test.txt(分隔子有, ” “) :
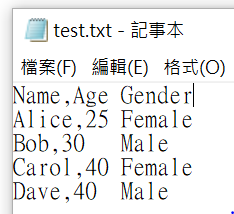
import pandas as pd
df = pd.read_csv(‘test.txt’,
sep=’\s*,\s*|\s+’,
engine=’python’)
print(df)
這裡的\s*,\s*表示匹配零個或多個空格之後的逗號,
\s+表示匹配一個或多個空格。
\s表示匹配任何空白字符,
包括空格、制表符、换页符等等,
等价于[ \f\n\r\t\v]
而”\s+”则表示匹配任意多个上面的字符
這種方法需要使用正則表達式的知識,
但是可以處理較為複雜的CSV檔案。
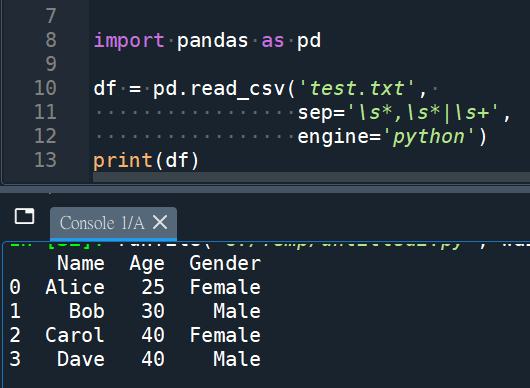
sep=’\,|\s+’
, or 不定數空白
推薦hahow線上學習python: https://igrape.net/30afN
; dict(key)提取dict內的元素; importlib.reload(); np.zeros(); np.array()")
」與 AST 語法樹")
 搜尋元素位於list中的那一個index")
")
 ; socket.connect() ; socket.send()")
 vs jieba.lcut() 使用指南")

 實戰:教你如何讓程式碼「自我介紹」; func_name = sys._getframe().f_code.co_name ; inspect.currentframe().f_code.co_name")
的函式.rfind() .replace() 切片與串接; 如何尋找直欄中,含有特定關鍵字的列數? pandas.Series.str.contains(“Hz”) ;如何將Series中的內容去掉首末的空格並小寫? pandas.Series .str.strip() .str.lower() #需要兩次.str")
![Python: 正則表示法(regular expression)中的量詞: +*? ; reading="100.000" units="degrees C" ; 如何以空格分割字串,卻不分割"degrees C"中的空格? re.findall(r'(w+)="([^"]*)"', input_string) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2024/02/20240207213438_0-520x245.png)

近期留言