前置作業(安裝套件):
pip install SpeechRecognition
#請注意: pip install SpeechRecognition
但是在py code中是import speech_recognition
兩者並不一致
為什麽會有這種差異?
這種差異主要是因為PyPI上的包名(SpeechRecognition)和庫內部使用的模塊名(speech_recognition)可以不同。包名通常是為了易讀性和易記性而設計的,而模塊名則遵循Python的命名約定,通常是小寫字母且有時會包含下劃線以提高可讀性。
總結
使用pip install SpeechRecognition來安裝庫。
使用import speech_recognition as sr來在你的Python腳本中導入和使用這個庫。
這樣的命名方式雖然可能初看起來有點迷惑,但只要理解了包名和模塊名的使用場景和區別,就能夠順利地使用這些庫了。希望這能幫助您更好地理解和使用SpeechRecognition庫!
# -*- coding: utf-8 -*-
"""
Created on Thu Sep 5 09:59:00 2024
@author: SavingKing
"""
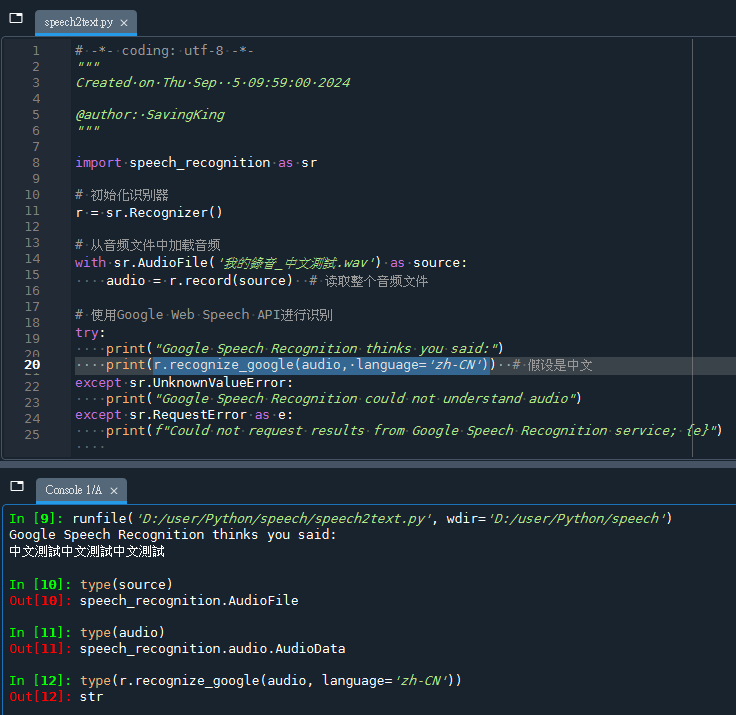
import speech_recognition as sr
# 初始化识别器
r = sr.Recognizer()
# 从音频文件中加载音频
with sr.AudioFile('我的錄音_中文測試.wav') as source:
audio = r.record(source) # 读取整个音频文件
# 使用Google Web Speech API进行识别
try:
print("Google Speech Recognition thinks you said:")
print(r.recognize_google(audio, language='zh-CN')) # 假设是中文
except sr.UnknownValueError:
print("Google Speech Recognition could not understand audio")
except sr.RequestError as e:
print(f"Could not request results from Google Speech Recognition service; {e}")
輸出結果:
在語音識別庫中,language=”zh-TW” 指的是使用台灣的中文,這通常是指繁體中文。而簡體中文通常是通過 language=”zh-CN” 來指定的。
繁體中文:使用 language=”zh-TW” 或 language=”zh-HK”(香港的繁體中文)。對於台灣的中文(繁體),就使用 zh-TW。
簡體中文:使用 language=”zh-CN”,這是指中國大陸的簡體中文。
sr.AudioFile?

Init signature: sr.AudioFile(filename_or_fileobject)
Docstring:
Creates a new AudioFile instance given a WAV/AIFF/FLAC audio file filename_or_fileobject. Subclass of AudioSource.
If filename_or_fileobject is a string, then it is interpreted as a path to an audio file on the filesystem. Otherwise, filename_or_fileobject should be a file-like object such as io.BytesIO or similar.
Note that functions that read from the audio (such as recognizer_instance.record or recognizer_instance.listen) will move ahead in the stream. For example, if you execute recognizer_instance.record(audiofile_instance, duration=10) twice, the first time it will return the first 10 seconds of audio, and the second time it will return the 10 seconds of audio right after that. This is always reset to the beginning when entering an AudioFile context.
WAV files must be in PCM/LPCM format; WAVE_FORMAT_EXTENSIBLE and compressed WAV are not supported and may result in undefined behaviour.
Both AIFF and AIFF-C (compressed AIFF) formats are supported.
FLAC files must be in native FLAC format; OGG-FLAC is not supported and may result in undefined behaviour.
File: c:\users\iec120639\appdata\local\anaconda3\lib\site-packages\speech_recognition__init__.py
Type: type
Subclasses:
sr.AudioFile 是一個用於處理音訊檔案的類別,它是 AudioSource 的子類別。可以讀取 WAV、AIFF 和 FLAC 格式的音檔。
- 參數:
filename_or_fileobject可以是檔案路徑(字串)或類似io.BytesIO的檔案物件。 - 行為:如果多次讀取音檔(例如使用
recognizer_instance.record),音訊流會向前移動。每次進入AudioFile的上下文時,流會重置到開頭。 - 格式限制:
- WAV 必須是 PCM/LPCM 格式,不支援壓縮的 WAV。
- 支援 AIFF 和 AIFF-C 格式。
- FLAC 必須是原生 FLAC 格式,不支援 OGG-FLAC。
使用這個類別可以方便地從音訊檔案中獲取數據進行語音辨識。
r.recognize_google(audio, language=’zh-TW’
無法處理大型音檔(bad request),
先將大型音檔用pydub切割為多個小音檔
再使用glob.glob()建立多音檔路徑的list
批次處理每一個音檔
code:
# -*- coding: utf-8 -*-
"""
Created on Thu Sep 5 06:59:00 2024
@author: SavingKing
ver02:
要用glob.glob() 做多檔案處理
"""
import speech_recognition as sr
import glob
import os
def mkdir_export(dirname, strr="export"):
dirname_export = os.path.join(dirname, strr)
if not os.path.exists(dirname_export):
os.mkdir(dirname_export)
print(f"已經建立資料夾: {dirname_export}")
else:
print(f"資料夾已經存在: {dirname_export}")
return dirname_export
dirname = r"D:\user\Python\speech\split"
basename = "*.wav"
lis_path = glob.glob( os.path.join(dirname,basename) )
# len(lis_path)
# Out[54]: 1232
# 初始化识别器
r = sr.Recognizer()
strr=""
for p in lis_path:
# 从音频文件中加载音频
with sr.AudioFile(p) as source:
audio = r.record(source) # 读取整个音频文件
# 使用Google Web Speech API进行识别
try:
strr += r.recognize_google(audio, language='zh-TW') # 假设是中文
print("Google Speech Recognition已將辨識內容添加進strr變數中")
except sr.UnknownValueError as e:
print(f"Google Speech Recognition could not understand audio:{e}")
except sr.RequestError as e:
print(f"Could not request results from Google Speech Recognition service; {e}")
dir_export = mkdir_export(dirname, strr="export")
basename_txt = "逐字稿.txt"
path_txt = os.path.join( dir_export, basename_txt)
with open(path_txt,"w") as f:
f.write(strr)
print(f"逐字稿已經輸出到{path_txt}")修訂code:
# -*- coding: utf-8 -*-
"""
Created on Thu Sep 5 06:59:00 2024
@author: SavingKing
ver02:
要用glob.glob() 做多檔案處理
"""
import speech_recognition as sr
import glob
import os
def mkdir_export(dirname, strr="export"):
dirname_export = os.path.join(dirname, strr)
if not os.path.exists(dirname_export):
os.mkdir(dirname_export)
print(f"已經建立資料夾: {dirname_export}")
else:
print(f"資料夾已經存在: {dirname_export}")
return dirname_export
dirname = r"D:\user\Python\speech\Jeff240719\split"
basename = "*.wav"
lis_path = glob.glob(os.path.join(dirname, basename))
# 初始化识别器
r = sr.Recognizer()
dir_export = mkdir_export(dirname, strr="export")
basename_txt = "逐字稿.txt"
path_txt = os.path.join(dir_export, basename_txt)
# 打开文件准备写入识别结果
with open(path_txt, "w") as f: #使用"a"模式更加
for p in lis_path:
# 从音频文件中加载音频
with sr.AudioFile(p) as source:
audio = r.record(source) # 读取整个音频文件
# 使用Google Web Speech API进行识别
try:
text = r.recognize_google(audio, language='zh-TW') + "\n"
# 假设是中文
f.write(text)
# 直接写入文件
print("已将辨識内容写入文件")
except sr.UnknownValueError:
print("无法理解音频")
except sr.RequestError as e:
print(f"无法从Google Speech Recognition服务获取结果: {e}")
print(f"逐字稿已經輸出到{path_txt}")改進點:
逐步寫入:我們不再等待所有音頻處理完畢後再寫入文件,而是每識別完一個文件的內容後立即寫入。這樣可以減少數據丟失的風險。
異常處理:在識別和文件寫入過程中加入了異常處理,確保即使一部分音頻識別失敗或發生寫入錯誤,程序也能繼續處理其他音頻文件。
日志輸出:通過控制台輸出信息來追蹤處理進度,有助於了解當前任務執行情況和可能出現的錯誤。
推薦hahow線上學習python: https://igrape.net/30afN
要從麥克風實時捕獲並識別語音,
可以修改上述代碼,
使用麥克風而不是音頻文件:
# -*- coding: utf-8 -*-
"""
Created on Mon Sep 16 00:13:50 2024
@author: SavingKing
"""
import speech_recognition as sr
recognizer = sr.Recognizer()
# 使用默认的麦克风作为音频源
with sr.Microphone() as source:
print("Say something!")
audio_data = recognizer.listen(source)
# speech_recognition.audio.AudioData
try:
# 使用 Google 的免费在线识别
text = recognizer.recognize_google(audio_data)
print("Google Speech Recognition thinks you said: " + text)
except sr.UnknownValueError:
print("Google Speech Recognition could not understand audio")
except sr.RequestError as e:
print("Could not request results from Google Speech Recognition service; {0}".format(e)) as file: for line in file: for w in line.split()")
.f_code.co_name #動態取得function_name")
![Python:如何用pandas.concat() 合併兩個DataFrame並重置index? pd.concat([df1, df2]) .reset_index(drop=True) ; pd.concat([df1, df2], ignore_index=True)](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2023/03/20230311123232_5.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python:如何用pandas.concat() 合併兩個DataFrame並重置index? pd.concat([df1, df2]) .reset_index(drop=True) ; pd.concat([df1, df2], ignore_index=True)")

 -> list ,回傳該路徑中有那些檔案,目錄; fpath = os.path.join(folder, “*.csv” ) ; glob.glob(fpath) #通配符匹配(globbing),抓取目錄下的指定檔案名稱")
![Python: pandas.DataFrame如何移除所有空白列?if df_raw.iloc[r,0] is np.nan: nanLst.append(r) ; df_drop0 = df_raw.drop(nanLst,axis=0) ; pandas.isna() ;df_drop0 = df_raw.drop(nanLst,axis=0).reset_index(drop=True)](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2022/12/20221206144233_67.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: pandas.DataFrame如何移除所有空白列?if df_raw.iloc[r,0] is np.nan: nanLst.append(r) ; df_drop0 = df_raw.drop(nanLst,axis=0) ; pandas.isna() ;df_drop0 = df_raw.drop(nanLst,axis=0).reset_index(drop=True)")
,班排名=SUMPRODUCT((班級=A2)*(平均>M2))+1,設定格式化的條件")

串接; numpy.concatenate() ; pandas.concat() ; 擴充ndarray的維度 np.expand_dims()")


近期留言