在資料分析過程中,我們經常會遇到缺失值(NA、NaN)的情況。Pandas 和 NumPy 兩個熱門的 Python 資料處理函式庫,各自提供了不同的方式來處理缺失值。本文將深入探討 Pandas 中的 skipna 參數以及 NumPy 中的 nanmedian 等函數,幫助您更有效地處理含有缺失值的資料。
Pandas 中的 skipna 參數
Pandas 提供了許多統計函數(如 mean()、median()、std() 等),
這些函數都有一個共同的參數:skipna。
skipna 參數的作用
skipna=False:如果存在缺失值,則結果為 NaN。
skipna=True(預設值):忽略缺失值進行計算。
實際範例:
import pandas as pd
import numpy as np
# 建立一個含有缺失值的 Series
s = pd.Series([1, 2, np.nan, 4, 5])
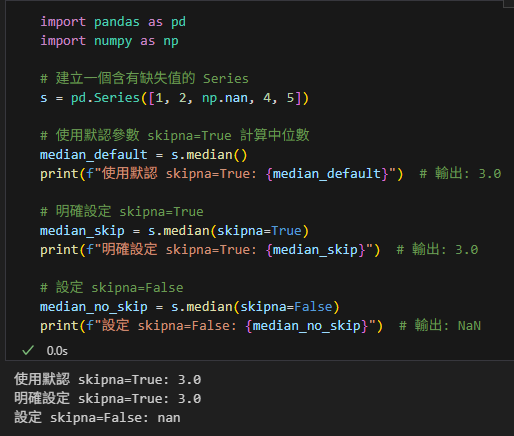
# 使用默認參數 skipna=True 計算中位數
median_default = s.median()
print(f"使用默認 skipna=True: {median_default}") # 輸出: 3.0
# 明確設定 skipna=True
median_skip = s.median(skipna=True)
print(f"明確設定 skipna=True: {median_skip}") # 輸出: 3.0
# 設定 skipna=False
median_no_skip = s.median(skipna=False)
print(f"設定 skipna=False: {median_no_skip}") # 輸出: NaN輸出結果:
NumPy 中的 nanmedian 函數
NumPy 提供了一系列以 “nan” 為前綴的函數,專門用於處理含有缺失值的資料。
nanmedian() 函數
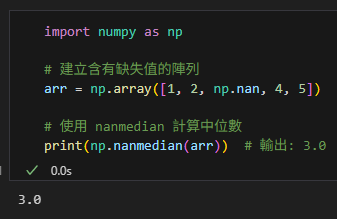
np.nanmedian() 計算忽略 NaN 值的中位數:
import numpy as np
# 建立含有缺失值的陣列
arr = np.array([1, 2, np.nan, 4, 5])
# 使用 nanmedian 計算中位數
print(np.nanmedian(arr)) # 輸出: 3.0輸出:
其他 nan 函數
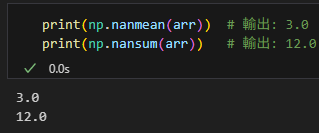
np.nanmean():忽略 NaN 的平均值np.nansum():忽略 NaN 的總和np.nanstd():忽略 NaN 的標準差np.nanvar():忽略 NaN 的變異數
Pandas 和 NumPy 的差異
- 預設行為
- Pandas 函數預設
skipna=True,自動忽略缺失值。 - NumPy 標準函數(如
median())則不忽略 NaN。
- Pandas 函數預設
- 函數設計
- Pandas 使用參數控制(
skipna)。 - NumPy 則提供專門的 nan 函數(如
nanmedian)。
- Pandas 使用參數控制(
實際應用示範
資料清理
import pandas as pd
import numpy as np
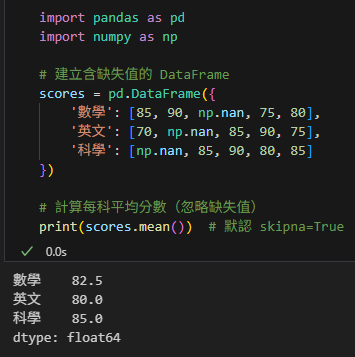
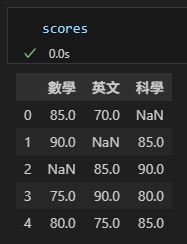
# 建立含缺失值的 DataFrame
scores = pd.DataFrame({
'數學': [85, 90, np.nan, 75, 80],
'英文': [70, np.nan, 85, 90, 75],
'科學': [np.nan, 85, 90, 80, 85]
})
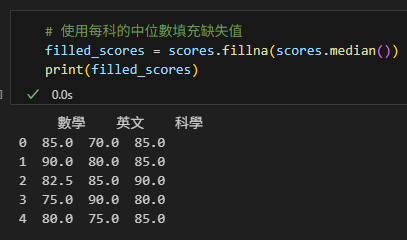
# 計算每科平均分數(忽略缺失值)
print(scores.mean()) # 默認 skipna=True輸出結果:
scores:
填充缺失值
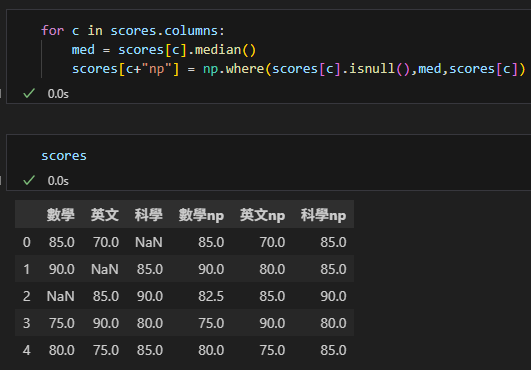
若要使用numpy.where() 實現,
就要遍歷每一欄:
for c in scores.columns:
med = scores[c].median()
scores[c+"np"] = np.where(scores[c].isnull(),med,scores[c])輸出結果:
最佳實踐建議
- 明確參數設置:即使使用默認值,也建議明確設置
skipna,提高程式碼可讀性。 - 檢查缺失值:在計算前先檢查缺失值的分佈情況。
- 選擇適合的函數:數據量大時可選擇 NumPy 函數,處理複雜結構時則使用 Pandas。
延伸閱讀
推薦hahow線上學習python: https://igrape.net/30afN
")

![Python 如何用pandas.Series.nsmallest() 找到n個與target差距最小的index?再從中找到距離idxmax最近的index?避免誤抓sidelobes的index? targetIdx = (serMean-target_value).abs().nsmallest(n).index.tolist() ;Series切片: .loc[標籤名1:標籤名2] (會含標籤名2) ; .iloc[位置1:位置2] (不含位置2)](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2023/02/20230222082954_53.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python 如何用pandas.Series.nsmallest() 找到n個與target差距最小的index?再從中找到距離idxmax最近的index?避免誤抓sidelobes的index? targetIdx = (serMean-target_value).abs().nsmallest(n).index.tolist() ;Series切片: .loc[標籤名1:標籤名2] (會含標籤名2) ; .iloc[位置1:位置2] (不含位置2)")
")
![Python: pandas.DataFrame如何移除所有空白列?pandas.isna( df_raw[0] ).tolist() ; df_drop0 = df_raw.drop(nanIdx,axis=0).reset_index(drop=True)](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2022/12/20221206184635_4.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: pandas.DataFrame如何移除所有空白列?pandas.isna( df_raw[0] ).tolist() ; df_drop0 = df_raw.drop(nanIdx,axis=0).reset_index(drop=True)")
![Excel TQC考題208: Competition,自訂格式: [<=50]0; 頁面配置>版面設定 展開>頁首/頁尾](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2022/04/20220411102844_81.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Excel TQC考題208: Competition,自訂格式: [<=50]0; 頁面配置>版面設定 展開>頁首/頁尾")
 , 如何計算IRR? numpy_financial.irr() 免費下載IRR計算機,如何寫入csv檔? csv.writer(f).writerows(2D List) ; if not os.path.exists(folder): os.makedirs(folder)")
")

![Python Pandas GroupBy 的 size 陷阱:為什麼你的計數結果總是不對?如何計算重複次數? duplicates = df.duplicated( subset = ['name'] ) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2025/06/20250609143758_0_53821c-421x245.png)

近期留言