在資料科學與機器學習的領域中,處理**分類變數(categorical variables)**是一個常見而重要的步驟。這篇教學文將詳細介紹兩種常用的資料編碼工具:get_dummies 和 LabelEncoder。透過這篇文章,你將學會如何選擇正確的工具並靈活應用它們來進一步提升你的數據處理能力!
一、為什麼需要資料編碼?
在機器學習中,大多數演算法(例如線性迴歸、決策樹、隨機森林等)無法直接處理分類文字數據。這是因為它們需要數字化的輸入數據來進行計算。因此,我們需要將分類變數轉換成數值型格式,這就是資料編碼的核心目的。
常見的分類變數範例:
- 性別:
Male、Female - 顏色:
Red、Blue、Green - 等級:
Low、Medium、High
二、get_dummies 與 LabelEncoder 的使用場景
1. get_dummies:適合多類別獨熱編碼(One-Hot Encoding)
get_dummies 是 Pandas 提供的一個函數,用於將分類變數轉換為**獨熱編碼(One-Hot Encoding)**的格式。它會為每個類別生成一個新的特徵列,並用 0 或 1 表示該樣本是否屬於該類別。
使用場景
- 當分類變數沒有大小關係,且需要避免引入順序性(ordinal)的假設。
- 適用於多類別資料,例如性別、地區、顏色等。
範例
import pandas as pd
# 建立資料框
data = pd.DataFrame({
'Gender': ['Male', 'Female', 'Female', 'Male'],
'Color': ['Red', 'Blue', 'Green', 'Red']
})
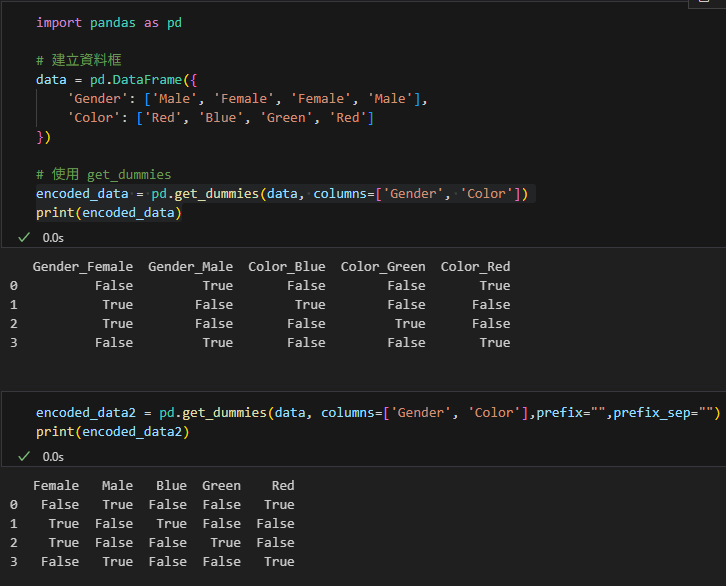
# 使用 get_dummies
encoded_data = pd.get_dummies(data,
columns=['Gender', 'Color'])
print(encoded_data)輸出結果:
優點
- 簡單易用,且結果非常直觀。
- 適合無序的分類變數。
缺點
- 當類別數量過多時,會導致特徵數量爆炸(稱為「維度災難」)。
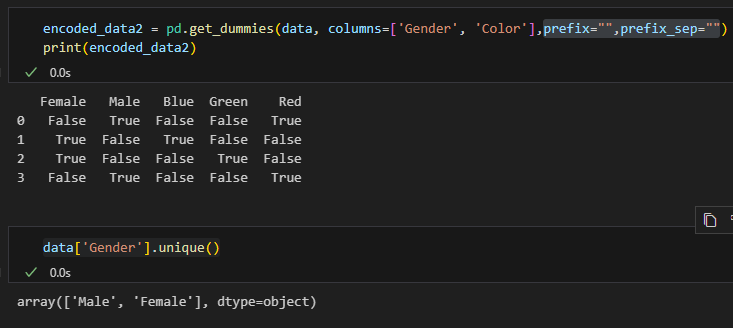
data[‘Gender’].unique()
可以先取得獨熱編碼的column name
若get_dummies() 需要比對,可以使用
prefix=””, prefix_sep=””
2. LabelEncoder:適合單列標籤數值化
LabelEncoder 是 Scikit-learn 提供的工具,
用於將分類變數轉換為整數標籤。
例如,Red 會被編碼為 0,Blue 編碼為 1,以此類推。
使用場景
- 當分類變數有大小或順序關係(ordinal),例如等級(
Low、Medium、High)。 - 當需要對單一列進行快速編碼時。
範例
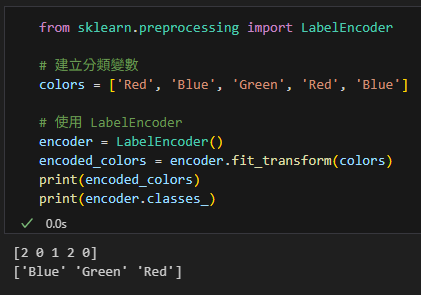
from sklearn.preprocessing import LabelEncoder
# 建立分類變數
colors = ['Red', 'Blue', 'Green', 'Red', 'Blue']
# 使用 LabelEncoder
encoder = LabelEncoder()
encoded_colors = encoder.fit_transform(colors)
print(encoded_colors)
print(encoder.classes_)輸出結果:
優點
- 簡單快速,只需一行程式即可完成。
- 適合有順序的分類變數。
缺點
- 編碼後的數字可能會引入「類別之間有大小關係」的假設,對無序分類變數會產生問題。
.inverse_transform() 還原:
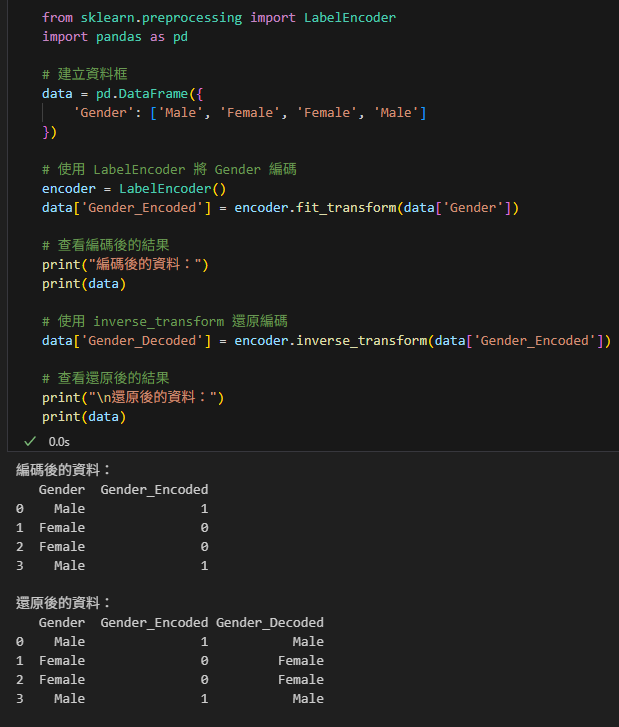
from sklearn.preprocessing import LabelEncoder
import pandas as pd
# 建立資料框
data = pd.DataFrame({
'Gender': ['Male', 'Female', 'Female', 'Male']
})
# 使用 LabelEncoder 將 Gender 編碼
encoder = LabelEncoder()
data['Gender_Encoded'] = encoder.fit_transform(data['Gender'])
# 查看編碼後的結果
print("編碼後的資料:")
print(data)
# 使用 inverse_transform 還原編碼
data['Gender_Decoded'] = encoder.inverse_transform(data['Gender_Encoded'])
# 查看還原後的結果
print("\n還原後的資料:")
print(data)輸出:
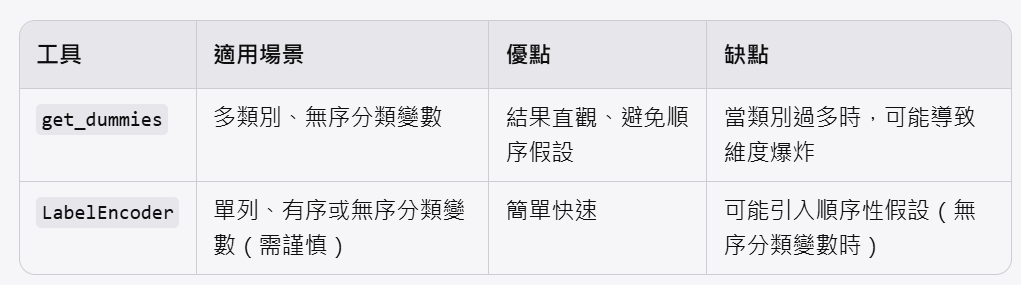
三、如何選擇?
四、進階技巧:兩者結合使用
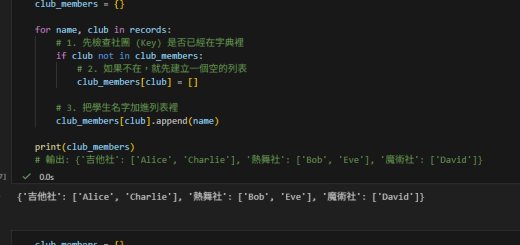
在實務中,get_dummies 和 LabelEncoder 可以搭配使用。
例如,對於有些特徵需要獨熱編碼,
而有些特徵或機器學習中的 y (response)
只需要簡單的數值化,
我們可以靈活應用兩種方法來處理。
範例:
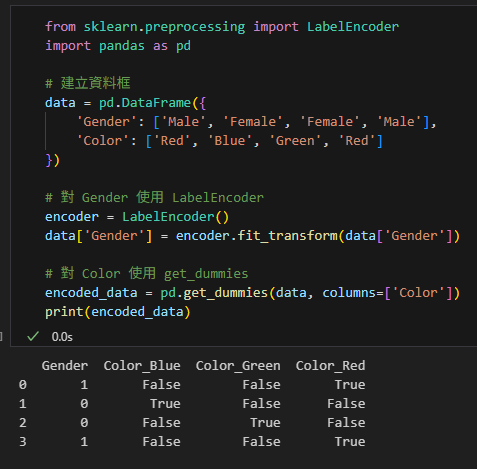
from sklearn.preprocessing import LabelEncoder
import pandas as pd
# 建立資料框
data = pd.DataFrame({
'Gender': ['Male', 'Female', 'Female', 'Male'],
'Color': ['Red', 'Blue', 'Green', 'Red']
})
# 對 Gender 使用 LabelEncoder
encoder = LabelEncoder()
data['Gender'] = encoder.fit_transform(data['Gender'])
# 對 Color 使用 get_dummies
encoded_data = pd.get_dummies(data, columns=['Color'])
print(encoded_data)輸出:
五、總結
- 使用
get_dummies處理無序分類變數,適合多類別資料且需要避免大小關係假設。 - 使用
LabelEncoder處理有序分類變數,或快速對單列進行編碼。 - 根據資料特性選擇合適的方法,並靈活結合兩者來處理複雜的資料集。
推薦hahow線上學習python: https://igrape.net/30afN

![Python四種型態增加元素 list.append(元素), tuple = tuple + (元素, ), set.add(元素), dict[key]=value](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2022/05/20220513083711_22.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python四種型態增加元素 list.append(元素), tuple = tuple + (元素, ), set.add(元素), dict[key]=value")

 實戰:教你如何讓程式碼「自我介紹」; func_name = sys._getframe().f_code.co_name ; inspect.currentframe().f_code.co_name")
![Python: matplotlib如何控制legend的位置? ax.legend(handles=[patch], loc=’upper left’, bbox_to_anchor=(6/10, 3/5)](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2023/05/20230502163945_79.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: matplotlib如何控制legend的位置? ax.legend(handles=[patch], loc=’upper left’, bbox_to_anchor=(6/10, 3/5)")

, dtype=float) ; print(data.shape); min0 = numpy.min(a,axis=0) ; min1 = numpy.min(a,axis=1) #2次沿軸1 ; numpy.average() ;array的軸向")
")
![Python:如何將folder_path & file_name合併為file_path? fpath = os.path.join (folder , fname) #不需要[ ]包覆folder,fname; fpath1 = “\\”.join( [folder , fname] ) #需要[ ] 包覆folder,fname ; 反過來講,file_path如何拆分為folder_path & file_name? os.path.dirname() ; os.path.basename() ; file_name如何拆分為主檔名與副檔名os.path.splitext() #split(分裂) ext](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2023/07/20230717184401_87.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python:如何將folder_path & file_name合併為file_path? fpath = os.path.join (folder , fname) #不需要[ ]包覆folder,fname; fpath1 = “\\”.join( [folder , fname] ) #需要[ ] 包覆folder,fname ; 反過來講,file_path如何拆分為folder_path & file_name? os.path.dirname() ; os.path.basename() ; file_name如何拆分為主檔名與副檔名os.path.splitext() #split(分裂) ext")
![Python: pandas.Series如何只保留str,去除重複值?#isinstance(x:Any, str) -> bool #.drop_duplicates() #Series.apply( function )逐元素應用function運算 #DataFrame.apply( function )逐Series應用function運算 .drop_duplicates() 跟.unique()有何差別? df.drop_duplicates() 等效於 df[~df.duplicated()] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2024/11/20241123194900_0_5218de-520x245.png)

近期留言