# -*- coding: utf-8 -*-
import pandas as pd
s =pd.Series([“a”,”b”,”c”,”d”])
#s為pandas物件
#<class ‘pandas.core.series.Series’>
print(“Series:\n”,s)
print(“s.index:\n”,s.index,type(s.index)) #index結尾沒有s
print(“s.values:\n”,s.values,type(s.values)) #values結尾有s
#像字典的dic.keys() ; dic.values()
print(“list(index):\n”,list(s.index))
print(“list(values):\n”,list(s.values))
print(“取值:”,s[2])
print(“取值:\n”,s[[2,3]])
#有兩個[]
print(“dict(s):\n”,dict(s))
#pandas物件有index跟values,可以轉為dict
dic={“k1″:”v1″,”k2″:”v2”}
print(“字典轉為pandas物件\n”,pd.Series(dic))
#相對地,字典也可以轉為pandas物件
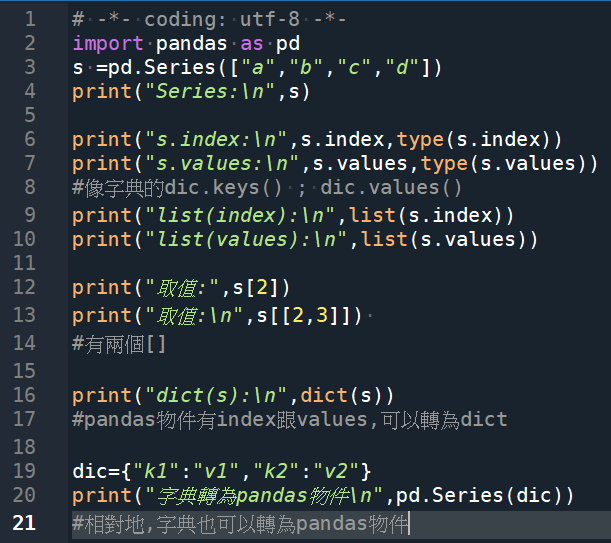
輸出結果:
pandas物件取值:
import pandas as pd
s =pd.Series([“a”,”b”,”c”,”d”])
print(“pandas物件:\n”,s)
print(“取值:”,s[1]) #b
print(“取值:\n”,s[1:999]) #b,c,d
print(“取值:\n”,s[1:]) #b,c,d
print(“取值:\n”,s[1:-1]) #b,c(沒有d)
print(“取值:\n”,s[1::2]) #b,d
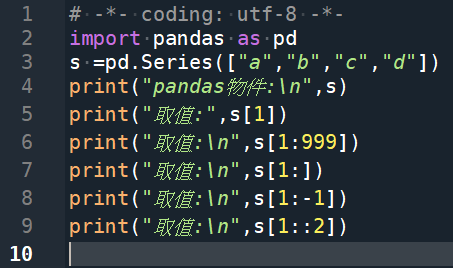
輸出:
推薦hahow線上學習python: https://igrape.net/30afN
如何一次讀出所有keys, values, items? dic.keys() ; set(dic) 無序; dic.values() ; dic.items()")
 套件繪製具有多個子圖的散佈圖且限定欄數?g = sns.relplot (data=tips, x=”total_bill”, y=”tip”, col=”day”, hue=”sex”,col_wrap=2, kind=”line”)")
 ; ax.xaxis.set_minor_locator(minor_locator)")
 方法說明,計算唯一值的數量,與 len( pandas.Series.unique() ) 同效果")

![Python: pandas.DataFrame 如何找出重複值並計算重複次數? counts = df[duplicates] .groupby([‘name’]) .size() .reset_index(name=’count’)](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2023/03/20230316131103_65.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: pandas.DataFrame 如何找出重複值並計算重複次數? counts = df[duplicates] .groupby([‘name’]) .size() .reset_index(name=’count’)")
 ; plt.vlines(x, ymin, ymax,color=”r”)")




近期留言