在自動化處理 Word 文件時,最常見的痛點就是:
「為什麼我的程式碼跳過了某些段落?」或者
「為什麼讀取出來的順序跟我在 Word 裡看到的不一樣?」
這通常是因為我們過度依賴了 doc.paragraphs。
本篇教學將帶你深入 python-docx 的底層邏輯,
學會如何像人類閱讀一樣,
依照線性順序(Linear Order) 同時讀取段落與表格。
1. 準備工作:生成測試文件
為了驗證我們的程式碼,
我們先用 Python 生成一個包含「段落」與「表格」交錯的複雜 Word 文件。
請將以下程式碼複製到 Jupyter Notebook 中執行:
import os
from docx import Document
from docx.shared import Pt
# 設定輸出路徑
output_dir = r"D:\Temp"
if not os.path.exists(output_dir):
os.makedirs(output_dir)
file_path = os.path.join(output_dir, "demo_structure.docx")
# 建立文件
doc = Document()
# 1. 加入第一個段落
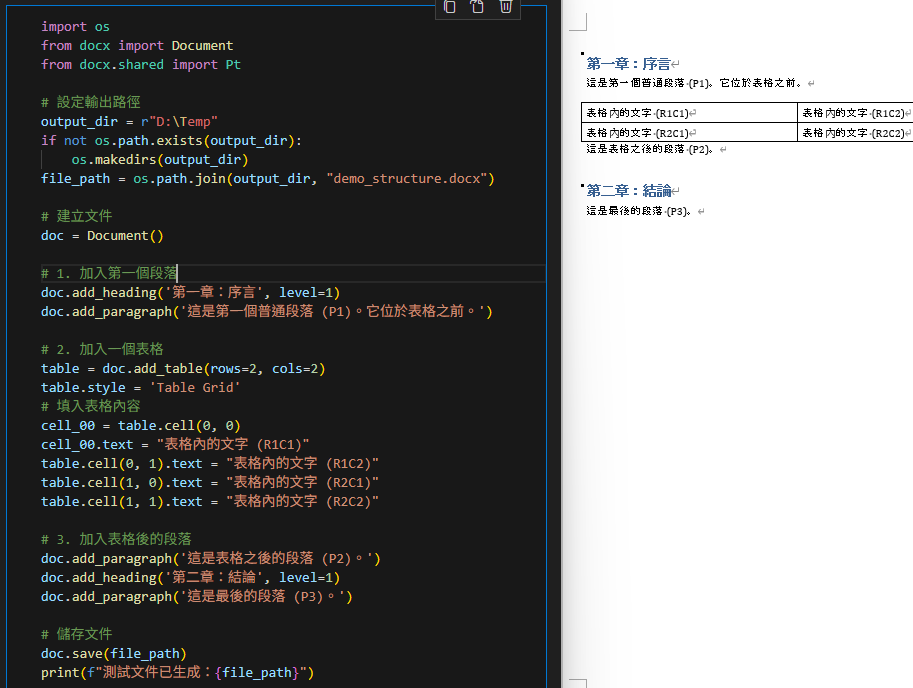
doc.add_heading('第一章:序言', level=1)
doc.add_paragraph('這是第一個普通段落 (P1)。它位於表格之前。')
# 2. 加入一個表格
table = doc.add_table(rows=2, cols=2)
table.style = 'Table Grid'
# 填入表格內容
cell_00 = table.cell(0, 0)
cell_00.text = "表格內的文字 (R1C1)"
table.cell(0, 1).text = "表格內的文字 (R1C2)"
table.cell(1, 0).text = "表格內的文字 (R2C1)"
table.cell(1, 1).text = "表格內的文字 (R2C2)"
# 3. 加入表格後的段落
doc.add_paragraph('這是表格之後的段落 (P2)。')
doc.add_heading('第二章:結論', level=1)
doc.add_paragraph('這是最後的段落 (P3)。')
# 儲存文件
doc.save(file_path)
print(f"測試文件已生成:{file_path}")測試文件已生成:D:\Temp\demo_structure.docx
2. 常見誤區:分開讀取的陷阱
大多數初學者會使用 doc.paragraphs 和 doc.tables 分開處理。讓我們看看這樣做會發生什麼事。
# %%
from docx import Document
doc = Document(r"D:\Temp\demo_structure.docx")
print("--- 嘗試 1: 只讀取 doc.paragraphs ---")
for i, p in enumerate(doc.paragraphs):
print(f"段落 {i}: {p.text}")
print("\n--- 嘗試 2: 只讀取 doc.tables ---")
for i, t in enumerate(doc.tables):
print(f"表格 {i}: 包含 {len(t.rows)} 列")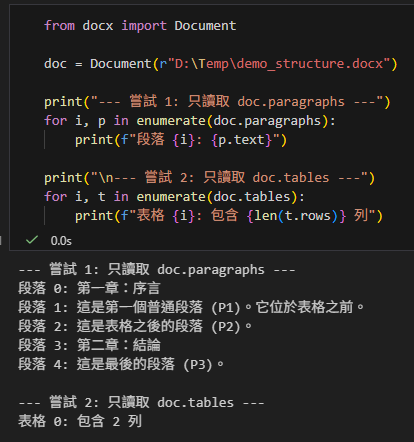
結果分析:
- 問題:你會發現「嘗試 1」完全忽略了表格裡的文字;「嘗試 2」雖然抓到了表格,但你失去了它與前後段落的順序關係。你無法知道這個表格是在「第一章」之後還是在「第二章」之後。
3. 終極解法:使用 doc.element.body 遍歷底層 XML
要解決順序問題,
我們必須進入 python-docx 的底層 (lxml 物件)。
Word 文件的 body 其實是一個 XML 列表,
依序存放著 <w:p> (段落) 和 <w:tbl> (表格)。
我們需要兩個關鍵的輔助函數,
將底層的 XML 元素 (OxmlElement) 轉回我們熟悉的
高階 Python 物件 (Paragraph 和 Table)。
請執行以下程式碼(後面補充簡潔版code):
from docx.document import Document as _Document
from docx.oxml.text.paragraph import CT_P
from docx.oxml.table import CT_Tbl
from docx.table import _Cell, Table
from docx.text.paragraph import Paragraph
# --- 關鍵函數 1: 將 XML 轉為 Paragraph 物件 ---
def create_paragraph(element, parent):
"""
將 oxml 的 CT_P 元素包裝成高階的 Paragraph 物件
"""
return Paragraph(element, parent)
# --- 關鍵函數 2: 將 XML 轉為 Table 物件 ---
def create_table(element, parent):
"""
將 oxml 的 CT_Tbl 元素包裝成高階的 Table 物件
"""
return Table(element, parent)
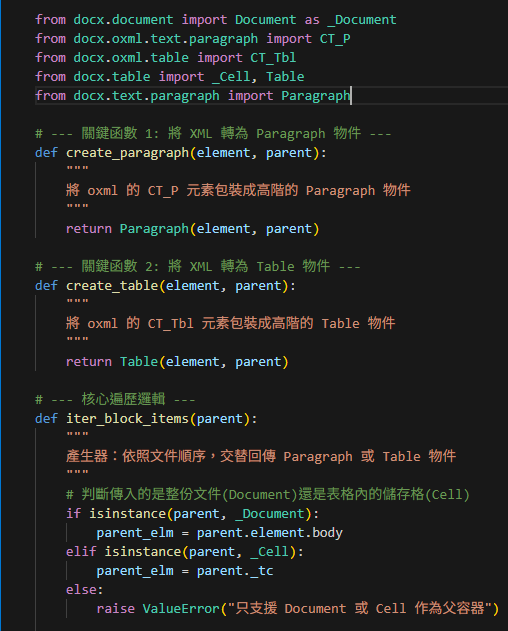
# --- 核心遍歷邏輯 ---
def iter_block_items(parent):
"""
產生器:依照文件順序,交替回傳 Paragraph 或 Table 物件
"""
# 判斷傳入的是整份文件(Document)還是表格內的儲存格(Cell)
if isinstance(parent, _Document):
parent_elm = parent.element.body
elif isinstance(parent, _Cell):
parent_elm = parent._tc
else:
raise ValueError("只支援 Document 或 Cell 作為父容器")
# 遍歷所有子節點 (XML children)
for child in parent_elm.iterchildren():
# 如果子節點是「段落」類型
if isinstance(child, CT_P):
yield create_paragraph(child, parent)
# 如果子節點是「表格」類型
elif isinstance(child, CT_Tbl):
yield create_table(child, parent)
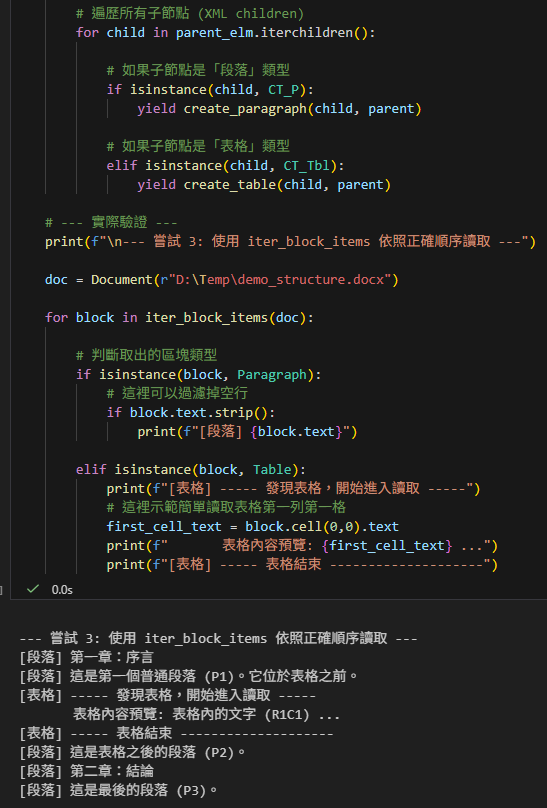
# --- 實際驗證 ---
print(f"\n--- 嘗試 3: 使用 iter_block_items 依照正確順序讀取 ---")
doc = Document(r"D:\Temp\demo_structure.docx")
for block in iter_block_items(doc):
# 判斷取出的區塊類型
if isinstance(block, Paragraph):
# 這裡可以過濾掉空行
if block.text.strip():
print(f"[段落] {block.text}")
elif isinstance(block, Table):
print(f"[表格] ----- 發現表格,開始進入讀取 -----")
# 這裡示範簡單讀取表格第一列第一格
first_cell_text = block.cell(0,0).text
print(f" 表格內容預覽: {first_cell_text} ...")
print(f"[表格] ----- 表格結束 --------------------")輸出:
程式碼解析
doc.element.body: 這是存取 XML 結構的入口。CT_P與CT_Tbl: 這是python-docx定義的底層類別,分別代表 XML 中的<w:p>(段落) 和<w:tbl>(表格)。我們用isinstance來判斷當前讀取到的節點是什麼。- 封裝函數:
Paragraph(child, parent)和Table(child, parent)這兩個建構子是將底層 XML 重新包裝成我們平常好用的物件,讓我們可以繼續使用.text或.rows等屬性。
結論
- 如果你只需要文字統計,用
doc.paragraphs。 - 如果你只需要處理數據,用
doc.tables。 - 如果你需要分析文件結構、保留閱讀順序,或者標題可能藏在表格裡,請務必使用
doc.element.body搭配上述的iter_block_items方法。
推薦hahow線上學習python: https://igrape.net/30afN
from docx import Document
from docx.text.paragraph import Paragraph
from docx.table import Table
# 讀取檔案
doc = Document(r"D:\Temp\demo_structure.docx")
# --- 核心邏輯:簡單粗暴,直接有效 ---
# doc.element.body.iterchildren() 會依序吐出 XML 中的子節點
for child in doc.element.body.iterchildren():
# 直接看這個節點的 Python 類別名稱
child_type = type(child).__name__
if child_type == "CT_P":
# 這是段落 (Paragraph)
para = Paragraph(child, doc)
print(f"【段落】: {para.text}")
elif child_type == "CT_Tbl":
# 這是表格 (Table)
table = Table(child, doc)
print(f"【表格】: 發現一個 {len(table.rows)} 行的表格")
# 如果需要,這裡可以再進去遍歷表格內容
# for row in table.rows:
# for cell in row.cells:
# print(cell.text)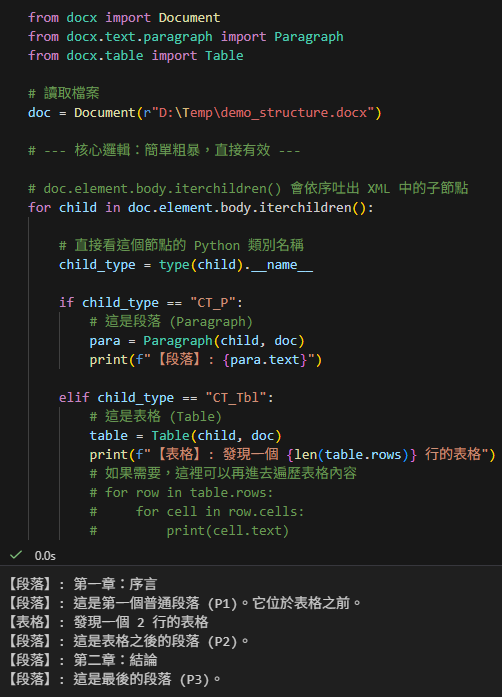
推薦hahow線上學習python: https://igrape.net/30afN

 ) .decode(‘utf-8’)")
 在不同資料類型(array/dict)下的 columns 參數用法 #賦值 #選擇")



與滾動條(Scrollbar)? canvas = tk.Canvas(root, width=400, height=300) ; scrollbar = tk.Scrollbar(root, command = canvas.yview) ; canvas.configure( yscrollcommand = scrollbar.set)")
,函數自己呼叫自己,遞迴(Recursive) , dict的value是dict ,巢狀dict,可使用tuple當key,但不可使用list當key")


近期留言