這篇教學整理這次在 `get_class_in_jsons_47.py` 遇到的真實問題:
– 檔案在 VS Code 右下角顯示 `UTF-8 with BOM`
– 用 Python `read_text(encoding=”utf-8″)` 讀進來後,開頭多了一個看不見的字元
– `ast.parse()` 因為第一個字不是正常語法 token,而是 `U+FEFF`,所以報錯
– 改用 `encoding=”utf-8-sig”` 後恢復正常
這不是 Unicode 教科書,而是這個專案裡實際遇到、實際排查、實際修好的案例整理。
## 1. 先講結論
如果你在 Python 裡讀檔時遇到這種狀況:
– 檔案開頭看起來是 `”””`
– 但 `ast.parse()`、某些 parser、某些 regex 或某些 JSON 處理在第一行就炸掉
– 錯誤訊息提到 `U+FEFF`
優先懷疑:
– 這個檔案是 `UTF-8 with BOM`
而最常見的修法是:
from pathlib import Path
text = Path(r"d:\example\get_class_in_jsons_47.py").read_text(encoding="utf-8-sig")也就是:
– 不用 `utf-8`
– 改用 `utf-8-sig`
## 2. BOM 到底是什麼
`BOM` 是 `Byte Order Mark`。
它本質上是一段放在檔案最前面的特殊位元組標記,用來告訴讀取端:
– 這份檔案是 Unicode 編碼
– 在某些編碼裡,甚至可以順便提示位元組順序
對 UTF-8 來說,BOM 對應的 bytes 是:
EF BB BF
如果把它讀成 Python 字串,常會看到:
‘\ufeff’
也就是這次錯誤裡的:
– `U+FEFF`
## 3. `U+FEFF` 是什麼
`U+FEFF` 不是三引號,也不是 Python 語法。
它是 Unicode 字元,常被拿來當 BOM 的文字表示。
所以當你肉眼看到檔案開頭像這樣:
"""Python 用 `utf-8` 讀進來後,實際可能是:
\ufeff"""只是 `\ufeff` 是不可見字元,所以你平常看不到。
這也是為什麼很多人會說:
– 「我三引號前面明明什麼都沒有」
其實是:
– 肉眼看不到
– 但字串裡真的有一個前導隱形字元
## 4. 為什麼 UTF-8 理論上不需要 BOM
UTF-8 和 UTF-16 / UTF-32 不一樣。
UTF-16 / UTF-32 會碰到位元組順序問題,所以 BOM 很有用。
但 UTF-8 本身沒有 byte order 問題,所以從理論上:
– UTF-8 不需要 BOM
也因此很多人會把純 UTF-8 視為更乾淨的預設。
## 5. 為什麼 Windows 檔案常常還是有 BOM
雖然 UTF-8 理論上不需要 BOM,但 Windows 世界裡,BOM 還是很常見。
常見原因有:
1. 某些工具歷史上會靠 BOM 來判斷「這是 UTF-8,不是 ANSI 或其他本地編碼」
2. 某些舊工具或某些存檔流程,預設就會寫成 `UTF-8 with BOM`
3. 編輯器常會沿用檔案原本的編碼格式繼續存檔
4. 使用者曾經用 `Save with Encoding` 存成帶 BOM 的格式
所以看到 BOM,不代表你現在的 VS Code 很舊。
更準確地說:
– 這個檔案某個時間點曾被存成 `UTF-8 with BOM`
– 後來 VS Code 只是延續它目前的編碼狀態
## 6. `utf-8` 和 `utf-8-sig` 差在哪裡
### `utf-8`
text = path.read_text(encoding=”utf-8″)
意思是:
– 用 UTF-8 解碼
– 但不特別幫你處理 BOM
如果檔案開頭真的有 BOM,讀進來後第一個字元常會是:
‘\ufeff’
### `utf-8-sig`
text = path.read_text(encoding="utf-8-sig")意思是:
– 也是用 UTF-8 解碼
– 但如果檔案開頭有 BOM,就把它當成 signature 吃掉
所以 `sig` 幾乎可以直接理解成:
– signature
– 也就是 BOM 那個前導簽名標記
一句話:
– `utf-8-sig = UTF-8 + 會自動處理開頭 BOM`
## 7. 這次專案的真實驗證結果
這次我們直接對 `get_class_in_jsons_47.py` 做了檢查,結果如下:
has_utf8_bom: True
first_3_bytes: b'\xef\xbb\xbf'
first_12_bytes: b'\xef\xbb\xbf"""\r\n...'
repr(text_utf8[:10]): '\ufeff"""\n要對 *.'
first_codepoint_hex: 0xfeff
repr(text_utf8_sig[:10]): '"""\n要對 *.d'這組結果的意思很明確:
1. 這個檔案真的有 UTF-8 BOM
2. 用 `utf-8` 讀時,第一個字元真的是 `\ufeff`
3. 用 `utf-8-sig` 讀時,BOM 被正確移掉,開頭就回到正常的 `”””`
## 8. 直接檢查某個檔案有沒有 BOM 的 notebook code
from pathlib import Path
path = Path(r"d:\user\Python\Open_Test\docx_to_class\get_class_in_jsons_47.py")
raw = path.read_bytes()
utf8_bom = b"\xef\xbb\xbf"
print("has_utf8_bom:", raw.startswith(utf8_bom))
print("first_3_bytes:", raw[:3])
print("first_12_bytes:", raw[:12])
text_utf8 = path.read_text(encoding="utf-8")
print("repr(text_utf8[:10]):", repr(text_utf8[:10]))
print("first_codepoint_hex:", hex(ord(text_utf8[0])))
text_utf8_sig = path.read_text(encoding="utf-8-sig")
print("repr(text_utf8_sig[:10]):", repr(text_utf8_sig[:10]))如果你只想看有沒有 BOM,最短版可以寫成:
from pathlib import Path
path = Path(r"d:\user\example\get_class_in_jsons_47.py")
print(path.read_bytes().startswith(b"\xef\xbb\xbf"))## 9. 這次為什麼 `ast.parse()` 會炸
這次 notebook 裡的關鍵錯誤是:
tree = ast.parse(source)如果 `source` 是用 `encoding=”utf-8″` 讀進來,而檔案又剛好帶 BOM,
那第一個字元就不是正常的 `”`,而是 `\ufeff`。
也就是說,`ast.parse()` 實際看到的比較像:
\ufeff”””
這就可能觸發像下面這類錯誤:
SyntaxError: invalid non-printable character U+FEFF修法就是:
source = py_path.read_text(encoding="utf-8-sig")## 10. 本專案版本掃描結果
這次也批次掃過 `get_class_in_jsons_02.py ~ get_class_in_jsons_47.py` 的 BOM 狀態。
結果是:
– `v02 ~ v18`:純 `UTF-8`
– `v19 ~ v47`:`UTF-8 with BOM`
也就是說,這個系列檔案的編碼切換點落在:
– `v18 -> v19`
所以至少可以確定:
– 從 `get_class_in_jsons_19.py` 開始,這系列檔案就已經全面改成帶 BOM 的 UTF-8
## 11. 如何在 VS Code 把檔案從 `UTF-8 with BOM` 改回 `UTF-8`
這次實測可行的步驟是:
1. 點右下角的 `UTF-8 with BOM`
2. 選 `Save with Encoding`
3. 選 `UTF-8`
4. 存回原本的檔案
做完之後,右下角就會從:
– `UTF-8 with BOM`
變成:
– `UTF-8`
這代表 BOM 已經被移除。
## 12. VS Code 設定裡要不要明寫 `files.encoding`
如果你希望未來新檔或後續編輯更偏向無 BOM,
可以在 VS Code User Settings 裡明寫:
“`json
“files.encoding”: “utf8”
“`
實際操作步驟可以寫成:
1. 按 `Ctrl+Shift+P`
2. 輸入 `Preferences: Open User Settings (JSON)`
3. 打開後,把下面這行加進去:
“`json
“files.encoding”: “utf8”
“`
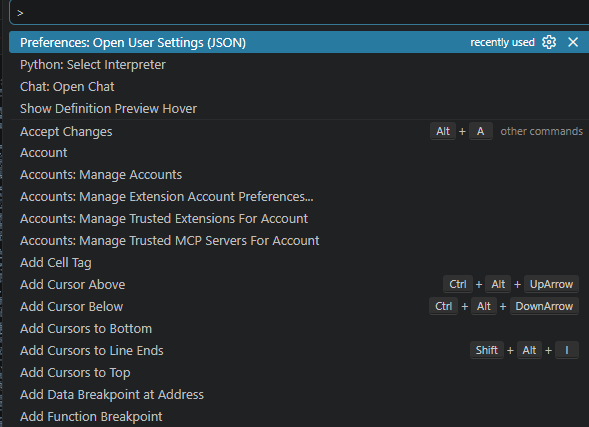
如果你的 `settings.json` 已經有其他設定,記得補在正確的 JSON 結構裡,例如:
“`json
{
“files.autoSave”: “afterDelay”,
“files.encoding”: “utf8”
}
“`
如果你比較習慣圖形化介面,也可以直接打開 Settings UI,
再搜尋 `files.encoding`,把值設成 `utf8`。
注意這裡是 VS Code 設定值,不是 Python 編碼名稱。
所以:
– VS Code `settings.json` 寫 `utf8`
– Python `read_text()` / `open()` 常寫 `utf-8` 或 `utf-8-sig`
這行設定的幫助是:
– 降低未來又把新檔存成 `UTF-8 with BOM` 的機率
但它不是萬能的。它不會自動把現有檔案全部去 BOM。
如果你想順手把文字檔行為也整理得更穩一點,可以再考慮這幾個可選設定:
{
"files.encoding": "utf8",
"files.autoGuessEncoding": true,
"files.eol": "\n",
"files.insertFinalNewline": true,
"files.trimTrailingWhitespace": true
}它們的用途分別是:
– `files.autoGuessEncoding`: 讀舊檔時,
VS Code 會嘗試猜測是否為其他編碼;
屬於輔助設定,不是 BOM 核心開關
– `files.eol`: 統一換行符,例如固定成 `\n`
– `files.insertFinalNewline`: 存檔時自動在檔尾補一個換行
– `files.trimTrailingWhitespace`: 存檔時去掉行尾多餘空白
如果你的重點只有「避免 UTF-8 with BOM」,那最重要的仍然是:
“`json
“files.encoding”: “utf8”
“`
## 13. 常見誤解 FAQ
### Q1. 我三引號前面明明沒看到東西,為什麼會有 `U+FEFF`?
因為 `U+FEFF` 通常是不可見字元。
你肉眼看到的是:
“`python
“””
“`
但 Python 讀到的可能是:
“`python
\ufeff”””
“`
### Q2. 看到 `UTF-8 with BOM` 是否代表我現在的 VS Code 很舊?
不是。
比較可能是:
– 這個檔案早就被某次操作存成帶 BOM
– 目前的 VS Code 只是沿用它現在的檔案編碼
### Q3. `files.encoding` 要寫 `utf8` 還是 `utf-8`?
在 VS Code 設定裡要寫:
“`json
“files.encoding”: “utf8”
“`
不是 `utf-8`。
### Q4. `sig` 是不是跟 BOM 有關?
是。
`utf-8-sig` 裡的 `sig` 可以理解成 signature,也就是 BOM 那個前導標記。
### Q5. 我只是另存覆蓋原檔,BOM 會自動消失嗎?
不一定。
如果你沒有明確用 `Save with Encoding -> UTF-8`,
很多時候只是沿用原本的 `UTF-8 with BOM` 再存一次。
## 14. 本專案的實務建議
對這個專案來說,建議把做法拆成兩件事:
### A. 讀未知歷史檔案
如果檔案可能來自:
– Windows 工具
– 舊腳本
– 歷史版本
– 其他外部流程
那讀檔時可以優先考慮:
“`python
encoding=”utf-8-sig”
“`
理由是:
– 檔案若有 BOM,`utf-8-sig` 會自動吃掉
– 檔案若沒有 BOM,行為通常幾乎等同 `utf-8`
所以在這個專案常見的 UTF-8 純文字檔場景裡,
讀取時一律用 `utf-8-sig`,
通常是合理且低風險的做法,
沒有明顯壞副作用。
尤其是在這種場景:
– 要交給 `ast.parse()`
– 要做程式碼分析
– 要讀 Python / JSON / Markdown 等純文字檔
### B. 新檔與日常編輯
預設維持:
– `UTF-8`
– 無 BOM
也就是說,最實務的分工是:
– 讀取:`utf-8-sig`
– 寫入:`utf-8`
這樣通常比較乾淨,也比較不容易讓 parser 在第一個字元就踩雷。
## 15. 最後一句話
如果你看到:
– 檔案表面看起來正常
– 但第一行 parser 就炸
– 錯誤訊息提到 `U+FEFF`
先不要懷疑三引號、不要懷疑 Markdown、也不要先懷疑 Python 本身。
先檢查:
– 這個檔案是不是 `UTF-8 with BOM`
這往往就是根因。
推薦hahow線上學習python: https://igrape.net/30afN
 與 迭代器iter")
 #輸出csv或xlsx時,如何不輸出index 跟 header ? .to_csv( “write.txt”, index=False, header=False)")

![Python TQC考題810 最大值與最小值之差,L=[eval(i) for i in s.split()]](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2022/05/20220507094526_36.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python TQC考題810 最大值與最小值之差,L=[eval(i) for i in s.split()]")
.f_code.co_name #動態取得function_name")

 > Ctrl + shift +F9 取消所有超連結;參考資料>插入索引>自動標記,隱藏標記後,參考資料>插入索引")
, f.write(datanew)")


近期留言