from sklearn.tree import DecisionTreeClassifier

前篇使用了
K-近鄰演算法(K Nearest Neighbor ,簡稱 KNN)
本篇要改用決策樹分類
處理的資料: https://pse.is/3ty6rk
部分資料:
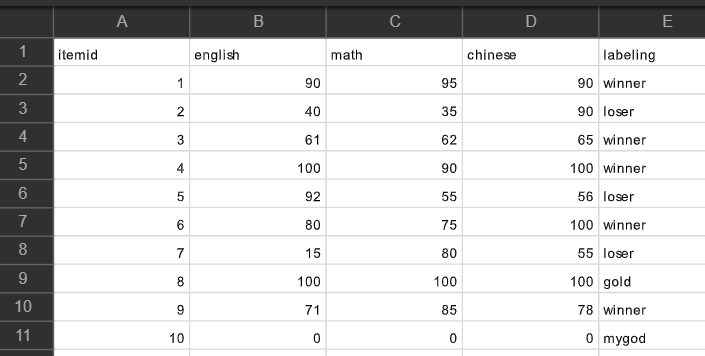
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
folder = “C:\Python\P107\doc”
fname = “student.csv”
import os
fpath = os.path.join(folder,fname)
# fpath = folder + “\\” + fname #同義
df = pd.read_csv(fpath,header=None,skiprows=[0])
df.to_excel(os.path.join(folder,”knsDF.xlsx”))
#df.index.size = 40 #df.columns.size = 5
X = df.drop([4],axis=1).values
y = df[4].values
Xtrain, Xtest, ytrain, ytest =\
train_test_split(X,y,test_size=0.25,
random_state= 42 ,shuffle =True)
XtestDF = pd.DataFrame(Xtest)
XtestDF.to_excel(os.path.join(folder,”knsXtest.xlsx”))
print(“Xtrain.shape:”,Xtrain.shape) #(30, 3)
print(“ytrain.shape:”,ytrain.shape) #(30,)
print(“Xtest.shape:”,Xtest.shape) #(10, 3)
print(“ytest.shape:”,ytest.shape) #(10,)
from sklearn.tree import DecisionTreeClassifier
for cri in [“gini”,”entropy”]:
tree = DecisionTreeClassifier(criterion = cri)
tree.fit(Xtrain,ytrain)
pred = tree.predict(Xtest)
pred2 = tree.predict_proba(Xtest)
print(“prediction:”,pred,”in case criterion”,cri )
print(“prediction proability:”,pred2,
“\nin case criterion”,cri )
howgood = tree.score(Xtest,ytest)
print(“Goodness:”,howgood,”in case ctrterion”,cri)
#前半部同KNN

後半部類似的語法,
主要改用 DecisionTreeClassifier
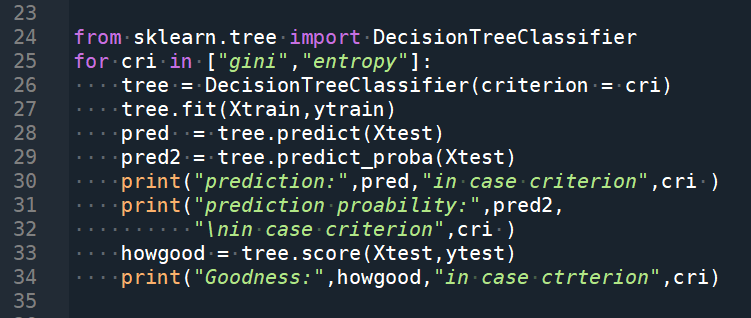
輸出結果:
就算有第0欄(index,非資料)干擾
決策樹的score仍比
匯出決策樹:

改寫後半段程式碼:
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_text
for cri in [“gini”,”entropy”]:
tree = DecisionTreeClassifier(criterion = cri)
tree.fit(Xtrain,ytrain)
r = export_text(tree,feature_names =
[“item”,”English”,”Math”,”Chinese”],
show_weights=True)
print(r)
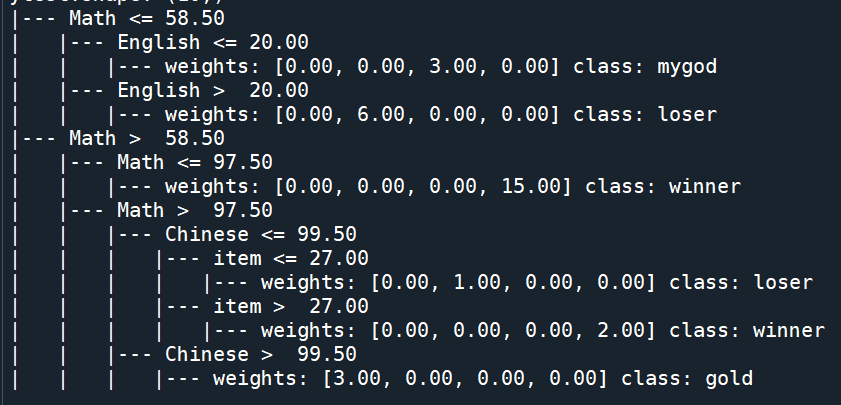
輸出結果:
criterion = “gini”
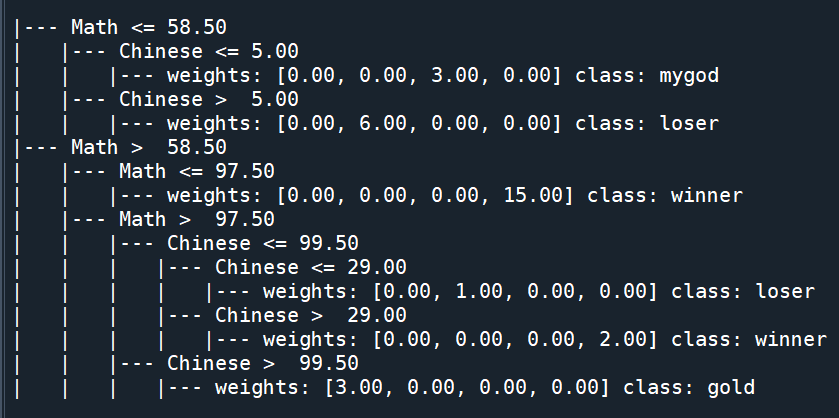
criterion = “entropy”
推薦hahow線上學習python: https://igrape.net/30afN
 # 更改整個檔名(basename,含副檔名); Path.with_stem(“新檔名”) # 更改檔名主體(stem),保留原副檔名 ; Path.with_suffix(“.新副檔名”) # 更改副檔名(只影響最後一個 suffix)")


 ; cc.convert(“不仅内存不够,而且服务器挂了”)")

 跟 ax.annotate() 有何差別? ax.annotate(f’max value={y_max:.2f}’, xy=(x_max, y_max), xytext=(x_max-0.5, y_max-0.5), fontsize=12, arrowprops=dict(arrowstyle=’->’, connectionstyle=’arc3′, color=’r’))")

 ; str.endswith() ; str.startswith()")
![Python 如何用pandas.Series.nsmallest() 找到n個與target差距最小的index?再從中找到距離idxmax最近的index?避免誤抓sidelobes的index? targetIdx = (serMean-target_value).abs().nsmallest(n).index.tolist() ;Series切片: .loc[標籤名1:標籤名2] (會含標籤名2) ; .iloc[位置1:位置2] (不含位置2)](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2023/02/20230222082954_53.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python 如何用pandas.Series.nsmallest() 找到n個與target差距最小的index?再從中找到距離idxmax最近的index?避免誤抓sidelobes的index? targetIdx = (serMean-target_value).abs().nsmallest(n).index.tolist() ;Series切片: .loc[標籤名1:標籤名2] (會含標籤名2) ; .iloc[位置1:位置2] (不含位置2)")
![Python: 如何用numpy.ndarray的reshape 將3D array轉為2D array,再轉為pandas.DataFrame? arr.reshape( arr.shape[0] * arr.shape[1] , -1) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/03/20230320082325_85-297x245.png)


近期留言