`Himalia4FWGenUUID4ProcessStep_2` 應該怎麼切,
才能讓第一階段 pattern 的每一段都有機會派上用場?
## 1. 目標輸出
這次故意用一個更完整的例子:
Himalia4FWGenUUID4ProcessStep_2
我們要的不是一開始就拆到最細,而是先保留比較完整的 token,
再補出更細的 token。
也就是:
Himalia4FWGenUUID4ProcessStep_2
-> Himalia4, FW, Gen, UUID4, Process, Step, 2
-> Himalia4 再拆成 Himalia, 4
-> UUID4 再拆成 UUID, 4最終保留:
Himalia4
Himalia
4
UUID4
UUID
4
FW
Gen
Process
Step
2如果還需要完整 class key,再額外補上:
himalia4fwgenuuid4processstep_2
## 2. 先講核心規則
規則只有兩步:
1. 第一階段先切出較大的 segment
2. 若 segment 是 `Himalia4` 或 `UUID4` 這種英數混合 token,
就先保留它,再把它細拆
所以這個例子會變成:
Himalia4FWGenUUID4ProcessStep_2
-> [Himalia4] [FW] [Gen] [UUID4] [Process] [Step] [2]
-> [Himalia] [4] 只從 Himalia4 補出來
-> [UUID] [4] 只從 UUID4 補出來## 3. 第一階段 regex
第一階段的目標是先得到:
["Himalia4", "FW", "Gen", "UUID4", "Process", "Step", "2"]可以用這個 pattern:
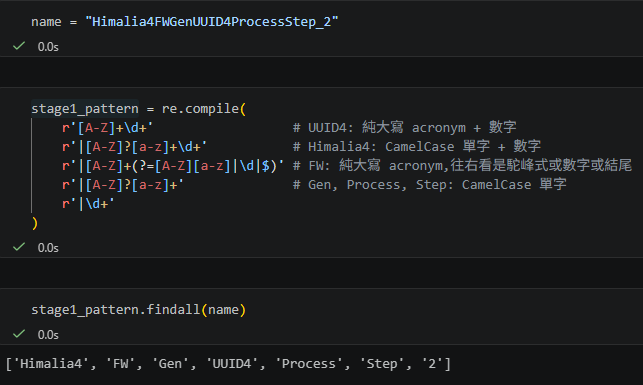
stage1_pattern = re.compile(
r'[A-Z]+\d+' # UUID4: 純大寫 acronym + 數字
r'|[A-Z]?[a-z]+\d+' # Himalia4: CamelCase 單字 + 數字
r'|[A-Z]+(?=[A-Z][a-z]|\d|$)' # FW: 純大寫 acronym,往右看是駝峰式或數字或結尾
r'|[A-Z]?[a-z]+' # Gen, Process, Step: CamelCase 單字
r'|\d+'
)這個例子裡,實際會命中的第一階段片段是:
[‘Himalia4’, ‘FW’, ‘Gen’, ‘UUID4’, ‘Process’, ‘Step’, ‘2’]
`[A-Z]+(?=[A-Z][a-z]|\d|$)` 這段是專門拿來抓「純大寫 acronym」的,
而且它不是一直往後吃,而是只吃到下一個合理邊界為止。
白話講,它的意思是:
– 先吃掉連續大寫字母,例如 `FW`、`UUID`、`BMC`
– 但只有在右邊接下來是這三種情況之一時,這段匹配才成立:
– 下一段 CamelCase 單字的開頭,例如 `FWGen` 裡的 `G`
– 下一段數字,例如 `UUID4` 裡的 `4`
– 或者字串已經結束
所以:
– `FWGen` 會抓到 `FW`,因為後面是 `Gen`
– `UUID4` 會先看到 `UUID` 右邊是數字 `4`
– `BMC` 這種結尾 acronym 也能成立,因為右邊就是字串結尾
如果沒有後面的 `(?=[A-Z][a-z]|\d|$)`,只寫 `[A-Z]+`,
那它就太容易吃過頭,例如在 `FWGen` 這種情況下,
很可能把 `G` 也一起吃進去。
這次故意選 `Himalia4FWGenUUID4ProcessStep_2`,
就是要讓第一階段五段都各自命中一次:
– `[A-Z]+\d+` 命中 `UUID4`
– `[A-Z]?[a-z]+\d+` 命中 `Himalia4`
– `[A-Z]+(?=[A-Z][a-z]|\d|$)` 命中 `FW`
– `[A-Z]?[a-z]+` 命中 `Gen`、`Process`、`Step`
– `\d+` 命中尾端獨立的 `2`
## 4. 第二階段 regex
第二階段只處理我們明確想補拆的混合片段。
在這個例子裡,就是:
"Himalia4" -> ["Himalia", "4"]
"UUID4" -> ["UUID", "4"]第二階段不是看到英數混合就全拆。
白話講,這裡其實是在做兩件事:
1. 先用 `stage1_pattern` 把整串切成大塊
2. 再從這些大塊裡挑出「還要再拆一次」的 token
`should_split_again_pattern` 做的不是分詞,
而是在問:
這個 token,要不要再進第二階段細切?
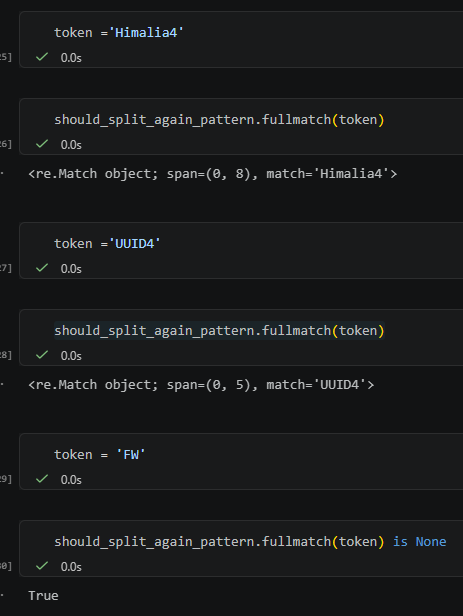
在這個例子裡:
– `Himalia4`:要再拆
– `UUID4`:要再拆
– `FW`:不用
– `Gen`:不用
– `Process`:不用
– `Step`:不用
– `2`:不用
所以可以直接用這個判斷條件:
should_split_again_pattern = re.compile(
r'[A-Z]+\d+'
r'|[A-Z]?[a-z]+\d+'
)意思是:
– `UUID4` 要再拆
– `Himalia4` 要再拆
– `FW`、`Gen`、`Process`、`Step` 不進第二階段
也就是說,這段比較像「挑人」的規則,不是「切字」的規則。
### 為什麼不能省掉 `should_split_again_pattern`
因為如果省掉它,程式就會變成:
for token in stage1_tokens:
result.append(token)
result.extend(subtoken_pattern.findall(token))這樣一來,每個 stage1 token 都會再被細切一次。
問題是,`Gen`、`Process`、`Step` 這些 token 本來就不該再拆;
它們如果又跑一次 `subtoken_pattern`,通常只會再產生一次自己。
例如:
"Gen" -> ["Gen"]
"Process" -> ["Process"]
"Step" -> ["Step"]結果就會平白多出一份重複內容,像這樣:
['Himalia4', 'Himalia', '4', 'FW', 'FW', 'Gen', 'Gen', 'UUID4', 'UUID', '4', 'Process', 'Process', 'Step', 'Step', '2', '2']所以 `should_split_again_pattern` 不能省。
它真正的功能其實很單純:
> 防止不該拆的 token 被重拆。
而第二階段真正拿來拆的 pattern 可以寫成:
subtoken_pattern = re.compile(
r'[A-Z]+(?=\d|$)' # UUID
r'|[A-Z]?[a-z]+' # Himalia
r'|\d+' # 4
)這樣 `UUID4` 會拆成 `UUID`、`4`,`Himalia4` 會拆成 `Himalia`、`4`。
## 5. 可直接執行的 Python code
下面這段就是可直接執行的版本,而且不用 `def`:
import re
name = "Himalia4FWGenUUID4ProcessStep_2"
stage1_pattern = re.compile(
r'[A-Z]+\d+'
r'|[A-Z]?[a-z]+\d+'
r'|[A-Z]+(?=[A-Z][a-z]|\d|$)'
r'|[A-Z]?[a-z]+'
r'|\d+'
)
should_split_again_pattern = re.compile(
r'[A-Z]+\d+'
r'|[A-Z]?[a-z]+\d+'
)
subtoken_pattern = re.compile(
r'[A-Z]+(?=\d|$)'
r'|[A-Z]?[a-z]+'
r'|\d+'
)
stage1_tokens = stage1_pattern.findall(name)
print(stage1_tokens)
# ['Himalia4', 'FW', 'Gen', 'UUID4', 'Process', 'Step', '2']
result = []
for token in stage1_tokens:
result.append(token)
# 這裡用 fullmatch,不用 match。
# 因為我們要確認「整個 token」都符合可再拆的型態,
# 不是只看開頭剛好像 Himalia4 / UUID4 就算通過。
if should_split_again_pattern.fullmatch(token):
result.extend(subtoken_pattern.findall(token))
print(result)
# ['Himalia4', 'Himalia', '4', 'FW', 'Gen', 'UUID4', 'UUID', '4', 'Process', 'Step', '2']
result_with_full_key = result + [name.lower()]
print(result_with_full_key)
# ['Himalia4', 'Himalia', '4', 'FW', 'Gen', 'UUID4', 'UUID', '4', 'Process', 'Step', '2', 'himalia4fwgenuuid4processstep_2']## 6. 預期輸出
第一個 `print(stage1_tokens)` 應該是:
['Himalia4', 'FW', 'Gen',
'UUID4', 'Process', 'Step', '2']第二個 `print(result)` 應該是:
['Himalia4', 'Himalia', '4', 'FW', 'Gen',
'UUID4', 'UUID', '4', 'Process', 'Step', '2']第三個 `print(result_with_full_key)` 應該是:
['Himalia4', 'Himalia', '4', 'FW', 'Gen',
'UUID4', 'UUID', '4', 'Process', 'Step', '2', 'himalia4fwgenuuid4processstep_2']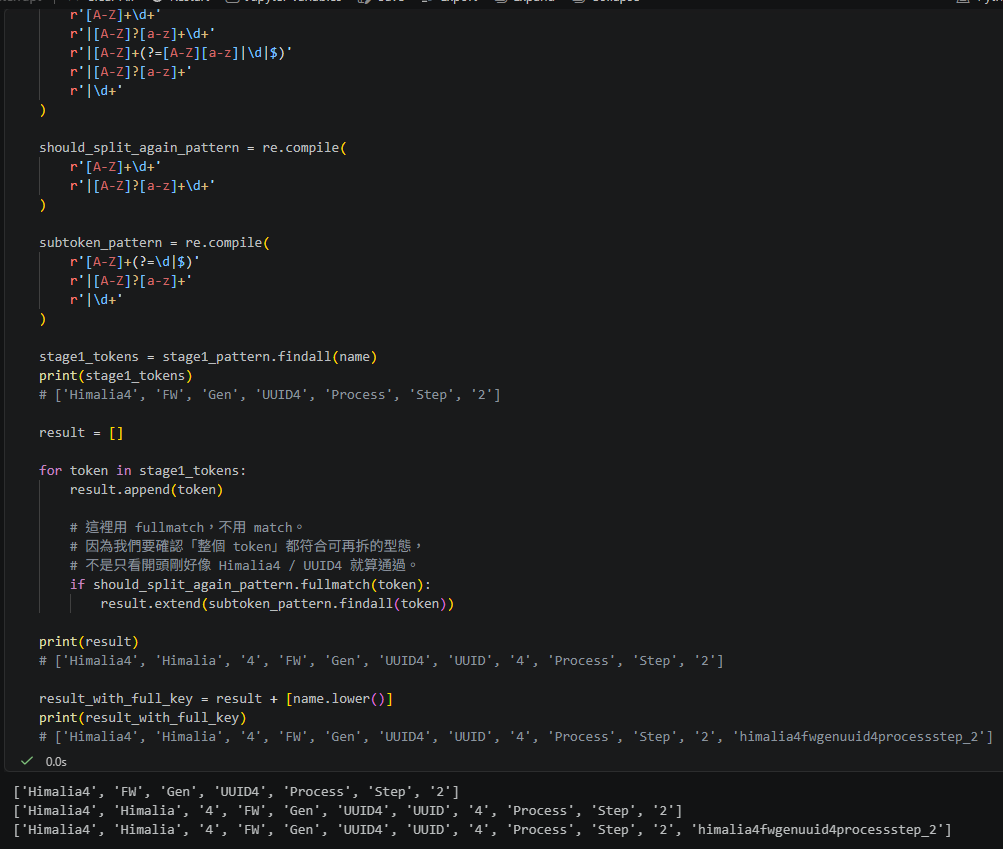
## 7. 為什麼這樣切是對的
因為它同時保留了三層資訊:
1. `Himalia4` 與 `UUID4` 這種較完整、較有辨識度的 compact segment
2. `Himalia`、`UUID` 與兩個 `4` 這種更細粒度的子 token
3. `FW`、`Gen`、`Process`、`Step`、`2` 這種已經夠清楚、因此不用再拆的片段
如果你一開始就直接拆成:
['Himalia', '4', 'FW', 'Gen', 'UUID', '4', 'Process', 'Step', '2']那 `Himalia4` 和 `UUID4` 這一層資訊就不見了。
## 8. 一句話收尾
`Himalia4FWGenUUID4ProcessStep_2` 的理想切法,
就是先保留 `Himalia4`、`FW`、`Gen`、`UUID4`、`Process`、`Step`、`2`,
再只對 `Himalia4` 與 `UUID4` 做第二階段補拆,最後得到:
['Himalia4', 'Himalia', '4', 'FW', 'Gen',
'UUID4', 'UUID', '4', 'Process', 'Step', '2']推薦hahow線上學習python: https://igrape.net/30afN
使用物件導向OOP (Object-Oriented Programming) 封裝
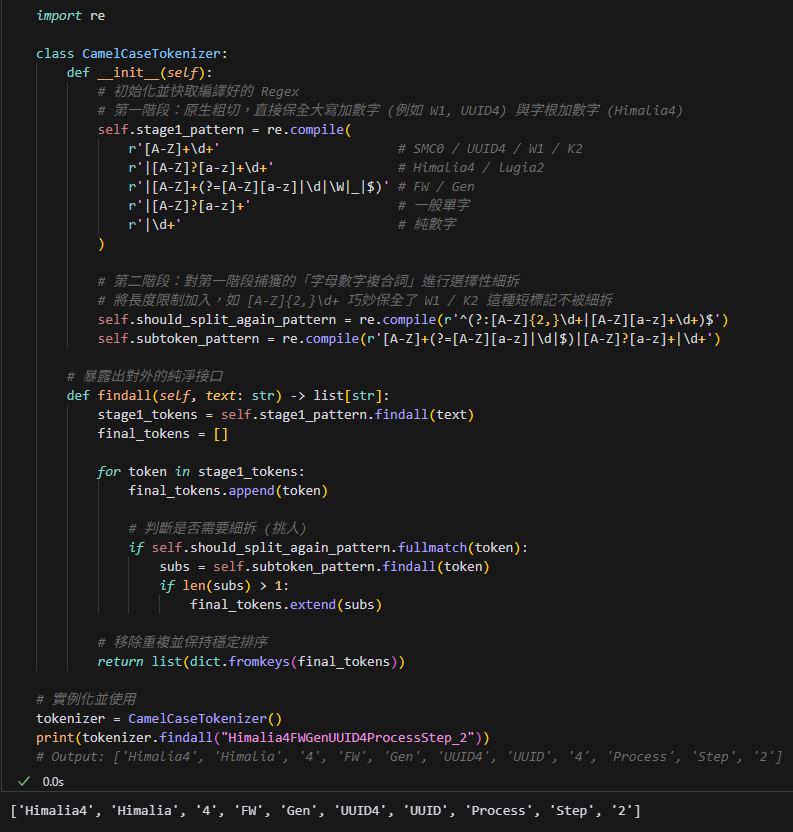
import re
class CamelCaseTokenizer:
def __init__(self):
# 初始化並快取編譯好的 Regex
# 第一階段:原生粗切,直接保全大寫加數字 (例如 W1, UUID4) 與字根加數字 (Himalia4)
self.stage1_pattern = re.compile(
r'[A-Z]+\d+' # SMC0 / UUID4 / W1 / K2
r'|[A-Z]?[a-z]+\d+' # Himalia4 / lugia2
r'|[A-Z]+(?=[A-Z][a-z]|\d|\W|_|$)' # FW / Gen
r'|[A-Z]?[a-z]+' # 一般單字
r'|\d+' # 純數字
)
# 第二階段:對第一階段捕獲的「字母數字複合詞」進行選擇性細拆
# 將長度限制加入,如 [A-Z]{2,}\d+ 巧妙保全了 W1 / K2 這種短標記不被細拆
self.should_split_again_pattern = re.compile(r'^(?:[A-Z]{2,}\d+|[A-Z][a-z]+\d+)$')
self.subtoken_pattern = re.compile(r'[A-Z]+(?=[A-Z][a-z]|\d|$)|[A-Z]?[a-z]+|\d+')
# 暴露出對外的純淨接口
def findall(self, text: str) -> list[str]:
stage1_tokens = self.stage1_pattern.findall(text)
final_tokens = []
for token in stage1_tokens:
final_tokens.append(token)
# 判斷是否需要細拆 (挑人)
if self.should_split_again_pattern.fullmatch(token):
subs = self.subtoken_pattern.findall(token)
if len(subs) > 1:
final_tokens.extend(subs)
# 移除重複並保持穩定排序
return list(dict.fromkeys(final_tokens))
# 實例化並使用
tokenizer = CamelCaseTokenizer()
print(tokenizer.findall("Himalia4FWGenUUID4ProcessStep_2"))
# Output: ['Himalia4', 'Himalia', '4', 'FW', 'Gen', 'UUID4', 'UUID', '4', 'Process', 'Step', '2']# 實例化並使用
推薦hahow線上學習python: https://igrape.net/30afN
,計算元大人壽美滿人生(F1) IRR,免費下載IRR計算機")
 客戶端:Azure、OpenAI 與 Poe 整合指南")


 .upper() .lower()")


 函數; from docx.oxml.ns import qn #qualified name ; qn(‘w:p’) ; qn(‘w:tbl’)")
 ; from sklearn.tree import DecisionTreeClassifier ; tree = DecisionTreeClassifier(criterion = “gini”) #criterion = “entropy” #criterion: 標準,準則")

近期留言