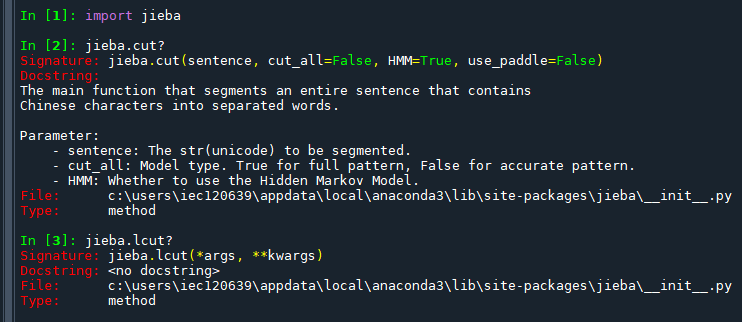
Signature:
jieba.cut 是 jieba 分詞工具的主要函數,用於將一段包含中文的句子切分成獨立的詞語。以下對其 參數、功能 和 用法 進行詳細說明。
1. 函數簽名
jieba.cut(sentence, cut_all=False, HMM=True, use_paddle=False)2. 參數說明
必選參數
sentence:- 類型:
str - 說明:需要分詞的句子(包含中文字符)。這是必填參數。
- 類型:
可選參數
cut_all:- 類型:
bool - 功能:決定分詞的模式。
True:啟用全模式,會將句子中所有可能的詞語列出。False(默認):啟用精確模式,只會切分出最精確的詞語。
- 用例:
- 類型:

2.HMM:
- 類型:
bool - 功能:是否啟用隱馬爾可夫模型
(Hidden Markov Model, HMM,HMM)
來處理未登錄詞(不在詞典中的詞語)。True(默認):啟用 HMM 模型,能夠識別新詞、人名等。False:禁用 HMM 模型,僅基於詞典進行分詞。
use_paddle:
- 類型:
bool - 功能:是否啟用 PaddlePaddle 深度學習框架進行分詞(需要安裝 PaddlePaddle 才能使用)。
False(默認):不啟用 Paddle 模式。True:啟用 Paddle 模式進行分詞(Paddle 模式支持更精確的新詞識別,但速度較慢)。
- 用例:
import jieba
# 啟用 Paddle 模式
jieba.enable_paddle()
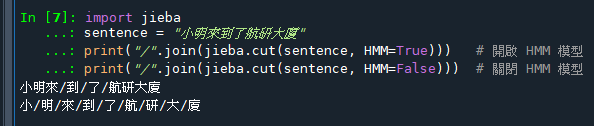
sentence = "小明來到了航研大廈"
result = jieba.cut(sentence, use_paddle=True)
print("使用 Paddle 模式:", "/".join(result))
#輸出結果(假設 Paddle 已安裝並啟用):
#使用 Paddle 模式: 小明/來到/了/航研/大廈5. 注意事項
- 返回值是生成器
jieba.cut返回生成器而不是列表,如果需要獲取具體結果,需要用join()或list()處理。

- 全模式可能結果過多
在全模式下,jieba會將所有可能的詞語列出,可能會導致結果過於冗長。 - HMM 模型影響結果
啟用 HMM 模型時,jieba能識別新詞或未登錄詞(如人名、機構名等);關閉 HMM 時,分詞僅依據內建詞典。 - Paddle 模式需要安裝依賴
如果使用use_paddle=True,需先安裝 PaddlePaddle(深度學習框架),否則會報錯。
6. 總結
jieba.cut是jieba的核心分詞函數,支持多種分詞模式(全模式、精確模式)和不同技術(HMM 模型、Paddle 深度學習模式)。- 常用參數:
cut_all=True:啟用全模式,列出所有可能的詞。HMM=True:啟用隱馬爾可夫模型,識別新詞。use_paddle=True:使用 Paddle 模式,需額外安裝依賴。
如果需要最高精度
使用 精確模式 + HMM 模型 + Paddle 模式:
result = jieba.cut(sentence, cut_all=False, HMM=True, use_paddle=True)推薦hahow線上學習python: https://igrape.net/30afN
 函數教學")

元素不會重複,strNew=str1.replace(” “,””)")
 #zinfo_or_arcname: ZipInfo | str ; data: bytes | str")
![Python `typing.NamedTuple` (`collections.namedtuple`) 與 `typing.Literal` 教學 — 用型別「防止錯配」; StripRule = NamedTuple(“StripRule”, [(“regex”, re.Pattern), (“flag”, str)]) vs StripRule = namedtuple(“StripRule”, [“regex”, “flag”])](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2026/07/20260702150603_0_86abc2.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python `typing.NamedTuple` (`collections.namedtuple`) 與 `typing.Literal` 教學 — 用型別「防止錯配」; StripRule = NamedTuple(“StripRule”, [(“regex”, re.Pattern), (“flag”, str)]) vs StripRule = namedtuple(“StripRule”, [“regex”, “flag”])")
")
 as f: json_str = f.read() ; jsn = json.loads(json_str)")
 傳回沿軸最小值的index,參數不能用list,可用numpy.array(),把list轉為array")
,==是邏輯判斷式,=是指定")
![Python: 字串 str.find(關鍵字[,start][,end]),找不到的話回傳-1,如何找出資料字串中,所有關鍵字的index?詞頻計算 - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/11/20221122100657_32-520x245.png)
![Python Pathlib 實戰:優雅地篩選多種圖片檔案; images = [f for f in p.glob("*") if f.suffix.lower() in img_extensions] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2026/01/20260128111659_0_736612-520x245.png)

近期留言