這篇會用 Python re 模組 來講清楚三個很常一起出現、卻也很容易混淆的東西:
re.split()\W|_flags=re.ASCII
也會順便說明:
\w/\W到底是什麼- 為什麼中文會影響匹配結果
- 什麼時候用
re.split()反而比複雜 regex 更清楚
一、先認識 re.split()
re.split() 的用途是:
用「符合 regex 的分隔符」來切字串
一般字串切割你可能會寫:
text.split("_")但如果你的分隔符不只一種,例如:
_-- 空白
那 str.split() 就不夠方便了,這時可以用 re.split()。
基本語法
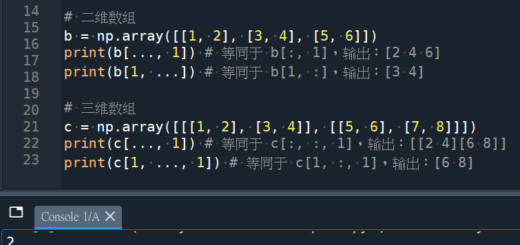
import re
re.split(pattern, text)pattern:分隔規則(regex)text:要切的字串
例子:同時用底線、連字號、空白切字串
import re
text = "ARGOS_V3-Rayado Peak"
parts = re.split(r'[_\-\s]+', text)
print(parts)輸出:
['ARGOS', 'V3', 'Rayado', 'Peak']這個 pattern 是什麼意思?
r'[_\-\s]+'代表:
_:底線\-:連字號-\s:空白字元+:一個以上連續出現都當成同一個分隔段
所以像:
ARGOS__V3 Rayado-Peak也能正確切開。
![Python 正規表達式教學:看懂 re.split()、W|_ 與 flags=re.ASCII # w代表 word character ~ [A-Za-z0-9_] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2026/04/20260430085117_0_0beced.png)
二、為什麼 re.split() 很實用?
因為很多時候你真正要做的不是:
「寫一條超複雜 regex 一次抓完所有 token」
而是:
「先把明顯分隔符切掉,再對每段做進一步分析」
這種做法通常有三個優點:
1. 可讀性高
你一看就知道分兩步:
- 第一步:切外層分隔符
- 第二步:處理每個片段
2. 好維護
之後如果你想加 . 或 /,只要改 split pattern。
3. 規則更單純
避免把所有條件都塞進 lookahead / lookbehind。
三、什麼是 \w 與 \W?
這兩個是 regex 常見 shorthand。
\w
代表 word character
\W
代表 non-word character
也就是「不是 \w 的字元」
在很多教學裡,\w 常被簡化理解成:
[A-Za-z0-9_]也就是:
- 英文大小寫
- 數字
- 底線
_
因此:\W
就可以理解成:
[^A-Za-z0-9_]範例
import re
text = "ABC_123-xy"
print(re.findall(r'\w+', text))
print(re.findall(r'\W+', text))輸出大致是:
![Python 正規表達式教學:看懂 re.split()、W|_ 與 flags=re.ASCII # w代表 word character ~ [A-Za-z0-9_] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2026/04/20260430090436_0_041472.png)
原因是:
ABC_123都是\w-是\W
四、那為什麼有時候會看到 \W|_?
這個寫法的意思是:
「非單字字元,或底線 _」
\W|_你可能會想問:
_不是本來就算在\W裡嗎?
答案是:
不是
因為 _ 屬於 \w,不是 \W
所以:
\W抓不到_- 如果你想把
_也當分隔條件,就要另外寫_
這就是為什麼會看到:
\W|_範例
import re
text = "ABC_123-xy"
print(re.split(r'\W+', text))
print(re.split(r'\W|_', text))輸出是:
![Python 正規表達式教學:看懂 re.split()、W|_ 與 flags=re.ASCII # w代表 word character ~ [A-Za-z0-9_] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2026/04/20260430090725_0_7e66a8.png)
解讀
r'\W+'
只會用非 word char 切
所以:
-會切_不會切
r'\W|_'
會用:
- 所有
\W - 以及
_
來切,所以 _ 也會成為分隔符。
五、re.split() 和 \W|_ 有什麼關係?
如果你寫:
re.split(r'\W|_', text)意思是:
用「非單字字元 或 底線」來切字串
這是一種很常見的切法。
例如:
import re
text = "ARGOS_V3-Test"
print(re.split(r'\W|_', text))輸出:
![Python 正規表達式教學:看懂 re.split()、W|_ 與 flags=re.ASCII # w代表 word character ~ [A-Za-z0-9_] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2026/04/20260430091001_0_f9a70f.png)
這和你手動列出分隔符很像。
但兩者思路不同
寫法 A:顯式列出分隔符
re.split(r'[_\-\s]+', text)寫法 B:使用字元類別
re.split(r'\W|_', text)差異在哪?
A 的特點
你明確指定:
_-- 空白
更可控、更直觀。
B 的特點
你把很多符號都交給 \W 處理,例如:
-./- 空白
(),
寫起來短,但抽象程度較高。
六、flags=re.ASCII 是什麼?
這是很多人第一次碰到會忽略、但實際很重要的設定。
flags=re.ASCII會讓某些 regex shorthand 按照 ASCII 規則 來判定,而不是 Unicode 規則。
特別重要的是:
\w\W\b\B
七、沒有 re.ASCII 時,中文會怎樣?
在 Python 3 預設情況下,regex 是 Unicode-aware 的。
這表示:
\w 不只包含英文數字底線,通常也包含中文等 Unicode 字元
例如:
import re
text = "ABC中文_123"
print(re.findall(r'\w+', text))輸出是:
![Python 正規表達式教學:看懂 re.split()、W|_ 與 flags=re.ASCII # w代表 word character ~ [A-Za-z0-9_] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2026/04/20260430091305_0_b29a14.png)
這代表:
A B C是\w中 文也是\w_123也是\w
所以整段被視為同一個 word token。
八、加上 flags=re.ASCII 會怎樣?
import re
text = "ABC中文_123"
print(re.findall(r'\w+', text, flags=re.ASCII))輸出是:
![Python 正規表達式教學:看懂 re.split()、W|_ 與 flags=re.ASCII # w代表 word character ~ [A-Za-z0-9_] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2026/04/20260430091435_0_998465.png)
因為在 ASCII 模式下:\w
比較接近:
[A-Za-z0-9_]中文不再被算進 \w。
九、所以 re.ASCII 可以怎麼理解?
可以用一句話理解:
讓 \w、\W 這類 shorthand 不把中文當成 word character
但更精確地說:
- 它不是「禁止中文出現」
- 而是讓 regex 的某些類別判定改用 ASCII 規則
所以像這樣的 pattern:
r'中文'即使用了 re.ASCII,還是能匹配中文。
十、re.split(r'\W|_', ...) 遇到中文時的差異
這是最值得注意的地方。
例子一:預設模式
# %%
import re
text = "ABC中文_123-xy"
print(re.split(r'\W|_', text))結果是:
![Python 正規表達式教學:看懂 re.split()、W|_ 與 flags=re.ASCII # w代表 word character ~ [A-Za-z0-9_] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2026/04/20260430091806_0_75f90c.png)
因為:
- 中文在預設下常被視為
\w - 所以
\W不會拿中文當分隔符 _會切-會切
例子二:ASCII 模式
import re
text = "ABC中文_123-xy"
print(re.split(r'\W|_', text, flags=re.ASCII))結果是:
![Python 正規表達式教學:看懂 re.split()、W|_ 與 flags=re.ASCII # w代表 word character ~ [A-Za-z0-9_] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2026/04/20260430092103_0_6aa550.png)
這時中文會被視為 \W,因此成為分隔區的一部分。
十一、為什麼會出現空字串 ''?
因為 re.split() 如果分隔符連續出現,或字串開頭/結尾剛好命中分隔條件,就可能產生空字串。
例如:
import re
text = "ABC中文_123"
print(re.split(r'\W|_', text, flags=re.ASCII))中文和 _ 連續造成切割,就可能出現空項。
![Python 正規表達式教學:看懂 re.split()、W|_ 與 flags=re.ASCII # w代表 word character ~ [A-Za-z0-9_] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2026/04/20260430092257_0_b18aca.png)
這時常見做法是過濾掉:
parts = [p for p in re.split(r'\W|_', text, flags=re.ASCII) if p]十二、什麼時候用 re.split(r'\W|_', ...)?
適合在你想快速做這種處理時:
- 非字母數字底線的符號都當分隔符
- 但
_也要額外算分隔符
例如很多 identifier normalization、tokenization 的前處理。
十三、什麼時候直接列出分隔符比較好?
如果你的資料格式很明確,例如你只想切:
_-- 空白
那這樣通常更好懂:
re.split(r'[_\-\s]+', text)因為它一眼就看得出規則。
這在處理:
- class names
- family names
- file naming conventions
- metadata 欄位
時尤其實用。
十四、兩種寫法怎麼選?
我建議這樣記:
用顯式 split:
re.split(r'[_\-\s]+', text)適合:
- 你知道要切哪些符號
- 規則固定
- 希望程式可讀性高
用 \W|_:
re.split(r'\W|_', text)適合:
- 你想把大部分非 word char 都當分隔符
- 不想一個一個列舉符號
- 你清楚
\w/\W會受 Unicode / ASCII 影響
十五、實務上最容易踩的坑
坑 1:以為 \W 包含 _
其實不包含,所以才會常看到:
\W|_坑 2:以為 \W 一定會把中文切掉
不一定。
在 Python 3 預設 regex 下,中文常常屬於 \w,所以不是 \W。
坑 3:忘記 re.ASCII 會改變 \w/\W 行為
同一個 regex,加不加 flags=re.ASCII,結果可能差很多。
十六、推薦的理解方式
把這三者拆開理解最清楚:
re.split()
是工具:用 regex 當分隔符切字串
\W|_
是分隔規則:非 word char 或底線
flags=re.ASCII
是匹配模式:讓 \w/\W 改用 ASCII 判定
十七、完整示範
import re
text = "ARGOS中文_V3-Test"
print("1. 顯式列分隔符")
print(re.split(r'[_\-\s]+', text))
print("2. 用 \\W|_,預設模式")
print(re.split(r'\W|_', text))
print("3. 用 \\W|_,ASCII 模式")
print(re.split(r'\W|_', text, flags=re.ASCII))輸出:
![Python 正規表達式教學:看懂 re.split()、W|_ 與 flags=re.ASCII # w代表 word character ~ [A-Za-z0-9_] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2026/04/20260430093042_0_45577e.png)
十八、這個例子說明了什麼?
顯式列分隔符
只切你指定的 _ - 空白
\W|_ 預設模式
中文不是 \W,所以效果看起來和上面很像
\W|_ + re.ASCII
中文變成非 \w,因此會被切開
十九、如果只是做英文命名切詞,我的建議是什麼?
如果你的資料本來就是偏英文命名規則,例如:
ARGOS_V3RayadoPeakXMLParser
那我通常會建議:
先用 re.split() 顯式切外層分隔符
re.split(r'[_\-\s]+', text)再對每段做 CamelCase 拆詞
這通常比直接依賴 \W|_ 更清楚、可控。
二十、總結
re.split()
用 regex 當分隔符切字串,適合先處理外層分隔符。
\W
表示非 word character,但 _ 不包含在內。
\W|_
代表「非 word character 或底線 _」,常用來做通用切詞。
flags=re.ASCII
會讓 \w/\W 等 shorthand 改採 ASCII 規則,中文不再被視為 \w。
實務建議
如果你知道要切哪些符號,顯式使用 re.split(r'[_\-\s]+', ...) 通常更直觀、更易維護。
推薦hahow線上學習python: https://igrape.net/30afN
二十一、補充:為什麼很多人會想談 Unicode?
前面我們提到:
\W|_re.split()flags=re.ASCII
這些主題一旦談到「中文為什麼沒被切開」、「為什麼加了 re.ASCII 結果不同」,就幾乎一定會碰到 Unicode。
也就是說,如果你看不懂 Unicode 在 regex 裡扮演什麼角色,就很容易搞不清楚 \w、\W 的行為差異。
二十二、Unicode 是什麼?
你可以先把 Unicode 理解成:
一套幫全世界文字編號的標準
英文、數字、中文、日文、韓文、emoji……
這些字元在電腦裡都需要有對應的編碼位置,而 Unicode 就是在做這件事。
例如:
A中あ😊
它們在 Unicode 裡都有各自的 code point。
二十三、為什麼 regex 會跟 Unicode 有關?
因為 regex 裡面像這種 shorthand:
\w\W\b\d\s
看起來很簡短,但它們到底「算哪些字元」,其實跟匹配模式有關。
在 Python 3 裡,regex 預設是走 Unicode-aware 的路線,這表示:
很多非 ASCII 字元,也可能被視為某種合法字元類別
所以你才會看到:
- 中文有時會被算進
\w - 不加
re.ASCII時,\W不一定會把中文當分隔符
二十四、先用一個觀念記住就好
預設模式
Python 3 的 re 會比較傾向用 Unicode 規則 來理解字元。
re.ASCII 模式
Python 3 的 re 會把某些 shorthand 改成只看 ASCII 範圍。
這就是前面結果不同的根本原因。
二十五、什麼叫 Unicode 範圍?
如果你在 regex 裡看到這種寫法:
[\u4e00-\u9fff]這就是在寫 Unicode 範圍。
意思是:
匹配 Unicode code point 從
\u4e00到\u9fff之間的字元
這一段常被拿來匹配「常見中文漢字區」。
二十六、最常見的中文範圍例子
r'[\u4e00-\u9fff]+'這通常會用來抓一段連續中文,例如:
import re
text = "ABC中文DEF"
print(re.findall(r'[\u4e00-\u9fff]+', text))![Python 正規表達式教學:看懂 re.split()、W|_ 與 flags=re.ASCII # w代表 word character ~ [A-Za-z0-9_] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2026/04/20260430094238_0_3ff60f.png)
這表示 regex 正在明確指定:
- 我要的是某段 Unicode 區間
- 不是靠
\w - 不是靠
\W - 而是直接指定「字元碼位範圍」
二十七、Unicode 範圍和 \w / \W 有什麼不同?
差別非常大。
\w
是「類別概念」
意思比較像:
這個字元在目前規則下算不算 word character?
[\u4e00-\u9fff]
是「明確列範圍」
意思比較像:
我只接受這一段 code point 內的字元
二十八、哪一種比較精準?
如果你的目標是:
我就是要抓某一段特定語系字元
那 Unicode 範圍通常更精準。
例如:
r'[\u4e00-\u9fff]+'它不依賴 \w 的定義,也不依賴 re.ASCII 是否開啟。
它就是直接說:我要這段 Unicode 區間內的字元。
二十九、但為什麼很多人還是覺得 Unicode 範圍難用?
因為它通常也是:
最難記、最不直覺的一種寫法
例如:
[\u4e00-\u9fff]你很難一眼看出來它代表什麼,除非你本來就熟。
而且還會產生很多疑問:
- 這段是不是全部中文?
- 有沒有漏掉延伸漢字?
- 標點算不算?
- 全形符號算不算?
- 簡體、繁體都包含嗎?
所以雖然它「精準」,但不一定「好用」。
三十、這也是為什麼 Unicode 範圍常被認為最難記
像:
\u4e00-\u9fff\u3400-\u4dbf
這些區間沒有太多語意線索,很少有人能自然背下來。
實務上常常是:
- 查資料
- 複製貼上
- 隔一陣子又忘
所以如果你只是要處理英文命名、token split、identifier normalization,
通常不會優先想用 Unicode 範圍。
三十一、Unicode 範圍的優點
雖然難記,但它有幾個明確優點。
1. 匹配目標明確
你指定哪個區間,就只抓哪個區間。
2. 不受 \w/\W 定義影響
不會因為有沒有加 re.ASCII 而改變意思。
3. 適合語系限制很明確的需求
例如你真的要檢查:
- 是否含中文
- 是否只允許中文與英文數字
- 是否抽取中文片段
三十二、Unicode 範圍的缺點
1. 不好記
這是最大問題。
2. 可讀性差
新手看到幾乎無法立刻理解。
3. 容易誤以為「這樣就涵蓋全部中文」
其實很多情況下,你抓的只是常用區,不一定真的涵蓋所有相關字元。
4. 維護成本高
未來別人接手程式時,不一定看得懂你的意圖。
三十三、簡單範例:抓出中文字串
import re
text = "Python正規表達式123"
chs = re.findall(r'[\u4e00-\u9fff]+', text)
print(chs)![Python 正規表達式教學:看懂 re.split()、W|_ 與 flags=re.ASCII # w代表 word character ~ [A-Za-z0-9_] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2026/04/20260430094535_0_39aa25.png)
這種寫法的意思很單純:
從字串裡找出連續的常見中文漢字區段
三十四、簡單範例:判斷字串是否包含中文
import re
text = "ARGOS中文_V3"
if re.search(r'[\u4e00-\u9fff]', text):
print("包含中文")
else:
print("不包含中文")![Python 正規表達式教學:看懂 re.split()、W|_ 與 flags=re.ASCII # w代表 word character ~ [A-Za-z0-9_] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2026/04/20260430094705_0_916c83.png)
三十五、簡單範例:只保留英文、數字、常見中文
import re
text = "ARGOS中文-V3!"
cleaned = re.sub(r'[^A-Za-z0-9\u4e00-\u9fff]+', '', text)
print(cleaned)![Python 正規表達式教學:看懂 re.split()、W|_ 與 flags=re.ASCII # w代表 word character ~ [A-Za-z0-9_] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2026/04/20260430094839_0_fc09dc.png)
這種寫法代表:
- 保留英文字母
- 保留數字
- 保留常見中文
- 其他符號移除
三十六、這和 re.ASCII 的思路有什麼不同?
差別可以這樣理解:
re.ASCII
是在改變 shorthand 的判定規則
例如:
\w\W
Unicode 範圍
是在直接指定你要哪些字元
三十七、一個對照例子
import re
text = "ABC中文_123"寫法一:看 \w
print(re.findall(r'\w+', text))
print(re.findall(r'\w+', text, flags=re.ASCII))![Python 正規表達式教學:看懂 re.split()、W|_ 與 flags=re.ASCII # w代表 word character ~ [A-Za-z0-9_] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2026/04/20260430095059_0_7f3a4f.png)
這表示 \w 的定義會因 re.ASCII 改變。
寫法二:直接抓中文範圍
print(re.findall(r'[\u4e00-\u9fff]+', text))![Python 正規表達式教學:看懂 re.split()、W|_ 與 flags=re.ASCII # w代表 word character ~ [A-Za-z0-9_] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2026/04/20260430095214_0_a92c56.png)
這不依賴 re.ASCII,因為你已經明確寫死要抓哪段 Unicode 區間。
三十八、那到底該用哪一種?
可以用這個原則判斷。
如果你想處理的是:
- token 邊界
- 英文命名切詞
_、-、空白這類分隔符\w/\W的 ASCII 行為
那通常優先考慮:
re.split()\W|_flags=re.ASCII
如果你想處理的是:
- 是否含中文
- 抽取中文片段
- 只允許特定語系字元
- 明確限制字元集合
那 Unicode 範圍就比較合適。
三十九、實務建議:先選「語意最清楚」的寫法
這很重要。
不要因為 Unicode 範圍「看起來很強」就優先使用它。
很多時候,真正好的寫法不是最炫,而是 最能表達意圖。
例如:
你只是想把 _ - 空白 切開
那就寫:
re.split(r'[_\-\s]+', text)你想把非 word char 和 _ 都視為分隔符
那就寫:
re.split(r'\W|_', text, flags=re.ASCII)你真的想抓中文
那才寫:
re.findall(r'[\u4e00-\u9fff]+', text)四十、把 Unicode 這段和前文串起來理解
現在可以把前面的觀念整合成三層:
第一層:工具
re.split()
re.findall()
re.search()
re.sub()第二層:規則
\W|_
[_\-\s]+
[\u4e00-\u9fff]+第三層:匹配模式
flags=re.ASCII這樣你就比較不會把它們混在一起。
四十一、這一段最值得記住的重點
1.
Unicode 範圍是直接指定字元區間,不是 shorthand 類別。
2.
它通常比 re.ASCII 更精準,但也更難記、更難維護。
3.
如果只是做一般英文 token split,通常沒必要一開始就使用 Unicode 範圍。
4.
只有在你真的要控制「某一類 Unicode 字元」時,Unicode 範圍才特別有價值。
四十二、補充結論
如果要用一句話總結這段 Unicode 教學,可以這樣說:
re.ASCII是在改變\w/\W這類 shorthand 的判定方式;
Unicode 範圍則是直接指定你要匹配哪些字元。前者比較好懂,後者比較精準,但通常也更難記、更難用。
推薦hahow線上學習python: https://igrape.net/30afN
這裡的 ASCII 規則,意思是:
在判斷
\w、\W、\d、\s、\b這類 regex shorthand 時,
只用 ASCII 字元集合來判定,不去採用較寬鬆的 Unicode 字元分類。
四十三、什麼叫做 ASCII 規則?
前面說 flags=re.ASCII 會讓某些 regex shorthand 按照 ASCII 規則 判定,這裡的 ASCII 規則,可以先理解成:
只把 ASCII 範圍內的字元當成判斷依據
ASCII 是一套比較早期、範圍比較小的字元編碼集合,常見可理解為:
- 英文大小寫字母:
A-Z、a-z - 數字:
0-9 - 常見符號
- 空白字元的一部分
重點是:
它不包含中文、日文、韓文、emoji 這些 Unicode 字元
所以當 regex 使用 re.ASCII 時,某些 shorthand 就不會把這些非 ASCII 字元算進去。
四十四、在 regex 裡,ASCII 規則最常影響哪些 shorthand?
最常見的是這幾個:
\w\W\d\D\s\S\b\B
其中在文章脈絡裡,最重要的是:
\w\W\b
四十五、\\w 在 ASCII 規則下代表什麼?
如果加上:
flags=re.ASCII那麼:\w
就大致等於:
[A-Za-z0-9_]也就是只把下面這些當作 word character:
- 英文字母
- 數字
- 底線
_
所以:
A是\w7是\w_是\w中不是\wあ不是\wé在這個規則下也不算\w
四十六、\\W 在 ASCII 規則下代表什麼?
\W 就是 \w 的相反。
如果 ASCII 模式下:
\w == [A-Za-z0-9_]那麼:\W
就可以理解成:
[^A-Za-z0-9_]所以:
-是\W- 空白是
\W 中是\W@是\W
但要注意:
_不是\W- 因為
_屬於\w
這也是為什麼常常會看到:
\W|_因為單靠 \W 抓不到 _。
四十七、ASCII 規則和 Unicode 規則最大的差別是什麼?
最大差別在於:
非英文字符要不要被算進 shorthand 類別
例如字串:
text = "ABC中文_123"不加 re.ASCII
re.findall(r'\w+', text)
# 輸出: ['ABC中文_123']因為在 Unicode 規則下,中文可能被當作 \w。
加上 re.ASCII
re.findall(r'\w+', text , flags=re.ASCII)![Python 正規表達式教學:看懂 re.split()、W|_ 與 flags=re.ASCII # w代表 word character ~ [A-Za-z0-9_] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2026/04/20260430100605_0_0cfd1b.png)
因為此時 \w 只看 ASCII:
ABC是\w- 中文不是
\w _123是\w
四十八、所以 ASCII 規則不是「只允許 ASCII 字元」嗎?
不是。
這點很重要。
flags=re.ASCII 的意思不是:
整個 regex 只能處理 ASCII 字元
而是:
某些 shorthand 類別,在判定時只採用 ASCII 標準
所以你依然可以寫:
re.search(r'中文', text, flags=re.ASCII)這樣還是能匹配中文。
也就是說:
re.ASCII不會禁止中文出現在字串中- 它只是影響
\w、\W、\b這些縮寫類別的判定方式
四十九、那 \\b 為什麼也會受影響?
因為:\b
代表的是 word boundary,也就是「word character 和 non-word character 的邊界」。
既然 \b 的判定本來就依賴:
- 這個字是不是
\w - 那個字是不是
\W
那麼一旦 \w/\W 的規則改成 ASCII,\b 的結果也會跟著改變。
也就是說:
\b 不是獨立運作的,它依賴 \w 的定義
五十、可以把 ASCII 規則想成什麼?
你可以把它想成:
把 regex 的 shorthand 判定標準,縮回到英文、數字、底線這個較傳統的世界
這個理解方式很適合初學者。
因為很多時候你其實不是要處理全球文字系統,而只是想處理:
- 英文命名
- 程式識別字
- token split
- log / file name / slug
這時 ASCII 規則反而更符合直覺。
五十一、一個最簡短的理解版本
如果在文章裡用一句最短的話解釋,可以寫成:
所謂 ASCII 規則,就是讓
\w、\W、\b這類 shorthand 只依照 ASCII 字元集合來判定,例如\w幾乎可視為[A-Za-z0-9_],因此中文就不再被算進\w。
五十二、再用一個表格快速整理
![Python 正規表達式教學:看懂 re.split()、W|_ 與 flags=re.ASCII # w代表 word character ~ [A-Za-z0-9_] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2026/04/20260430100907_0_bfbeca.png)
因此,當我們說 flags=re.ASCII 會改變 \W|_ 的效果時,真正的意思其實是:\W 的判定標準變了。原本在 Unicode 規則下可能被視為 \w 的中文字元,在 ASCII 規則下會被改判成 \W,所以切割結果就會不同。
推薦hahow線上學習python: https://igrape.net/30afN
 #像操作 List 一樣操作文件; target_xml_node.addnext(p_new)")
![Python 如何用pandas.Series.nsmallest() 找到n個與target差距最小的index?再從中找到距離idxmax最近的index?避免誤抓sidelobes的index? targetIdx = (serMean-target_value).abs().nsmallest(n).index.tolist() ;Series切片: .loc[標籤名1:標籤名2] (會含標籤名2) ; .iloc[位置1:位置2] (不含位置2)](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2023/02/20230222082954_53.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python 如何用pandas.Series.nsmallest() 找到n個與target差距最小的index?再從中找到距離idxmax最近的index?避免誤抓sidelobes的index? targetIdx = (serMean-target_value).abs().nsmallest(n).index.tolist() ;Series切片: .loc[標籤名1:標籤名2] (會含標籤名2) ; .iloc[位置1:位置2] (不含位置2)")
 : from openai import OpenAI ; client = OpenAI (api_key = api_key) ; response = client .audio .speech .create( model= “tts-1-hd”, input= text_content, response_format= “mp3”)")
![Python: 如何創建多層column name的pandas.DataFrame? df = pd.read_csv (‘data.csv’, header=[0, 1], sep=”,”) ; col = pd .MultiIndex .from_arrays( aryCol )](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2023/03/20230314164119_32.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: 如何創建多層column name的pandas.DataFrame? df = pd.read_csv (‘data.csv’, header=[0, 1], sep=”,”) ; col = pd .MultiIndex .from_arrays( aryCol )")
![Python: matplotlib繪圖,如何限定座標軸範圍? plt.axis([xmin, xmax, ymin, ymax])](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2023/02/20230208101745_93.jpg?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: matplotlib繪圖,如何限定座標軸範圍? plt.axis([xmin, xmax, ymin, ymax])")
 增加新的一欄? model = tensorflow.keras.models.Sequential()")

 ; “”.join(ch for ch in normalized if not unicodedata.combining(ch))")
; ip addr ; hostname -I查詢ip address")


近期留言