原始資料如下:
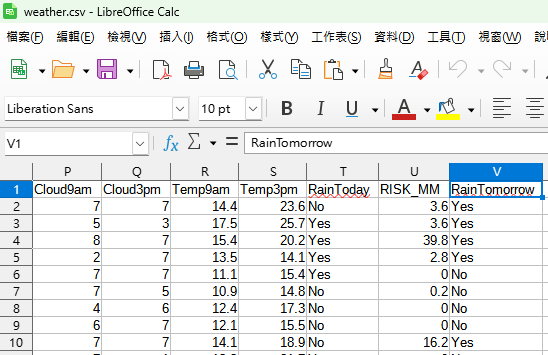
原始資料的
最後一欄為RainTomorrow
如何再新增一欄
將該欄位的
Yes改為1
No改為0
code:
# -*- coding: utf-8 -*-
"""
Created on Sun Nov 12 15:27:56 2023
@author: SavingKing
"""
import os
import pandas as pd
dirname = r"C:\SavingKing\Downloads\day6\ch07-MLP-flower"
basename = "weather.csv"
fpath = os.path.join(dirname,basename)
#'C:\\Users\\SavingKing\\Downloads\\day6\\ch07-MLP-flower\\weather.csv'
df = pd.read_csv(fpath)
func = lambda strr: 1 if strr == "Yes" else 0
df["RainTomorrow_01"] = df["RainTomorrow"].apply( func )輸出結果:
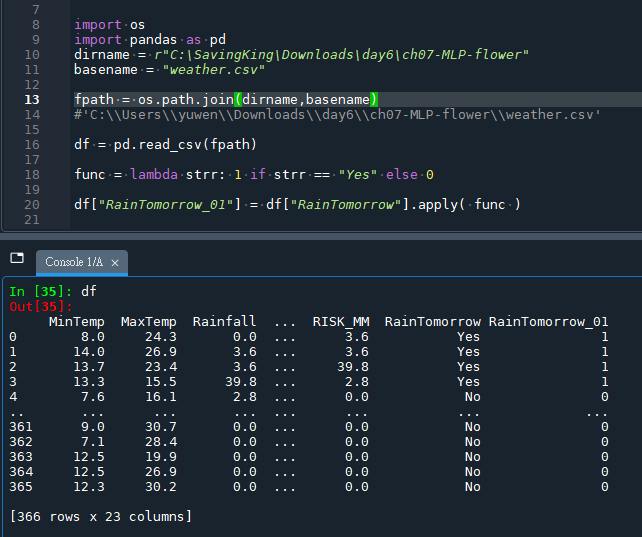
df多了一欄 RainTomorrow_01
推薦hahow線上學習python: https://igrape.net/30afN
weather.csv 的部分內容:
| MinTemp | MaxTemp | Rainfall | Evaporation | Sunshine | WindGustDir | WindGustSpeed | WindDir9am | WindDir3pm | WindSpeed9am | WindSpeed3pm | Humidity9am | Humidity3pm | Pressure9am | Pressure3pm | Cloud9am | Cloud3pm | Temp9am | Temp3pm | RainToday | RISK_MM | RainTomorrow |
| 8 | 24.3 | 0 | 3.4 | 6.3 | NW | 30 | SW | NW | 6 | 20 | 68 | 29 | 1019.7 | 1015 | 7 | 7 | 14.4 | 23.6 | No | 3.6 | Yes |
| 14 | 26.9 | 3.6 | 4.4 | 9.7 | ENE | 39 | E | W | 4 | 17 | 80 | 36 | 1012.4 | 1008.4 | 5 | 3 | 17.5 | 25.7 | Yes | 3.6 | Yes |
| 13.7 | 23.4 | 3.6 | 5.8 | 3.3 | NW | 85 | N | NNE | 6 | 6 | 82 | 69 | 1009.5 | 1007.2 | 8 | 7 | 15.4 | 20.2 | Yes | 39.8 | Yes |
| 13.3 | 15.5 | 39.8 | 7.2 | 9.1 | NW | 54 | WNW | W | 30 | 24 | 62 | 56 | 1005.5 | 1007 | 2 | 7 | 13.5 | 14.1 | Yes | 2.8 | Yes |
| 7.6 | 16.1 | 2.8 | 5.6 | 10.6 | SSE | 50 | SSE | ESE | 20 | 28 | 68 | 49 | 1018.3 | 1018.5 | 7 | 7 | 11.1 | 15.4 | Yes | 0 | No |
| 6.2 | 16.9 | 0 | 5.8 | 8.2 | SE | 44 | SE | E | 20 | 24 | 70 | 57 | 1023.8 | 1021.7 | 7 | 5 | 10.9 | 14.8 | No | 0.2 | No |
| 6.1 | 18.2 | 0.2 | 4.2 | 8.4 | SE | 43 | SE | ESE | 19 | 26 | 63 | 47 | 1024.6 | 1022.2 | 4 | 6 | 12.4 | 17.3 | No | 0 | No |
| 8.3 | 17 | 0 | 5.6 | 4.6 | E | 41 | SE | E | 11 | 24 | 65 | 57 | 1026.2 | 1024.2 | 6 | 7 | 12.1 | 15.5 | No | 0 | No |
| 8.8 | 19.5 | 0 | 4 | 4.1 | S | 48 | E | ENE | 19 | 17 | 70 | 48 | 1026.1 | 1022.7 | 7 | 7 | 14.1 | 18.9 | No | 16.2 | Yes |
tensorflow.keras
code:
# -*- coding: utf-8 -*-
"""
Created on Sun Nov 12 15:27:56 2023
@author: SavingKing
"""
import os
import pandas as pd
import numpy as np
dirname = r"P:\Python class\powen\AI人工智慧自然語言與語音語意辨識開發應用實務班\powen2_AI人工智慧自然語言與語音語意辨識開發應用實務班\day6\ch07-MLP-flower"
basename = "weather.csv"
fpath = os.path.join(dirname,basename)
#'C:\\Users\\SavingKing\\Downloads\\day6\\ch07-MLP-flower\\weather.csv'
df = pd.read_csv(fpath)
func = lambda strr: 1 if strr == "Yes" else 0
df["RainTomorrow_01"] = df["RainTomorrow"].apply( func )
lis_drop_col = ["WindGustDir", "WindDir9am","WindDir3pm","RainToday","RainTomorrow"]
#非數值資料的欄位先drop,只留下數值資料的欄位
#WindSpeed9am 資料含有NA
df_dp = df.drop(columns = lis_drop_col)
#[366 rows x 18 columns]
df_dp.dropna(axis=0, how='any', subset=None, inplace=True)
#[354 rows x 18 columns]
#資料中含有NA,需要先dropna做資料清洗,不然loss, predict會出現nan
df_dp.dropna(axis=0, how='any', subset=None, inplace=True)
#[354 rows x 18 columns]
X = df_dp.drop(columns="RainTomorrow_01").values
#[366 rows x 17 columns]
Y = df_dp.iloc[:,-1].values
#pandas.core.series.Series
"""
X.shape
Out[61]: (366, 17)
Y.shape
Out[62]: (366,)
"""
from sklearn.model_selection import train_test_split
import tensorflow as tf
category=2 #下雨/不下雨 分別用1 0 代表, 兩種結果
dim=X.shape[1] #有幾個特徵值?
x_train , x_test , y_train , y_test = train_test_split(X,Y,test_size=0.05)
y_train2=tf.keras.utils.to_categorical(y_train, num_classes=(category))
y_test2=tf.keras.utils.to_categorical(y_test, num_classes=(category))
#One-hot Encoding 單熱編碼
#y_train y_test 都是一維的資料
print("x_train[:4]",x_train[:4])
print("y_train[:4]",y_train[:4])
print("y_train2[:4]",y_train2[:4])
# 建立模型
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Dense(units=200,
activation=tf.nn.relu,
input_dim=dim)) #input_dim 有幾個特徵值不能錯
model.add(tf.keras.layers.Dense(units=200,
activation=tf.nn.relu ))
model.add(tf.keras.layers.Dense(units=200,
activation=tf.nn.relu ))
model.add(tf.keras.layers.Dense(units=200,
activation=tf.nn.relu ))
model.add(tf.keras.layers.Dense(units=category,
activation=tf.nn.softmax )) #最後一層units=category也不能錯
model.compile(optimizer='adam',
loss=tf.keras.losses.categorical_crossentropy,
metrics=['accuracy'])
model.fit(x_train, y_train2,
epochs=1000,
batch_size=64)
#測試
model.summary()
score = model.evaluate(x_test, y_test2)
print("score:",score)
predict = model.predict(x_test)
print("predict:",predict)
lis_ans = [np.argmax(predict[i]) for i in range(predict.shape[0]) ]
print("Ans:\t",lis_ans)
# print("Ans:",np.argmax(predict[0]),np.argmax(predict[1]),np.argmax(predict[2]),np.argmax(predict[3]))
# =============================================================================
# predict2 = model.predict_classes(x_test)
# print("predict_classes:",predict2)
# print("y_test",y_test[:])
# =============================================================================輸出結果:
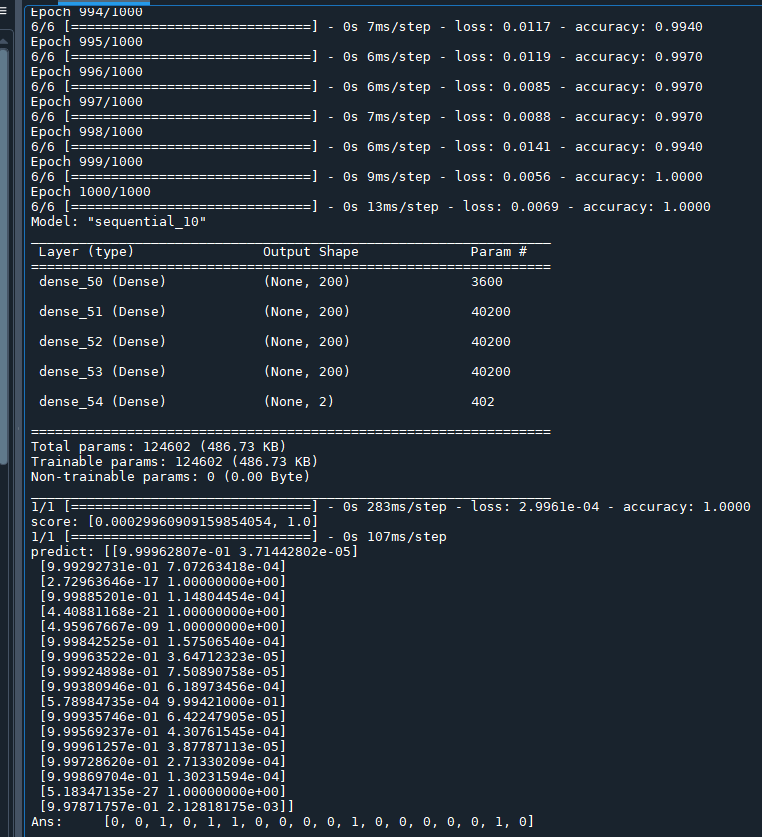
若在輸出結果中看到
loss, predict會出現nan
應該有所警覺,
這是不尋常的現象
检查数据:
- 确保输入数据(
X)中没有NaN或无限大(Infinity)值。 - 检查数据的范围和分布。有时,数据标准化(例如,使用
StandardScaler)可以帮助避免数值不稳定。
在处理多类别分类问题时,最后一层最推荐使用Softmax激活函数。这是因为Softmax可以将输出转换为一个概率分布,每个类别的输出值在0和1之间,并且所有输出值加起来等于1。这样,每个输出可以被解释为模型对于每个可能类别的预测概率。
对于二分类问题,虽然也可以使用Softmax,但通常只需一个输出节点,并使用Sigmoid激活函数。Sigmoid函数将单个输出压缩到0和1之间,可以直接解释为事件发生的概率。
要点如下:
- 多类分类:使用Softmax,每个类别一个输出节点。
- 二分类:使用Sigmoid,一个输出节点即可。
对于二分类问题,理论上可以使用Softmax激活函数,尽管它更常见于多分类问题。对于二分类,Softmax将会输出两个值,分别代表属于第一类和第二类的概率,这两个值加起来总和为1。在二分类情况下,Softmax实际上和使用单个Sigmoid激活函数的效果是等价的,因为Sigmoid函数输出的是一个概率值,表示为正类的概率,而1减去这个值则表示为负类的概率。
使用Sigmoid还是Softmax?
- Sigmoid:在二分类问题中,你通常会看到使用Sigmoid函数,因为它输出一个单一的概率值,模型的输出可以直接解释为一个类别的概率,另一个类别的概率是1减去这个概率值。
- Softmax:即使是在二分类问题中,使用Softmax也是可行的。它会提供两个输出值,一个为正类的概率,另一个为负类的概率,这两个概率相加等于1。
在实际操作中,无论是使用Softmax还是Sigmoid,通常都会根据模型的输出选择合适的阈值来确定最终的类别。例如,如果正类的概率大于0.5(或另一个选定的阈值),则预测为正类,否则预测为负类。
为什么二分类问题中还是可以使用Softmax?
在一些深度学习框架中,出于实现的便利性或者为了保持模型架构的一致性,即使在二分类问题中也可以使用Softmax。特别是当你有可能将二分类问题扩展到多分类问题时,使用Softmax可以使得模型的输出层在不同配置间更容易切换。此外,在某些框架中,针对二分类问题的交叉熵损失函数实际上在内部计算时会使用与Softmax相似的数学公式。
推薦hahow線上學習python: https://igrape.net/30afN
model.summary()
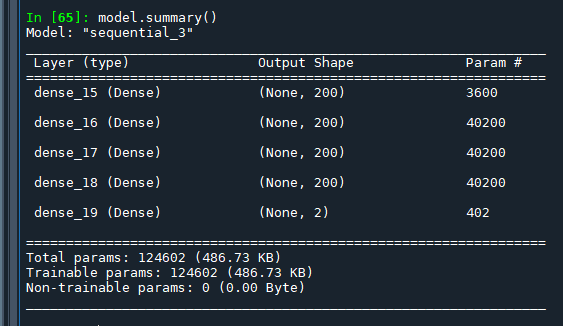
model.compile和model.fit是TensorFlow中Keras API的两个关键步骤,它们在神经网络的训练过程中扮演不同但互补的角色。
model.compile
model.compile是用来配置训练模型的过程的。在这一步,你定义了三个重要的元素:
- 优化器(Optimizer):
- 决定了模型如何更新权重以及学习速率。常见的优化器包括SGD、Adam、RMSprop等。
- 损失函数(Loss function):
- 用于量化模型输出与目标值之间的差异。例如,用于回归问题的损失函数可能是均方误差(MSE),而用于分类问题的损失函数可能是交叉熵(Crossentropy)。
- 评估指标(Metrics):
- 用于监视训练和测试过程。常见的指标包括准确度(accuracy)、召回率(recall)、精确度(precision)等。
model.fit
model.fit是用来训练模型的步骤。在这个阶段,模型开始学习数据,不断调整权重以最小化model.compile中定义的损失函数。model.fit需要以下几个参数:
- 输入数据(Input data):
- 用于训练模型的特征数据。
- 目标数据(Target data):
- 训练数据对应的标签或目标。
- 批次大小(Batch size):
- 指定在更新模型之前要处理的数据的数量。较小的批量可以提高训练过程的泛化能力,但可能会增加训练时间。
- 迭代次数(Epochs):
- 完整数据集的遍历次数。一个epoch意味着每个样本在训练过程中被使用了一次。
- 验证数据(Validation data)或分割比例(Validation split)(可选):
- 用于在训练过程中评估模型性能的数据。这不会用于训练,仅用于评估。
区别
- 作用:
model.compile用于配置训练模型的方式,而model.fit用于实际训练模型。 - 时间点:首先执行
model.compile来定义训练过程的参数,然后执行model.fit来开始训练过程。
简而言之,model.compile是设置训练模型的“规则”,而model.fit是根据这些“规则”进行训练的过程。
在机器学习和深度学习的上下文中,“Sparse”通常翻译为“稀疏”。在这种情况下,“稀疏”指的是大多数元素为零或不需要表示的情况。例如,稀疏矩阵中的大部分元素都是零。相对地,“稠密”(Dense)则意味着大多数的元素都是非零的。
在sparse_categorical_crossentropy中,“稀疏”表明标签是以稀疏格式给出的,即直接用类别的索引来表示,而不是用One-hot 编码的方式(其中One-hot 编码的向量在除了一个位置为1外,其他位置都为0,更“稠密”)。所以,当你的分类标签是简单的整数列表(例如,[0, 2, 1, …]),而不是One-hot 编码的形式时,就会使用“稀疏分类交叉熵”作为损失函数。
label若使用one hot encoding
損失函數則需使用
tensorflow.keras.losses.categorical_crossentropy
推薦hahow線上學習python: https://igrape.net/30afN
新版本的
predict2 = model.predict_classes(x_test)
要改成
predict2 = model.predict(x_test)
predict2=np.argmax(predict2,axis=1)
#每row取出最大值的index
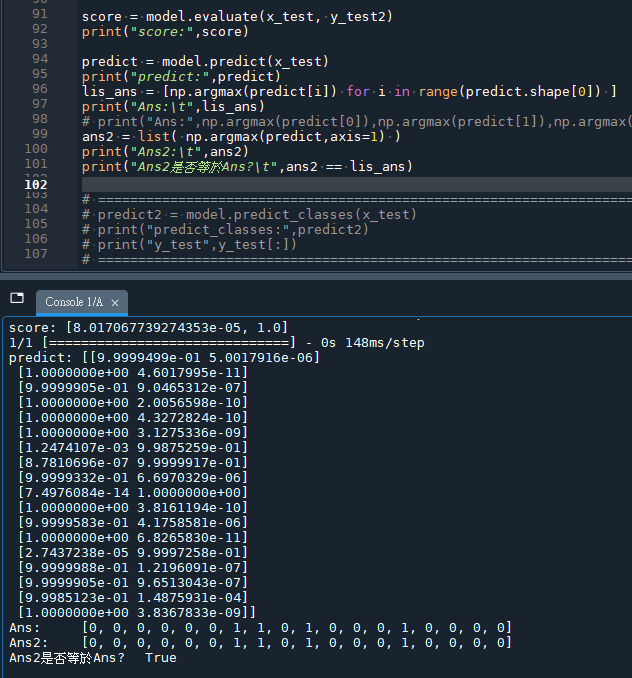
lis_ans:
predict = model.predict(x_test)
lis_ans = [np.argmax(predict[i]) for i in range(predict.shape[0]) ]对predict数组进行迭代,其中predict是模型对x_test的预测。predict[i]给出了第i个测试样本的所有类别的预测概率。
当您使用np.argmax(predict[i])时,由于predict[i]本身是一维的,所以不需要指定axis参数;它默认就会在这个一维数组上操作。这段代码遍历每个样本的预测概率数组,并找出概率最高的类别索引。
而如果您直接在predict二维数组上使用np.argmax,您应该指定axis=1来沿着列(每个样本的所有类别的预测概率)查找最大值的索引。这样,您可以用一行代码替代整个for循环:
predict2 = np.argmax(predict, axis=1)这里axis=1的含义是您要沿着横轴(每列)查找最大值的索引。这将返回每个样本预测概率最高的类别索引的一维数组,与您使用for循环得到的lis_ans数组相同。
推薦hahow線上學習python: https://igrape.net/30afN
垂直位置教學: rank=’sink’ ; rank=’source’ ; rank=’same’ ; 為子圖的屬性,在node中設定無效 ; 不可與g.attr(newrank=’true’) #子圖同高度 一起使用; with g.subgraph() as s: s.attr(rank=’sink’) # 設置子圖為sink ; s.node(‘Logo’, ‘Company Logo’)")
 同級的「完美縮排」; from lxml import etree ; root = etree.fromstring(xml_bytes) #等效 root = etree.fromstring( xml_str.encode(“utf-8”) ); clean_xml_str = etree.tostring(root, pretty_print=True, encoding=’unicode’, xml_declaration=False) ; import xml.etree.ElementTree as ET")

、ravel()與reshape(-1)的完整指南 #flatten(): 總是建立副本")
 切割資料(波士頓地區房價)為訓練資料跟測試資料; from sklearn.model_selection import train_test_split ; xtrain, xtest, ytrain, ytest = train_test_split(x, y, test_size=0.3, random_state=42, shuffle=True)")





近期留言