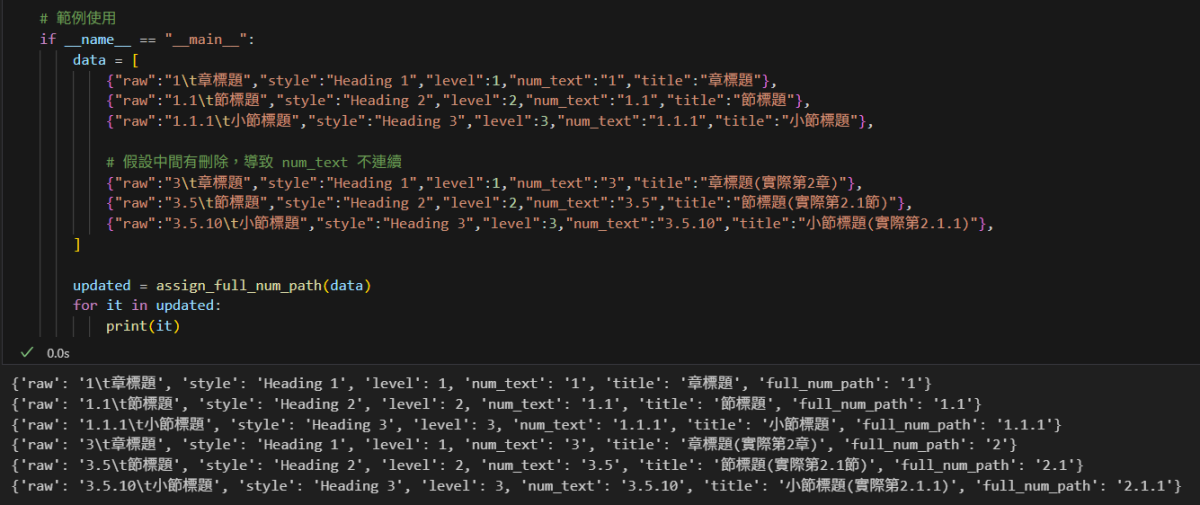
使用範例
- 假設原始資料中 num_text 可能不連續(例如 3、3.5、3.5.10),執行上述函式後,會回填連續的 full_num_path,如 2、2.1、2.1.1。
- 這樣能將「視覺上的章節順序」與「實際的編號」一致化,避免生成目錄或側邊欄時出現跳號。
常見情境與處理
- 新增或刪除章節後,num_text 出現跳號:使用 full_num_path 當作標準化編號輸出。
- 需要維持舊編號作為參考:保留原 num_text,並新增 normalized_num 同步等於 full_num_path。
- 有超過 3 層需求:把 lvl_cnt 與 valid_levels 擴充到需要的最大層,例如到 6;同時把 for deeper 的範圍上限改為最大層 + 1。
擴充到 N 層的小技巧
- 用 max_level = N 動態控制:
- lvl_cnt = {i: 0 for i in range(1, max_level + 1)}
- valid_levels = set(lvl_cnt.keys())
- 清零時 for deeper in range(level + 1, max_level + 1)
實務整合建議
- 與 python-docx 結合時,先把每個段落判斷 style 是否為 Heading 1/2/3,並標記對應 level
- 建好 items 後,呼叫 assign_full_num_path
- 後續可用這個連續編號輸出:
- JSON 給前端生成目錄樹
- Markdown/HTML 轉換時的標題前綴
- 自動產生目錄(TOC)或側邊導覽
驗證與測試
- 針對以下情境撰寫測試:
- 單層連續 H1:1, 2, 3
- H1-H2 交錯:1, 1.1, 1.2, 2, 2.1
- 刪除/跳號:num_text 不連續但 full_num_path 仍連續
- 非法 level:應跳過或拋錯(視需求)
總結
- 這個方法不用動到原始 num_text,即可得到穩定、連續的章節編號欄位 full_num_path
- 易於擴充到更多層級,且能與現有的 python-docx 萃取流程順利銜接
- 可直接套用到各種輸出(JSON、前端目錄、報表導覽)以確保章節排序一致與美觀
推薦hahow線上學習python: https://igrape.net/30afN
與tuple, set, issubset(), issuperset()")
 #pd.DataFrame.from_dict")

")
![Python 如何用pandas.Series.nsmallest() 找到n個與target差距最小的index?再從中找到距離idxmax最近的index?避免誤抓sidelobes的index? targetIdx = (serMean-target_value).abs().nsmallest(n).index.tolist() ;Series切片: .loc[標籤名1:標籤名2] (會含標籤名2) ; .iloc[位置1:位置2] (不含位置2)](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2023/02/20230222082954_53.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python 如何用pandas.Series.nsmallest() 找到n個與target差距最小的index?再從中找到距離idxmax最近的index?避免誤抓sidelobes的index? targetIdx = (serMean-target_value).abs().nsmallest(n).index.tolist() ;Series切片: .loc[標籤名1:標籤名2] (會含標籤名2) ; .iloc[位置1:位置2] (不含位置2)")
 ; OrderedDict.fromkeys()")
, f.write(datanew)")
 實戰:教你如何讓程式碼「自我介紹」; func_name = sys._getframe().f_code.co_name ; inspect.currentframe().f_code.co_name")


近期留言