hex(ord("\0"))輸出為0x0
而非0x00
在Python中,\0 表示一个空字符,
它的ASCII值是0。所以,ord("\0") 的结果是0。hex() 函数会将数字转换为十六进制字符串,
但默认情况下会省略前导零。
如果你需要得到一个固定长度的十六进制字符串,
例如 “0x00″,可以使用以下方法:
value = ord("\0")
hex_string = f'0x{value:02x}'
# f'0x{value:02x}'
print(hex_string)輸出結果:

这里使用了 f-string 来格式化字符串,确保结果是两位十六进制数字,即使值小于16也会有前导零。这将输出 “0x00″,符合你的要求。
对于 f-string 中的 {value:02x},它实际上有两个部分:
value是要格式化的变量名。:02x是格式化说明符(format specifier)。
这个格式说明符的含义如下:
02:表示输出的最小宽度为2个字符。如果不足2个字符,将在前面补充0以满足最小宽度。x:表示以十六进制表示法输出。
因此,f'{value:02x}' 的含义是将 value 格式化为一个最小宽度为2个字符的十六进制字符串,并在前面补充0以填满2个字符的宽度。这确保了输出的字符串始终是两位十六进制数字,并且在需要时包含前导零。在这种情况下,ord("\0") 的值为0,所以 f'{ord("\0"):02x}' 的结果是 “00”。
这种格式化方法对于确保输出的固定宽度和格式非常有用,特别是在需要与其他系统或协议交互时,以确保数据的一致性和正确性。
f'0x{value:02x}' 这种格式化方法相对于使用 hex() 函数可以更精确地控制输出的格式和宽度,使得结果更整齐和符合特定的需求。使用 f-string 格式化字符串允许你以更灵活的方式定义输出的外观,包括前导零、前缀等等。
这种方法特别适用于需要与其他系统或协议进行数据交互时,因为你可以根据目标系统或协议的要求精确地定义输出的格式,确保数据的一致性和正确性。
若使用input(),
\0 會被視為raw string
拆分為\ 0 兩個character(\ 和 0)
若要將\0當成一個轉譯字元:strr = strr.replace(r"\0", "\0")
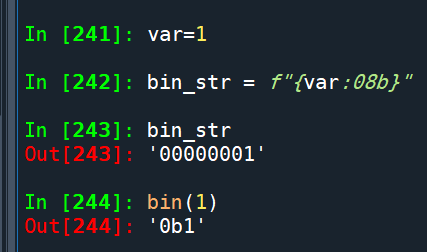
bin跟hex一樣都會省略前導0
可以用 :08b 的格式:
推薦hahow線上學習python: https://igrape.net/30afN


: from pathlib import Path; Path.exists() ; Path.is_dir() ; Path.glob(“*.docx”) ; Path.is_file()")
 ; .localtime() ; .tm_year ; .tm_mon ; .tm_mday ; .ctime() #current time ; .sleep() ;time.asctime() #as string ; time.strftime() #string format time")
")
.reset_index(drop=True) ; df_drop1.columns = list(range(df_drop1.columns.size))")
 如何略過首n列,末m列? df_footer = pd.read_csv(‘test.txt’, skiprows=1, skipfooter=1, engine=’python’) #”Footer” 可以翻譯為 “頁腳”,通常指網頁底部的區域,包含版權聲明、聯絡資訊、隱私政策等相關資訊。")

轉成 AST (Abstract Syntax Tree , 抽象語法樹)並匯出成 JSON; markdown = mistune.create_markdown( renderer=’ast’ )")


近期留言