code:
from bs4 import BeautifulSoup
html = """
<html>
<body>
<div class="product" id="item1">商品1</div>
<div class="product" id="item2">商品2</div>
<p class="product">段落</p>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
# find_all() 的寫法
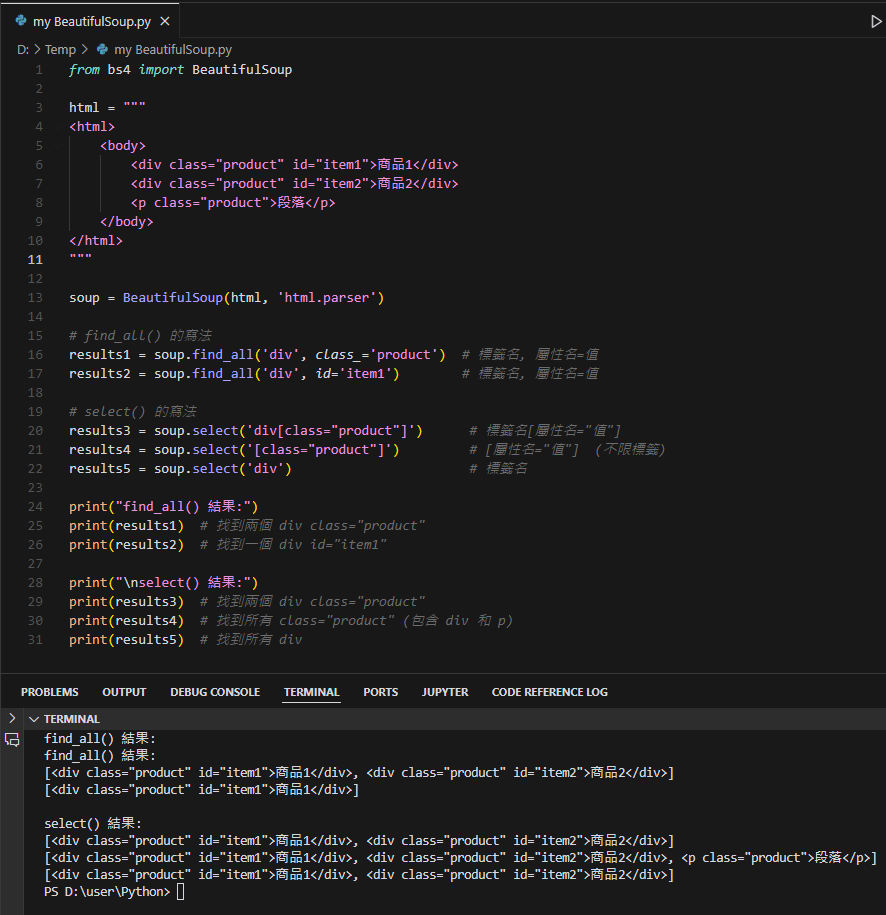
results1 = soup.find_all('div', class_='product') # 標籤名, 屬性名=值
results2 = soup.find_all('div', id='item1') # 標籤名, 屬性名=值
# select() 的寫法
results3 = soup.select('div[class="product"]') # 標籤名[屬性名="值"]
results4 = soup.select('[class="product"]') # [屬性名="值"] (不限標籤)
results5 = soup.select('div') # 標籤名
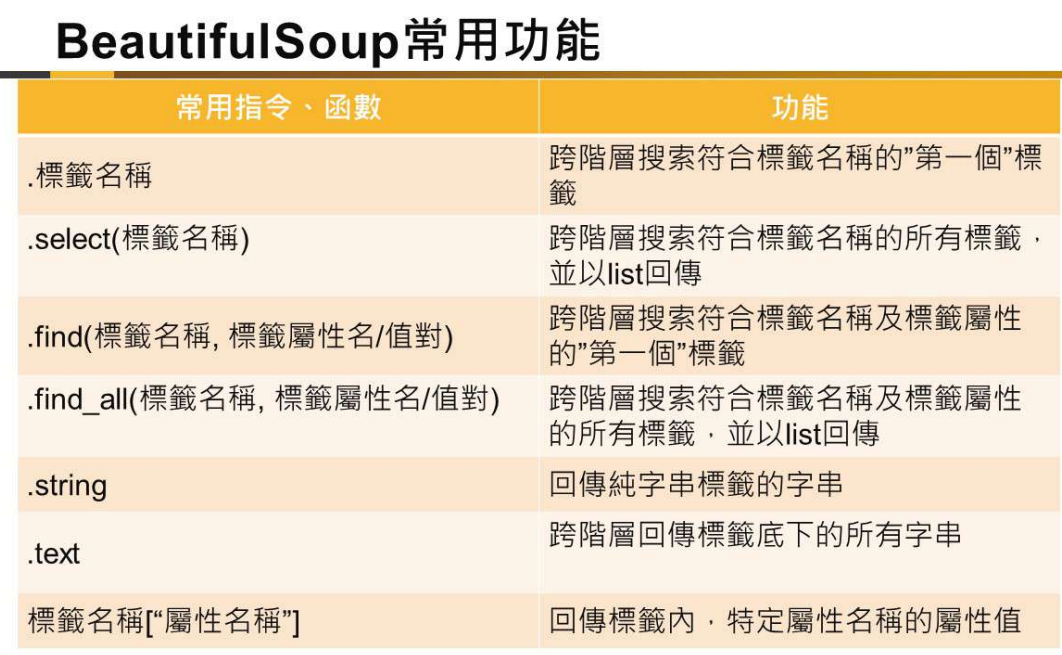
print("find_all() 結果:")
print(results1) # 找到兩個 div class="product"
print(results2) # 找到一個 div id="item1"
print("\nselect() 結果:")
print(results3) # 找到兩個 div class="product"
print(results4) # 找到所有 class="product" (包含 div 和 p)
print(results5) # 找到所有 div輸出結果:
find_all():
參數格式:find_all(標籤名, 屬性名=值)
例如:find_all(‘div’, class_=’product’)
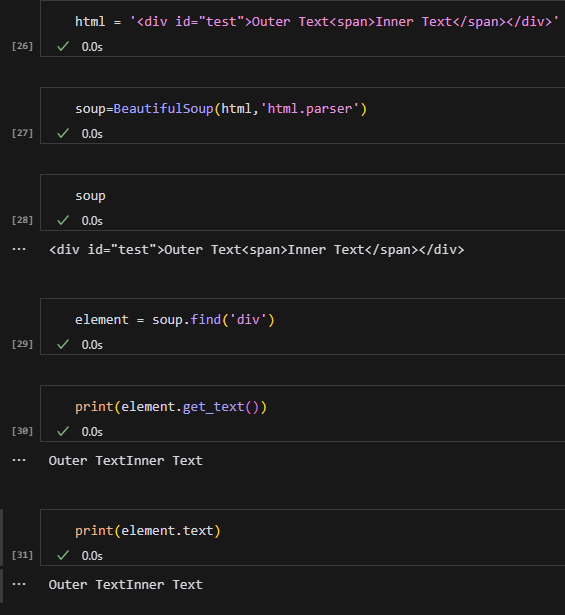
select():
參數格式:select(‘標籤名[屬性名=”值”]’)
或只用標籤名:select(‘div’)
或只用屬性:select(‘[class=”product”]’)
[] 是 定位的意思
select() 使用的是 CSS 選擇器語法,
所以更靈活,可以用更複雜的選擇條件。
以下三者同效果:
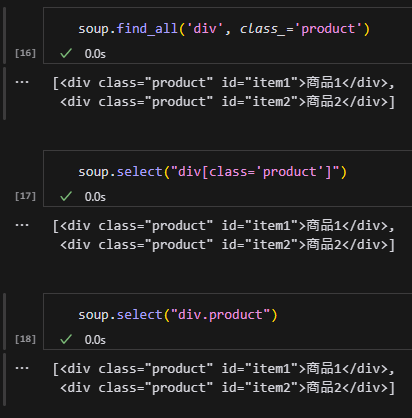
使用soup.find_all(‘div’, class_=’product’) 時,
class_是外露的參數名,
且跟Python個關鍵字class撞名
所以結尾多一個_
避免撞名
使用.select()時,"div[class='product']"
class被字串的雙引號包覆
不需要修改
屬性名剛好是class,
可以使用.連接
以下三者同效果:
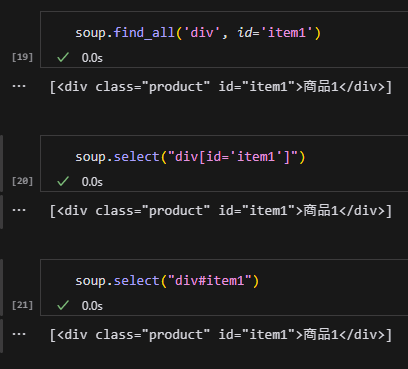
屬性名剛好是id
可以使用#連接
推薦hahow線上學習python: https://igrape.net/30afN
code:
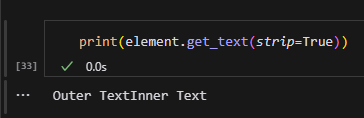
from bs4 import BeautifulSoup
html = '<div id="test">Outer Text<span>Inner Text</span></div>'
soup = BeautifulSoup(html, 'html.parser')
element = soup.find(id="test")
# 使用 .string
print("element.string:", element.string) # 輸出:None(因為有子標籤 <span>)
# 使用 .get_text()
print("element.get_text():", element.get_text()) # 輸出:Outer TextInner Text
# 使用 .text
print("element.text:", element.text) # 輸出:Outer TextInner Textprint(soup.prettify())
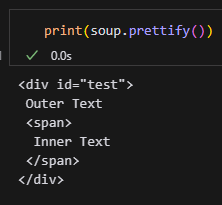
輸出結果:
為什麼 element.string 是 None?
.string 只返回元素的直接文字內容,而且僅當該元素沒有子標籤時才返回文字。如果有子標籤,它會判定文字是「混合的」,因此返回 None。
.get_text() 和 .text 的作用
.get_text() 和 .text 是 BeautifulSoup 提供的兩個完全等效的方法,用來提取元素及其所有子元素的文字內容,並將它們合併為一個字符串。
它們的特點:
提取所有文字內容: 包括元素內部的直接文字和子標籤的文字。
合併文字: 將提取到的文字合併為一個字符串,默認不保留任何 HTML 標籤結構。
.string:
僅返回元素的直接文字,適合處理沒有子標籤的純文字情況。
有子標籤時返回 None。
.get_text() 和 .text:
提取元素及其所有子元素的文字內容,非常適合處理有子標籤的情況。
.text .get_text() 兩者輸出完全一樣。
推薦hahow線上學習python: https://igrape.net/30afN
.text 是屬性,
.get_text() 是方法。
雖然它們的功能在 BeautifulSoup 中非常相似,
但它們的性質和用法確實有所不同,因此這樣的區分更為恰當。
- .text
屬性:
.text 是 BeautifulSoup 中的屬性,直接用於獲取元素及其子元素的文字內容。
它在內部其實是調用了 .get_text() 方法的結果,所以功能相同。
用法簡單:
不需要調用方法(不需要括號),更適合作為輕量化的使用方式。
- .get_text()
方法:
.get_text() 是 BeautifulSoup 中的方法,可以接受參數來進一步定制文字提取過程。
它比 .text 更靈活,例如,可以指定分隔符或是否去除多餘空格。
用法多樣:
適合需要定制化文字提取的情況。
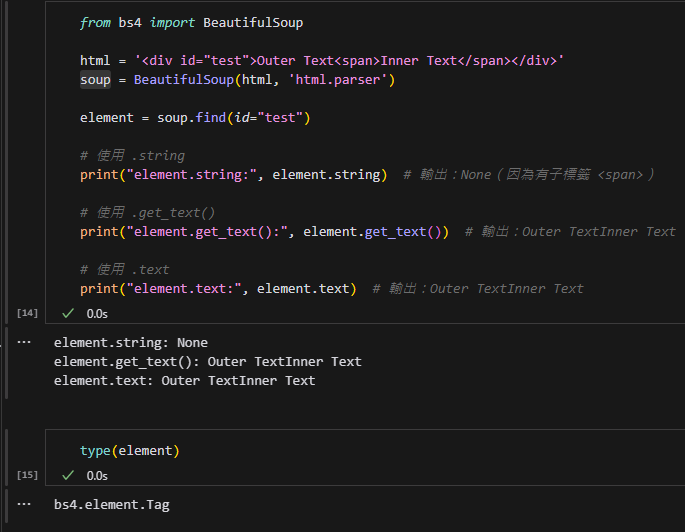
程式碼示例:
element = soup.find('div')
print(element.get_text()) # 獲取文字內容(功能與 .text 相同)輸出結果:
get_text() 的特定參數
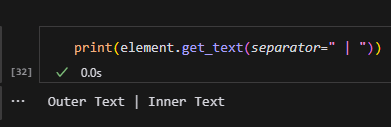
separator: 指定返回的文字塊之間使用的分隔符。
strip: 是否去除前後的空格。
比較表:

.text 是屬性,簡單直觀,適合快速提取元素及子元素的所有文字內容。
.get_text() 是方法,功能更靈活,適合需要定制輸出(如分隔符、去除空格等)的場合。
所以,更精確的描述應該是:「.text 是屬性,.get_text() 是方法,功能相似,但 .get_text() 更靈活。」
推薦hahow線上學習python: https://igrape.net/30afN
 ; soup = bs(response.text) ; bs4.element.Tag .find_all() ; .select() ; .find() 差別為何?soup是大HTML, tag是小HTML,可以使用相同的方法")

 or(|) xor(^) not")
 的差別 #若能重新命名: dict.set_value_default() 比較像實際行為")
")

? from tkinter import Tk, Button, filedialog ; 物件導向避免使用全域變數 ; pandas.read_csv(fpath, skip_blank_lines = True) 可以濾掉空列,Tab , 不定數空白")
 ; socket.connect() ; socket.send()")

![Python 進階實戰:深入 Word 核心,挖出那一坨 BLOB (含自省 Debug 技巧, BLOB= Binary Large Object) ; part = doc.part.rels[rid].target_part ; return part.blob if "ImagePart" in type(part).__name__ else None - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2026/01/20260126111046_0_cd8751-520x245.png)

近期留言