在開發過程中,我們經常遇到需要「比較當前項目與下一個項目」的情境。例如:分析股票漲跌、檢查日誌時間戳記的間隔,或是處理文章標題的層級結構(H1 接 H2 是合理的,但 H1 直接接 H4 可能就是排版錯誤)。
許多開發者(甚至是 AI 助手)直覺會寫出基於 len() 和索引的寫法。雖然它能跑,但其實有更優雅、更 Pythonic 的選擇。
今天我們就用一個**「檢查文章標題層級是否跳躍過大」**的實際情境,來對決這兩種寫法。
情境設定
我們有一個列表,代表文章中依序出現的標題層級(1 代表 H1, 2 代表 H2…)。
規則:標題層級不能一次跳超過 1 級(例如 H1 後面可以是 H2,但不能直接跳到 H3)。
# 標題層級數據
heading_levels = [1, 2, 2, 3, 5, 3, 4]
# 注意:中間有個 3 跳到 5,這是我們要抓出的錯誤選手 A:傳統寫法 (range + len – 1)
這是最直覺的邏輯:產生一個從 0 到 長度-1 的索引,然後手動去抓 i 和 i+1。
print("--- 選手 A: 傳統索引寫法 ---")
for i in range(len(heading_levels) - 1):
current_level = heading_levels[i]
next_level = heading_levels[i+1]
# 邏輯判斷
if next_level - current_level > 1:
print(f"警告!在索引 {i} 處發現跳躍:H{current_level} -> H{next_level}")
# 輸出: 警告!在索引 3 處發現跳躍:H3 -> H5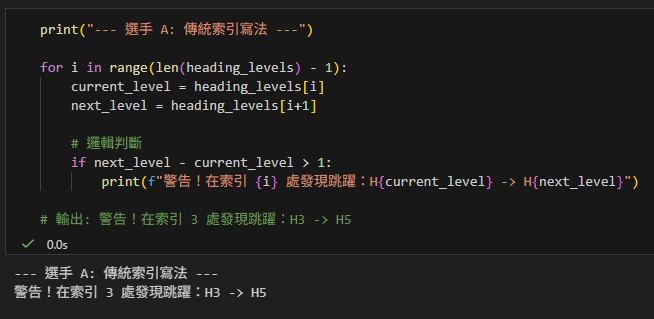
缺點分析:
- 視覺雜訊多:程式碼充滿了
[i]、[i+1]、len()、-1。這些都是「實作細節」,而非「業務邏輯」。 - 容易出錯(Off-by-one Error):最常見的 bug 就是忘記
-1,導致迴圈跑到最後一個元素時,i+1發生IndexError越界崩潰。 - 閱讀負擔:讀者必須在大腦中模擬
i的變化,確認它不會超出範圍。
選手 B:優雅寫法 (zip + 切片)
Python 的 zip 函式就像拉鍊一樣,可以把兩個列表「扣」在一起平行處理。我們將「原列表」和「從第二個元素開始的列表」扣在一起。
print("\n--- 選手 B: Pythonic zip 寫法 ---")
# zip(列表本身, 列表從第二個開始切片)
for current_level, next_level in zip(heading_levels, heading_levels[1:]):
# 邏輯判斷 (完全不需要管 i 是多少)
if next_level - current_level > 1:
print(f"警告!發現層級跳躍:H{current_level} -> H{next_level}")
# 輸出: 警告!發現層級跳躍:H3 -> H5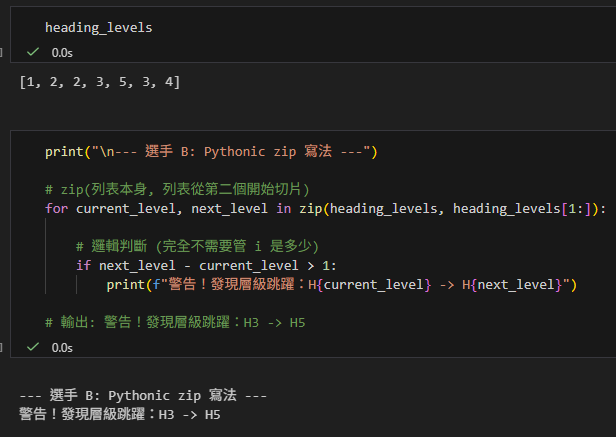
優點分析:
- 專注於「什麼 (What)」而非「如何 (How)」:程式碼直接告訴你
current和next是什麼,而不是叫你去算索引。 - 絕對安全:
zip會以最短的列表為準自動停止。當heading_levels[1:](少一個元素)遍歷完時,迴圈自然結束。你永遠不需要擔心IndexError。 - 極簡潔:省去了三行變數賦值和索引計算的程式碼。
什麼時候還是需要選手 A?
雖然 zip 很棒,但如果你**必須知道錯誤發生的位置(索引值)**用來報錯(例如:「第 5 行出錯」),單純的 zip 就無法滿足。
這時候,我們可以祭出 Python 的終極組合技:enumerate + zip。
print("\n--- 進階技: enumerate + zip ---")
# i 代表當前的索引位置
for i, (curr, nxt) in enumerate(zip(heading_levels, heading_levels[1:])):
if nxt - curr > 1:
print(f"錯誤發生在第 {i} 筆數據:H{curr} 不能直接接 H{nxt}")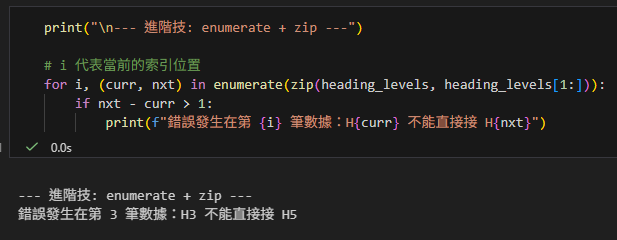
總結
- 如果你還在寫
range(len(x) - 1):請停下來,這通常是 C 或 Java 的習慣遺留。 - 如果你只需要比較值:請使用
zip(x, x[1:]),這是 Python 清晰與效率的展現。 - 如果你需要索引:請使用
enumerate(zip(...))。
寫出機器能跑的 Code 很簡單,但寫出人類一眼就能看懂、且不易出錯的 Code,才是高手的境界。
推薦hahow線上學習python: https://igrape.net/30afN

:深入比較 self.、__class__. 與 self.__class__. 存取類別變數")
,dtype=int) ; B = np.zeros((2,3,4),dtype=int)")
")

 程式碼input(),終端機卻無法輸入資料且顯示亂碼,該如何設定?齒輪 > 設定,搜尋: run in terminal, 打勾: Wether to run code in integrated Terminal.")
 與 listC = listA + listB的差別?")
![Python TQC 510 費氏數列,list[], f.append(n3)](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2022/04/20220522152013_66.jpg?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python TQC 510 費氏數列,list[], f.append(n3)")

近期留言