處理大型數據集時,性能成為關鍵考量之一。Pandas 是 Python 中一個強大的數據處理庫,提供了多種方法來遍歷 DataFrame。其中 .itertuples() 方法提供了一種高效的方式來遍歷 DataFrame 的row,相比其他方法(如 .iterrows()),它在性能上通常有顯著的優勢。本文將詳細介紹 .itertuples() 的使用方法及其優點。
什麼是 .itertuples()?
.itertuples() 是 pandas DataFrame 的一個方法,它將 DataFrame 的每一row轉換為一個命名元組。相比 .iterrows() 返回的row(索引和序列對),.itertuples() 生成的命名元組不僅訪問速度更快,而且內存使用更高效。
如何使用 .itertuples()?
import pandas as pd
# 創建一個簡單的 DataFrame
df = pd.DataFrame({
'A': ['蘋果', '香蕉', '橙子'],
'B': ['足球', '籃球', '排球'],
'C': ['紅色', '藍色', '綠色']
})
# 使用 .itertuples() 遍歷 DataFrame
for row in df.itertuples():
print(row)輸出結果:
![Python: 如何逐row讀取DataFrame的資料?使用 pandas 的 df.itertuples() 方法(namedtuple讀取每一列); df.iterrows() 用Tuple[index, pd.Series] 讀取每一列 - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2024/10/20241023105826_0_bab0ff.png)
訪問元組的元素
由於 .itertuples() 返回的是命名元組,因此可以通過屬性名或索引來訪問元組的元素:
![Python: 如何逐row讀取DataFrame的資料?使用 pandas 的 df.itertuples() 方法(namedtuple讀取每一列); df.iterrows() 用Tuple[index, pd.Series] 讀取每一列 - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2024/10/20241023110742_0_fd228e.png)
原始內容的index變為從1開始,
因為[0]放了row index
.itertuples() 的優點
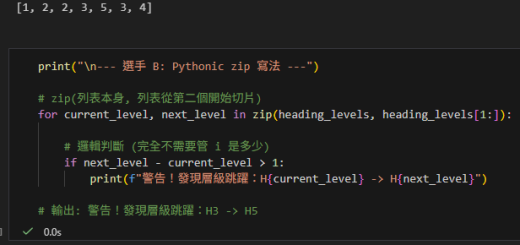
- 性能:比
.iterrows()快得多,因為.iterrows()為每一行生成一個新的 Series 對象。 - 內存效率:使用命名元組消耗的內存比 Series 對象少。
- 易用性:可以通過字段名直接訪問數據,代碼更清晰易讀。
總結
使用 .itertuples() 是在處理大型 DataFrame 時遍歷行的高效方法。它不僅提升了性能,還通過簡化數據訪問的方式增強了代碼的可讀性。在進行數據分析和數據處理的項目中,合理利用 .itertuples() 可以顯著提升代碼的執行效率。
推薦hahow線上學習python: https://igrape.net/30afN
df.iterrows()
for row in df.iterrows():
print(row)輸出結果:
![Python: 如何逐row讀取DataFrame的資料?使用 pandas 的 df.itertuples() 方法(namedtuple讀取每一列); df.iterrows() 用Tuple[index, pd.Series] 讀取每一列 - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2024/10/20241023131058_0_c71616.png)
row[0]是index
row[1]是原始資料,type為Series
![Python: 如何逐row讀取DataFrame的資料?使用 pandas 的 df.itertuples() 方法(namedtuple讀取每一列); df.iterrows() 用Tuple[index, pd.Series] 讀取每一列 - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2024/10/20241023131539_0_884e09.png)
推薦hahow線上學習python: https://igrape.net/30afN

![Python `typing.NamedTuple` (`collections.namedtuple`) 與 `typing.Literal` 教學 — 用型別「防止錯配」; StripRule = NamedTuple(“StripRule”, [(“regex”, re.Pattern), (“flag”, str)]) vs StripRule = namedtuple(“StripRule”, [“regex”, “flag”])](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2026/07/20260702150603_0_86abc2.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python `typing.NamedTuple` (`collections.namedtuple`) 與 `typing.Literal` 教學 — 用型別「防止錯配」; StripRule = NamedTuple(“StripRule”, [(“regex”, re.Pattern), (“flag”, str)]) vs StripRule = namedtuple(“StripRule”, [“regex”, “flag”])")

 ; parser.add_argument(“–name”) ; args = parser.parse_args()")







近期留言