#Python TQC考題909
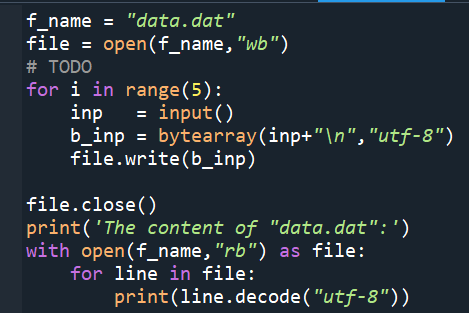
f_name = “data.dat”
file = open(f_name,”wb”)
# TODO
for i in range(5):
inp = input()
b_inp = bytearray(inp+”\n”,”utf-8″)
file.write(b_inp)
file.close()
print(‘The content of “data.dat”:’)
with open(f_name,”rb”) as file:
for line in file:
print(line.decode(“utf-8”))
“””
The content of “data.dat”:
“””
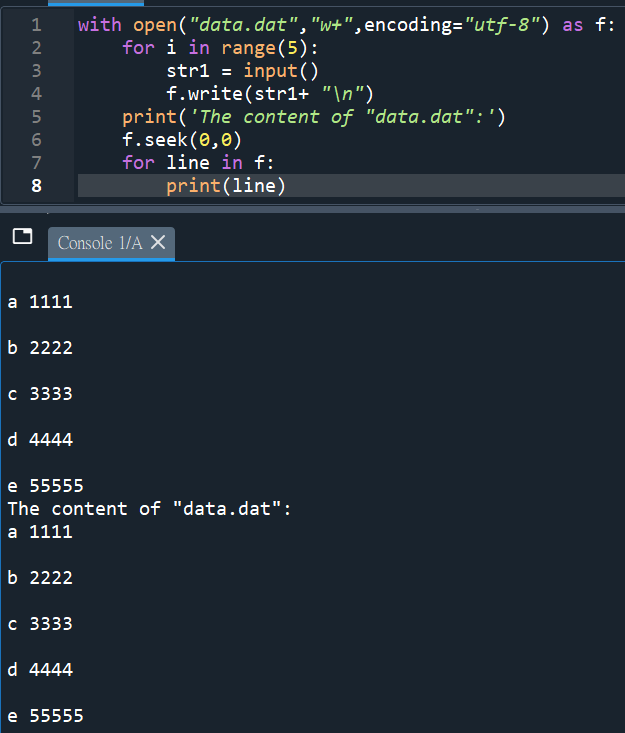
#只要加encoding=”utf-8″
#b模式都用不到,如: rb, wb
計算終值?")
 和pandas.Series.dt.total_seconds() 進行時間數據處理")

")

 or(|) xor(^) not")
與滾動條(Scrollbar)? canvas = tk.Canvas(root, width=400, height=300) ; scrollbar = tk.Scrollbar(root, command = canvas.yview) ; canvas.configure( yscrollcommand = scrollbar.set)")
 ; 如何處理unicode?")
 函數教學")

![Python常用的模組內建常數; __name__ ; __file__ ; __doc__ ; __all__ ;__dict__; vars()->Dict[str,str] ; dir()->List[str] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/11/20221112184006_50-520x245.png)

近期留言