在日常的自動化任務中,
我們經常需要處理 PDF 檔案。
有時候是為了產出報表,
有時候是為了將文件轉換成圖片,
方便傳遞給視覺語言模型(Vision LLM)進行分析。
這篇教學將帶你一氣呵成完成兩個動作:
- 用 Python 憑空建立一份包含兩頁的簡單 PDF。
- 讀取這份 PDF,並將每一頁分別存成高解析度的圖片(PNG)。
🛠 準備工作
我們只需要安裝 PyMuPDF 套件。
請在終端機(Terminal)輸入以下指令:
pip install pymupdf(註:雖然安裝時的套件名稱是 pymupdf,
但在 Python 程式碼中匯入時,我們要寫 import fitz)
步驟一:生成一份簡單的 PDF (兩頁以上)
其實 fitz 不只能讀取 PDF,它也能建立 PDF!
我們來寫一段小程式,
快速生成一份有兩頁內容的測試文件。
import fitz # 匯入 PyMuPDF
def create_sample_pdf(filename="sample.pdf"):
# 1. 建立一個空白的 PDF 文件物件
doc = fitz.open()
# 2. 新增第一頁,並寫入文字
page1 = doc.new_page()
page1.insert_text(
fitz.Point(50, 100), # 文字的 X, Y 座標
"這是第一頁 (Page 1)",
fontsize=24,
fontname="helv" # 使用內建字體 Helvetica
)
# 3. 新增第二頁,並寫入文字
page2 = doc.new_page()
page2.insert_text(
fitz.Point(50, 100),
"這是第二頁 (Page 2) - 準備轉成圖片!",
fontsize=24,
fontname="helv"
)
# 4. 儲存並關閉檔案
doc.save(filename)
doc.close()
print(f"✅ 成功建立 PDF 檔案:{filename}")
# 執行生成 PDF 的函數
create_sample_pdf()執行完這段程式碼後,
你的資料夾裡就會多出一個名為 sample.pdf 的檔案了。
步驟二:將 PDF 的每一頁轉為圖片
接下來,我們要讀取剛剛建立的 sample.pdf,
並利用迴圈把每一頁都轉成圖片。
這裡我們會用簡潔寫法 doc[i],
以及提高解析度的 fitz.Matrix。
import fitz
def pdf_to_images(pdf_path="sample.pdf"):
# 1. 打開剛剛建立的 PDF 檔案
doc = fitz.open(pdf_path)
# 2. 設定解析度放大倍率 (長寬各放大 2 倍,讓圖片更清晰)
zoom_x = 2.0
zoom_y = 2.0
mat = fitz.Matrix(zoom_x, zoom_y)
# 3. 使用迴圈遍歷 PDF 的每一頁
# len(doc) 會回傳這份 PDF 總共有幾頁
for i in range(len(doc)):
# 使用直覺的寫法獲取頁面 (等同於 doc.load_page(i))
page = doc[i]
# 將該頁面渲染成圖片 (Pixmap),並套用我們設定的放大矩陣
pix = page.get_pixmap(matrix=mat)
# 設定輸出的圖片檔名 (i 從 0 開始,所以檔名 +1 比較符合人類閱讀習慣)
output_filename = rf"output_page_{i + 1}.png"
# 儲存圖片
pix.save(output_filename)
print(f"🖼️ 已成功將第 {i + 1} 頁儲存為:{output_filename}")
# 4. 關閉文件釋放記憶體
doc.close()
# 執行轉換圖片的函數
pdf_to_images()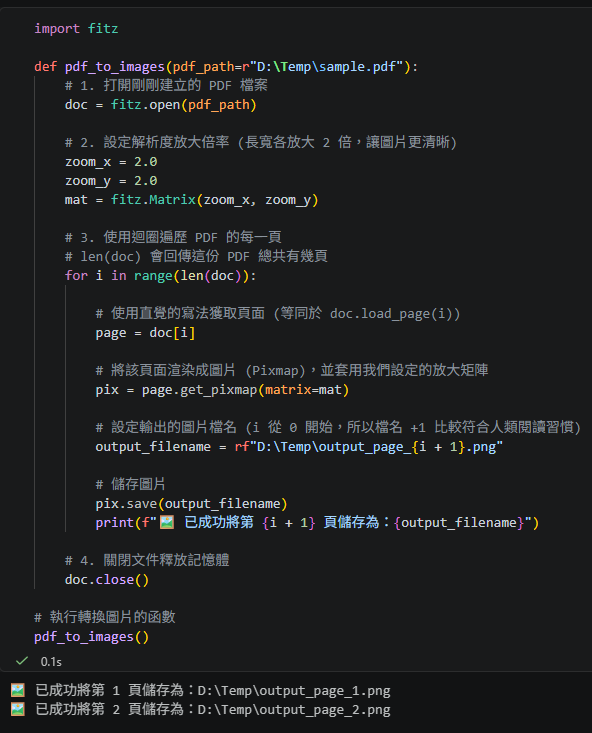
🎉 總結
只要短短幾行程式碼,
我們就完成了從無到有的 PDF 生成,
以及高畫質的圖片轉換。
doc.new_page():可以用來在 PDF 中新增空白頁面。doc[i]:是獲取特定頁面最優雅、簡潔的寫法。fitz.Matrix:是將 PDF 轉圖片時的秘密武器,
確保你的圖片丟給 LLM 辨識時,文字邊緣依然清晰銳利!
你可以把這兩段程式碼
放在同一個 Python 檔案裡連續執行,
馬上就能看到成果囉!
推薦hahow線上學習python: https://igrape.net/30afN
import fitz # PyMuPDF
import os
def create_sample_pdf(filename: str = "sample.pdf") -> None:
"""
建立一份包含兩頁的簡單 PDF 檔案。
:param filename: 輸出的 PDF 檔案名稱或路徑
"""
# 宣告 doc 為 fitz.Document 型別
doc: fitz.Document = fitz.open()
# 宣告 page1 為 fitz.Page 型別
page1: fitz.Page = doc.new_page()
page1.insert_text(
fitz.Point(50, 100),
"這是第一頁 (Page 1)",
fontsize=24,
fontname="helv"
)
# 宣告 page2 為 fitz.Page 型別
page2: fitz.Page = doc.new_page()
page2.insert_text(
fitz.Point(50, 100),
"這是第二頁 (Page 2) - 準備轉成圖片!",
fontsize=24,
fontname="helv"
)
doc.save(filename)
doc.close()
print(f"✅ 成功建立 PDF 檔案:{filename}")
def pdf_to_images(pdf_path: str = "sample.pdf", output_dir: str = r"D:\Temp") -> None:
"""
將 PDF 的每一頁轉換為高解析度圖片。
:param pdf_path: 來源 PDF 檔案的路徑
:param output_dir: 圖片輸出的目標資料夾路徑
"""
# 確保輸出資料夾存在,若無則建立
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 宣告 doc 為 fitz.Document 型別
doc: fitz.Document = fitz.open(pdf_path)
# 宣告放大倍率為浮點數 (float)
zoom_x: float = 2.0
zoom_y: float = 2.0
# 宣告 mat 為 fitz.Matrix 型別
mat: fitz.Matrix = fitz.Matrix(zoom_x, zoom_y)
# i 為整數 (int)
for i in range(len(doc)):
# 宣告 page 為 fitz.Page 型別
page: fitz.Page = doc[i]
# 宣告 pix 為 fitz.Pixmap 型別 (渲染出的圖片物件)
pix: fitz.Pixmap = page.get_pixmap(matrix=mat)
# 宣告 output_filename 為字串 (str)
# 這裡完美結合了 f-string (變數替換) 與 r-string (處理 Windows 路徑反斜線)
output_filename: str = fr"{output_dir}\output_page_{i + 1}.png"
pix.save(output_filename)
print(fr"🖼️ 已成功將第 {i + 1} 頁儲存為:{output_filename}")
doc.close()
if __name__ == "__main__":
# 宣告測試用的檔案名稱為字串
test_pdf_file: str = "sample.pdf"
# 執行生成 PDF
create_sample_pdf(filename=test_pdf_file)
# 執行 PDF 轉圖片,並指定輸出到 D:\Temp
pdf_to_images(pdf_path=test_pdf_file, output_dir=r"D:\Temp")💡 程式碼亮點說明:
-> None:明確標示這兩個函式不會回傳任何值(只執行動作)。fitz.Document,fitz.Page,fitz.Pixmap,fitz.Matrix:
這些是 PyMuPDF 中最核心的類別,
加上型別提示後,當您在編輯器中輸入page.或pix.時,
編輯器就能精準跳出它們專屬的方法(如get_pixmap或save)。fr"{output_dir}\...":fr前綴實際應用在路徑拼接上,
這樣不僅能安全處理 Windows 的反斜線\,
也能動態帶入變數,是非常實用且安全的寫法!
推薦hahow線上學習python: https://igrape.net/30afN
反轉 .sort()排序 .remove(“指定元素”)移除 .pop(index)移除, 字串.replace(old,new) .lower()小寫 .upper()大寫 .title()首字大寫")

![Python: 如何對 pandas.DataFrame 兩欄位運算後,增加到最後一欄? df[‘sum_AB’] = df.apply(sum_ab, axis=1) ; lambda函式](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2023/03/20230314200417_4.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: 如何對 pandas.DataFrame 兩欄位運算後,增加到最後一欄? df[‘sum_AB’] = df.apply(sum_ab, axis=1) ; lambda函式")


 ; df.set_index() 將兩欄的df,其中一欄設為index後,其型態是單欄的DataFrame還是Series?")
, dtype=float) ; print(data.shape); min0 = numpy.min(a,axis=0) ; min1 = numpy.min(a,axis=1) #2次沿軸1 ; numpy.average() ;array的軸向")
![Python 打造高容錯搜尋引擎:BM25、Bigram 與difflib自動糾錯實戰; from rank_bm25 import BM25Okapi ; bm25 = BM25Okapi(corpus_tokens) #corpus_tokens: list[list[str]]](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2026/02/20260209150527_0_a24c17.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python 打造高容錯搜尋引擎:BM25、Bigram 與difflib自動糾錯實戰; from rank_bm25 import BM25Okapi ; bm25 = BM25Okapi(corpus_tokens) #corpus_tokens: list[list[str]]")
 內聯修飾符 vs re.I 全域標記,打造無情的「激進截斷」割草機! `(?i)`、`flags=re.I`、`(?i:…)` 的差別")


近期留言