import pandas as pd
f1 = r”C:\Python\example\csvreader\skl_cashFlow.txt”
#f1每列長度不一樣
f2 = r”C:\Python\example\csvreader\skl_cashFlow.csv”
#f2每列長度一樣
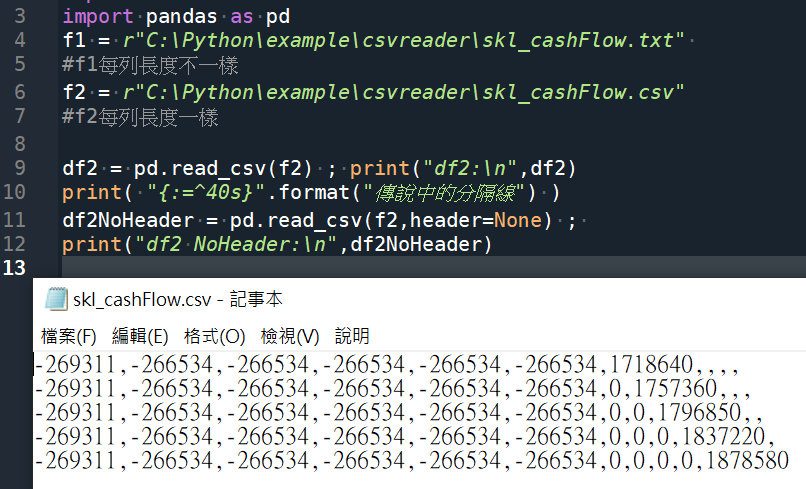
df2 = pd.read_csv(f2) ; print(“df2:\n”,df2)
#誤把第一列的資料當欄標籤
print( “{:=^40s}”.format(“傳說中的分隔線”) )
df2NoHeader = pd.read_csv(f2,header=None) ;
print(“df2 NoHeader:\n”,df2NoHeader)
#自動補0~10為欄標籤
輸出結果:
,但.5GHZ的.不split()? parts = filename.rsplit(“.”, 1) ; 使用正則表示法parts = re.split(r”\.(?!\d)”, filename) ; os.path.splitext(filename)")



.resolve().parent")
?如何使用jieba做中文斷詞? lis_jieba = jieba.lcut(strr)")
; BM25 (Best Matching 25) ; pip install rank-bm25 ; from rank_bm25 import BM25Okapi")




近期留言