SUMPRODUCT預設語法
=SUMPRODUCT (array1, [array2], [array3], …)
若只有兩陣列
會計算Array1的元素1*Array2的元素1 +
Array1的元素2*Array2的元素2 +
Array1的元素3*Array2的元素3
……
各陣列引數必須有相同的維度
不過也可以用來取代
COUNTIF, SUMIF函數
這時候的語法變成
SUMPRODUCT(條件1*條件2*條件3*……)
條件的格式如:
Range 運算子 Criteria
B2:B7=”儲蓄保險王”
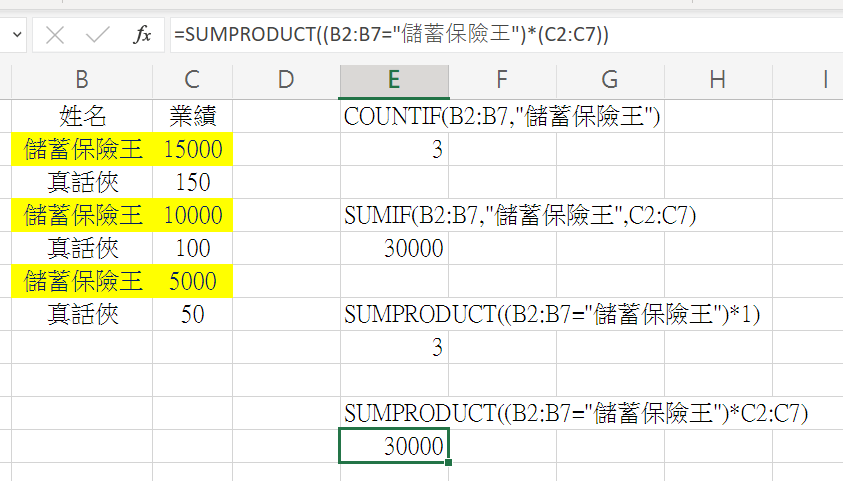
本月業績如下圖,
請問”儲蓄保險王”
貢獻了幾次業績?
總共多少業績?
貢獻了幾次業績?
使用COUNTIF()
=COUNTIF(B2:B7,”儲蓄保險王”)
答案為3
改用SUMPRODUCT()
=SUMPRODUCT((B2:B7=”儲蓄保險王”)*1)
答案一樣為3
貢獻多少業績?
使用SUMIF函數
=SUMIF(B2:B7,”儲蓄保險王”,C2:C7)
答案為30000
改用SUMPRODUCT函數
=SUMPRODUCT((B2:B7=”儲蓄保險王”)*(C2:C7))
答案一樣是30000
既然SUMPRODUCT的工作
可以用COUNTIF, SUMIF取代
那還有什麼特別呢?
再繼續看下一個例子
一間迷你小學
有三個班級,
每班有三個學生
學生分數如下
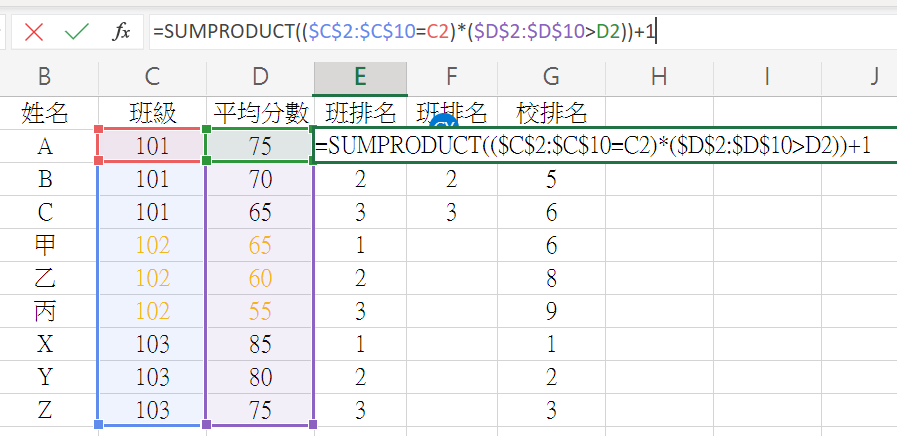
校排名可以簡單用
RANK或RANK.EQ解答
=RANK.EQ(D2,$D$2:$D$10)
班排名呢?
=SUMPRODUCT(($C$2:$C$10=C2)*($D$2:$D$10>D2))+1
以下錯誤示範
=SUMPRODUCT(($C$2:$C$10=C2)*($D$2:$D$10>=D2))
本範例可以算出一樣的結果
但若出現同分狀況
例如:B,C學生同分70
正確公式會出現兩個第二名
但錯誤示範則出現兩個第三名
第二名從缺
這時候要用COUNTIFS替代的話
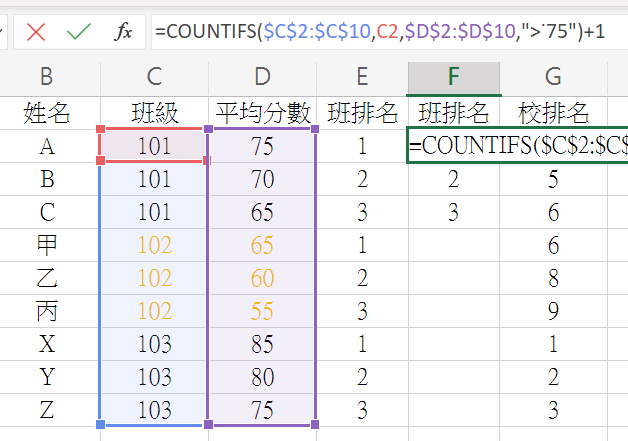
=COUNTIFS($C$2:$C$10,C2,$D$2:$D$10,“>75”)+1
“>75” , “>70” , “>65”
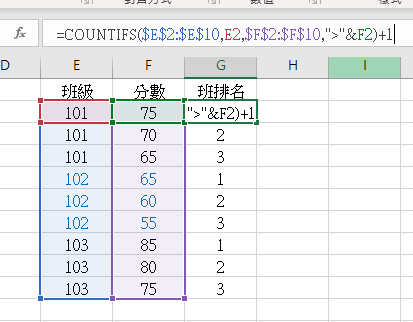
要用以下較不直覺的方式指定儲存格
才能拖曳
=COUNTIFS($E$2:$E$10,E2,$F$2:$F$10,“>”&F2)+1
“>F2″的話,無法拖曳
SUMPRODUCT(條件1*條件2*條件3*……)
沒有條件數目的限制
可以取代COUNTIFS, SUMIFS

")
")
? import matplotlib.pyplot as plt; fig, ax = plt.subplots(1,1) ; plt.minorticks_on() ; ax.grid(visible=True, which=”major”, c=”k”, linewidth=1) ; ax.grid(visible=True, which=”minor”, c=”k”, linewidth=0.5)")

 ; np.hstack(tuple) ; ravel(“F”) #解開(線團等),把二維array轉成一維")
![「Python 的兩條路」:一次搞懂 sys.path (找 .py) 與 os.environ[‘PATH’] (找 .exe) 的愛恨情仇](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2026/01/20260114094100_0_424ead.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "「Python 的兩條路」:一次搞懂 sys.path (找 .py) 與 os.environ[‘PATH’] (找 .exe) 的愛恨情仇")
: pattern = re.compile(r’\d+’) #re.Pattern ; pattern.match() ; pattern.search() ; pattern.findall() ; pattern.finditer() ; pattern.sub() 如何使用?")

![Python: 如何創建多層column name的pandas.DataFrame? df = pd.read_csv ('data.csv', header=[0, 1], sep=",") ; col = pd .MultiIndex .from_arrays( aryCol ) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/03/20230314164119_32-520x245.png)
![Python struct.pack() 將整數轉換為bytes ; while list: str1=list[0] ; 中間內容; list=[1:] #切片 ,遍歷list中的每一個元素,跟for i in list 類似 ; timeit() #計時 - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/10/20221012095050_42-520x245.png)

近期留言