
folder = “C:\Python\P107\doc”
fname = “pima-indians-diabetes.csv”
import os
fpath = os.path.join(folder,fname)
#’C:\\Python\\P107\\doc\\pima-indians-diabetes.csv’
import pandas as pd
df = pd.read_csv(fpath,header=0)
#[768 rows x 9 columns] if hrader=0(預設值)
#[769 rows x 9 columns] if header=None
colList=df.columns.to_list()
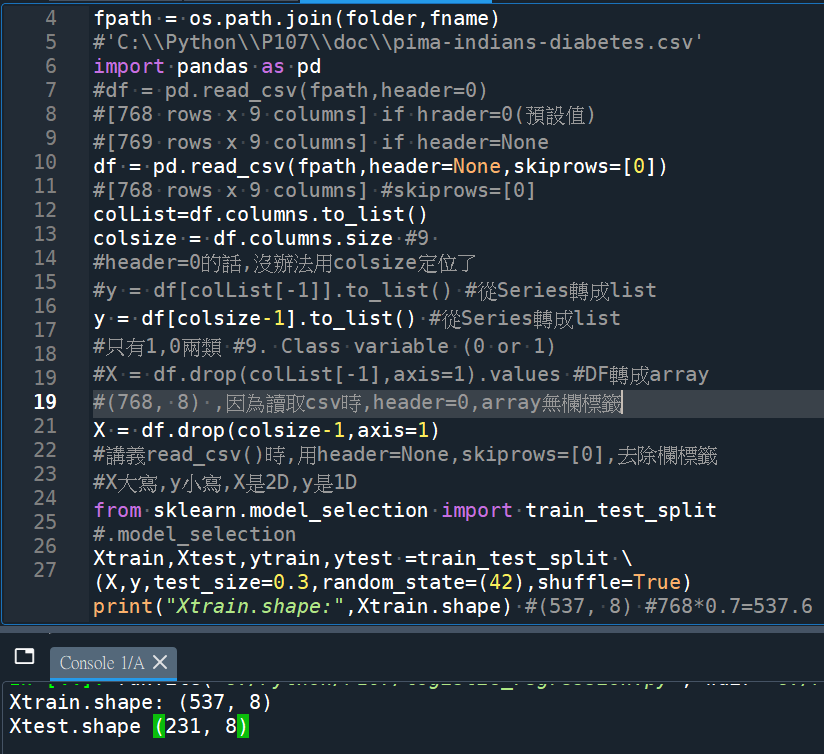
colsize = df.columns.size #9
#header=0的話,沒辦法用colsize定位了
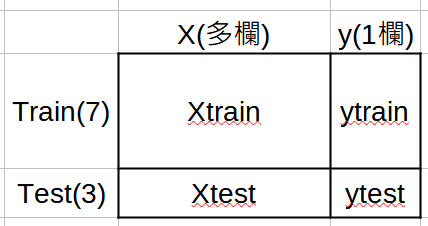
y = df[colList[-1]].to_list() #從Series轉成list
#只有1,0兩類 #9. Class variable (0 or 1)
X = df.drop(colList[-1],axis=1).values #DF轉成array
#(768, 8) ,因為讀取csv時,header=0,array無欄標籤
#講義read_csv()時,用header=None,skiprows=[0],去除欄標籤
# skiprows=[0] # =(0,) or =1 也可, =0無效
# [0]是list,刪除index 0的那一列,或tuple (0,)也可
# 1是整數,刪除從上方數來第一列
#X大寫,y小寫,X是2D,y是1D
from sklearn.model_selection import train_test_split
#.model_selection
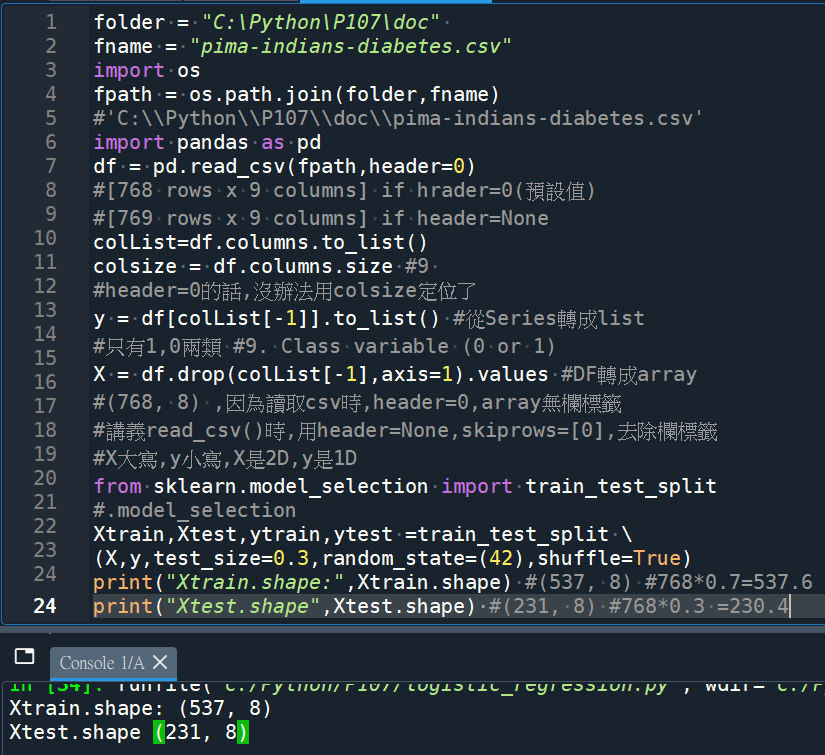
Xtrain,Xtest,ytrain,ytest =train_test_split \
(X,y,test_size=0.3,random_state=(42),shuffle=True)
print(“Xtrain.shape:”,Xtrain.shape) #(537, 8) #768*0.7=537.6
print(“Xtest.shape:”,Xtest.shape) #(231, 8) #768*0.3 =230.4
“””
Xtrain.shape: (537, 8)
Xtest.shape: (231, 8)
ytrain length: 537
ytest length: 231″””
#改用header=None, skiprows=[0]做
skiprows : Line numbers to skip while reading csv.
If it’s an int then skip that lines from top
If it’s a list of int then skip lines at those index positions
If it’s a callable function then pass each index to this function to check if line to skipped or not.
#因為使用了header=None,可以用colsize定位
推薦hahow線上學習python: https://igrape.net/30afN
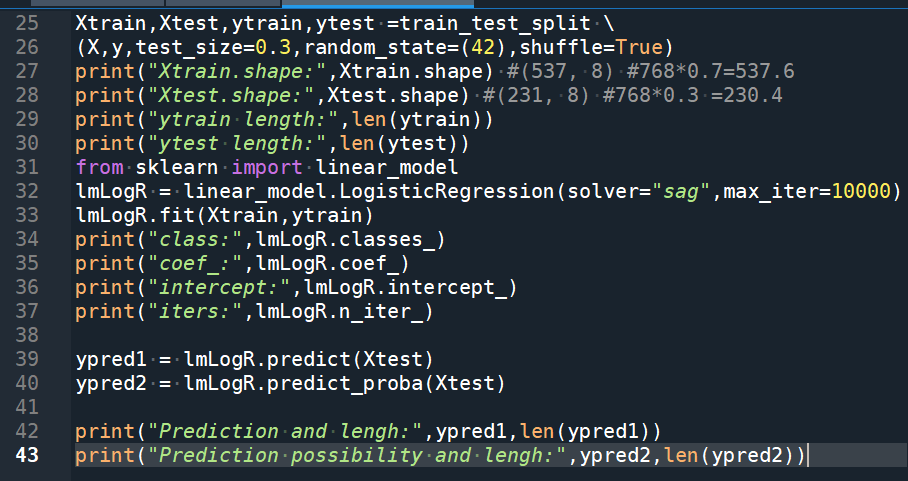
資料切割完畢後
print(“Xtrain.shape:”,Xtrain.shape) #(537, 8) #768*0.7=537.6
print(“Xtest.shape:”,Xtest.shape) #(231, 8) #768*0.3 =230.4
print(“ytrain length:”,len(ytrain))
print(“ytest length:”,len(ytest))
from sklearn import linear_model
lmLogR = linear_model.LogisticRegression(solver=”sag”,max_iter=10000)
lmLogR.fit(Xtrain,ytrain)
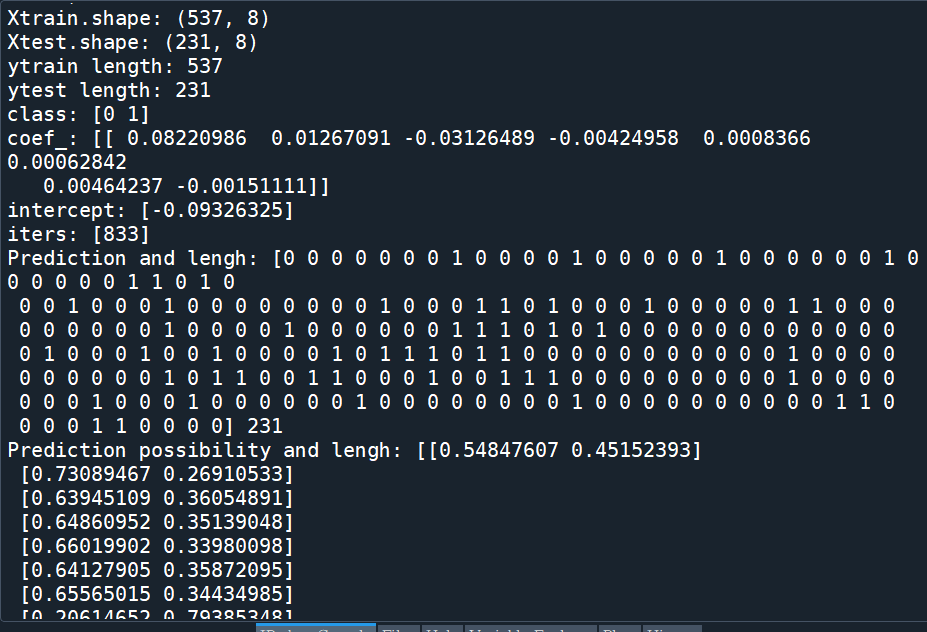
print(“class:”,lmLogR.classes_)
print(“coef_:”,lmLogR.coef_)
print(“intercept:”,lmLogR.intercept_)
print(“iters:”,lmLogR.n_iter_)
ypred1 = lmLogR.predict(Xtest)
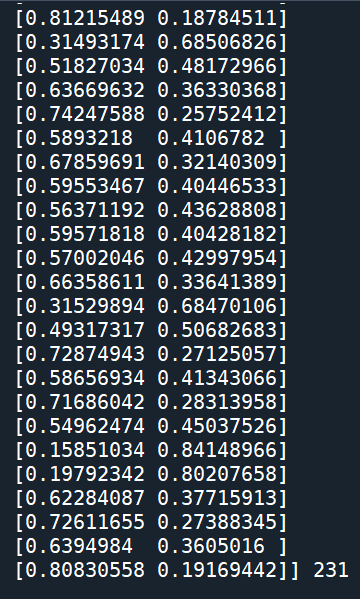
ypred2 = lmLogR.predict_proba(Xtest)
print(“Prediction and lengh:”,ypred1,len(ypred1))
print(“Prediction possibility and lengh:”,ypred2,len(ypred2))
輸出結果:
print(“class:”,lmLogR.classes_)
print(“coef_:”,lmLogR.coef_)
print(“intercept:”,lmLogR.intercept_)
print(“iters:”,lmLogR.n_iter_)

推薦hahow線上學習python: https://igrape.net/30afN
![「Python 的兩條路」:一次搞懂 sys.path (找 .py) 與 os.environ[‘PATH’] (找 .exe) 的愛恨情仇](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2026/01/20260114094100_0_424ead.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "「Python 的兩條路」:一次搞懂 sys.path (找 .py) 與 os.environ[‘PATH’] (找 .exe) 的愛恨情仇")

 和pandas.Series.dt.total_seconds() 進行時間數據處理")
")
 ; X_poly = poly.fit_transform(X)")

, x)` ; sorted(items, key=lambda x: (-len(x), x)) 與 json_repair strategy pipeline")



近期留言