本筆記本將帶您了解如何使用 yield 和 yield from 來處理資料流,
最終應用於將 Word 文件中的巢狀結構(表格內的段落)「拉平」成單一序列。
1. 基礎暖身:什麼是 yield?
yield 讓函式變成一個生成器 (Generator)。
它不會一次回傳所有資料,而是「一次產生一個」,
省記憶體且適合處理串流資料。
def make_bread_gen():
yield "麵包 1 (熱騰騰)"
yield "麵包 2 (剛出爐)"
yield "麵包 3 (最後一個)"
# 驗證:像 List 一樣跑迴圈,但它是惰性運算的
for bread in make_bread_gen():
print(f"收到: {bread}")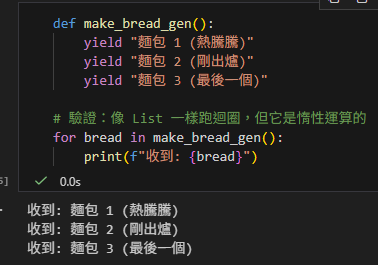
2. 進階關鍵:為什麼需要 yield from?
當我們需要「函式呼叫函式」來產生資料時(例如:巢狀結構),
如果只用 yield,你必須寫迴圈去接值再傳出去。yield from 建立了「直通管道」,
讓子生成器的產出直接傳給最外層,不需要寫繁雜的轉接迴圈。
模擬情境:拆解多層清單 (Nested Lists)
# 模擬一個巢狀結構:清單裡面還有清單
nested_data = [
"外層 A",
["內層 1", "內層 2", ["深層 X", "深層 Y"]], # 這裡有多層
"外層 B"
]
def flatten_list(data):
for item in data:
if isinstance(item, list):
# 【關鍵】遇到 List,委派給自己 (遞迴) 去處理
# yield from 會自動把內層吐出來的每個元素,直接傳到最外面
yield from flatten_list(item)
else:
yield item
print("拉平後的結果:")
print(list(flatten_list(nested_data)))
3. 實戰應用:解決 Word 表格的巢狀遍歷
Word 文件 (docx) 的結構也是巢狀的:
- 文件 (Document)
- 段落 (Paragraph)
- 表格 (Table)
- 列 (Row)
- 儲存格 (Cell) -> 這裡面又可以包含段落或表格!
- 列 (Row)
我們要寫一個函數,依照視覺順序把所有文字抓出來。
首先,我們先製作一個測試用 Word 檔,裡面包含主文和表格。
import os
from docx import Document
# 準備測試檔案路徑
DEMO_PATH = r"D:\Temp\docx_notebook_demo.docx"
os.makedirs(os.path.dirname(DEMO_PATH), exist_ok=True)
def create_demo_docx(path):
doc = Document()
doc.add_paragraph("【1. 主文開頭】Start")
# 建立 2x2 表格
table = doc.add_table(rows=2, cols=2)
table.style = 'Table Grid'
table.cell(0, 0).text = "【2. 表格 R0C0】Cell 1"
# 這一格塞兩段
cell_01 = table.cell(0, 1)
cell_01.paragraphs[0].text = "【3. 表格 R0C1】Cell 2 - Para 1"
cell_01.add_paragraph("【4. 表格 R0C1】Cell 2 - Para 2")
table.cell(1, 1).text = "【5. 表格 R1C1】End of Table"
doc.add_paragraph("【6. 主文結尾】End")
doc.save(path)
print(f"測試檔案已建立: {path}")
create_demo_docx(DEMO_PATH)docx_notebook_demo.docx

4. 核心解法:遞迴遍歷生成器
我們定義 iter_all_paragraphs(parent)。
parent可以是 文件 也可以是 儲存格。- 利用
yield from,當遇到表格時,
我們就鑽進去每一格,把那一格當作新的 parent 進行遞迴。
from typing import Union, Iterable
from docx.document import Document as DocxDocument
from docx.table import _Cell, Table
from docx.text.paragraph import Paragraph
from docx.oxml.ns import qn
def iter_all_paragraphs(parent: Union[DocxDocument, _Cell]) -> Iterable[Paragraph]:
"""
遞迴走訪 parent 內的節點。
如果遇到表格,就使用 yield from iter_all_paragraphs(cell) 深入挖掘。
"""
# 1. 取得底層 XML 容器
# 我們只處理這兩種類型的容器,因為它們是 Paragraph 的直接父節點。
# 雖然 Table 也是物件,但它的子節點是 Row -> Cell,而不是 Paragraph,
# 所以我們不是「遍歷 Table」,而是「穿過 Table」直接找它下面的 Cell。
if isinstance(parent, DocxDocument):
# DocxDocument 的內容(段落、表格)都存放在
# .element.body 這個 <w:body> XML 節點下
parent_elm = parent.element.body
elif isinstance(parent, _Cell):
# _Cell (表格儲存格) 的內容都存放在 ._tc 這個 <w:tc> XML 節點下
parent_elm = parent._tc
else:
# 如果傳入的是其他不可預期的物件 (例如 Header/Footer 等),暫不處理
return
# 2. 遍歷 XML 子節點
for child in parent_elm.iterchildren():
# 情況 A: 是段落 -> 直接產出
if child.tag == qn('w:p'):
yield Paragraph(child, parent)
# 情況 B: 是表格 -> 深入每一格 -> 委派(yield from)
elif child.tag == qn('w:tbl'):
table = Table(child, parent)
for row in table.rows:
for cell in row.cells:
yield from iter_all_paragraphs(cell)5. 驗證成果
現在我們可以把它當作一個普通的平面 list 來讀取了!
請觀察下列輸出的順序,是否為我們預期的視覺順序(包含插入在表格中間的文字)。
# 讀取剛剛建立的檔案
doc = Document(DEMO_PATH)
print("--- 開始依序讀取 ---")
for i, p in enumerate(iter_all_paragraphs(doc), 1):
print(f"段落 {i}: {p.text}")
print("--- 結束 ---")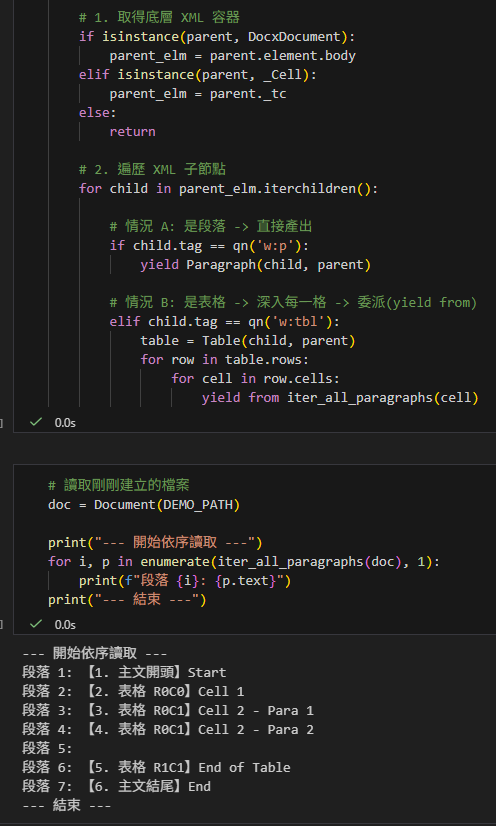
推薦hahow線上學習python: https://igrape.net/30afN
from docx.document import Document as DocxDocument #類別
from docx import Document #function這是一個常見的命名衝突問題,在 python-docx 中特別明顯。
取別名(Aliasing)是最簡潔且明確的解決方案。
為什麼這會發生?
在 python-docx 函式庫的設計中:
- docx.Document (函式):
- 這是一個工廠函式 (Factory Function)。
- 用途是:開啟一個舊檔案或建立一個新檔案。
- 我們通常這樣用:doc = Document(“file.docx”)。
- docx.document.Document (類別):
- 這才是真正的文件物件類別 (Class)。
- isinstance(doc, …) 需要用到這個「型別」。
- 我們通常只在寫 Type Hinting (: Document) 或 isinstance 檢查時才會用到它。
為什麼取別名是最好的?
如果不取別名,我們就必須寫得很長,或者容易搞混:
方案 A:不取別名 (容易混淆)
from docx import Document # 工廠函式
from docx.document import Document # 壞消息:這裡覆蓋了上面那個變數!
# 結果你現在不能用 Document("file.docx") 了,因為它變成了類別方案 B:寫全名 (太長)
import docx.document
def process(doc):
if isinstance(doc, docx.document.Document): # 寫起來很冗長
pass方案 C:取別名 (最簡潔 ✅)
from docx import Document # 用來開檔案的 (主要入口)
from docx.document import Document as DocxDocument # 用來做型別檢查的 (只在少數地方用)
def process(parent: DocxDocument): # 清楚明瞭:這是一個文件物件型別
pass所以在 iter_all_paragraphs 這個函式中,
為了同時支援 Type Hinting (parent: DocxDocument) 和 isinstance 檢查,
取別名 DocxDocument 是最標準且語意最清晰的做法。
推薦hahow線上學習python: https://igrape.net/30afN
def iter_all_paragraphs(parent: Union[DocxDocument, _Cell]) -> Iterable[Paragraph]:目前的 -> Iterable[Paragraph] 才是完全正確的。
為什麼?(Generator 的特殊行為)
這牽涉到普通函式 (return value) 與 生成器函式 (yield value) 的巨大差異:
- 普通函式 (如
extract_image_bytes):- 遇到
return None(或沒寫 return) -> 真的會回傳None物件。 - 所以型別必須寫
Optional[bytes](意即:可能是 bytes,也可能是 None)。
- 遇到
- 生成器函式 (如
iter_all_paragraphs):- 只要函式內有
yield關鍵字,呼叫它時,Python 保證一定會回傳一個「生成器物件 (Generator Object)」 (這是一個Iterable)。 - 函式內的
return語句,在生成器裡的意思不是「回傳 None」,而是 「停止迭代 (StopIterartion)」。 - 也就是說,當程式跑到
else: return時,它回傳的是一個 「空的 Iterable (長度為 0)」,而不是None。
- 只要函式內有
推薦hahow線上學習python: https://igrape.net/30afN
 ; from sklearn.neighbors import KNeighborsClassifier ; from sklearn.model_selection import train_test_split")
 as c:")
")
![Python提取2D array的一部份資料; import numpy; a[1: , 2:] ; a[1:-1 , 2:-1]](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2022/09/20220906122441_97.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python提取2D array的一部份資料; import numpy; a[1: , 2:] ; a[1:-1 , 2:-1]")
 #Bytes → Element Object 與 lxml.etree.tostring(Element, encoding= “utf-8”) #Element Object → Bytes ; lxml.etree._Element; 處理 XML 時,盡量全程保持 Bytes (二進位) 狀態。")
 ; spyder無法用滑鼠改變3D圖的視角該如何處理? %matplotlib qt")


, import scipy.io ; dic = scipy.io.loadmat(pathf) ; scipy.io.savemat(SavePath, rawdict)")


近期留言